Линия тренда в excel уравнение. Решение задач аппроксимации средствами Excel
Наиболее часто тренд представляется линейной зависимостью исследуемой величины вида
где y – исследуемая переменная (например, производительность) или зависимая переменная;
x – число, определяющее позицию (второй, третий и т.д.) года в периоде прогнозирования или независимая переменная.
При линейной аппроксимации связи между двумя параметрами для нахождения эмпирических коэффициентов линейной функции используется наиболее часто метод наименьших квадратов. Суть метода состоит в том, что линейная функция «наилучшего соответствия» проходит через точки графика, соответствующие минимуму суммы квадратов отклонений измеряемого параметра. Такое условие имеет вид:

где n – объем исследуемой совокупности (число единиц наблюдений).

Рис. 5.3. Построение тренда методом наименьших квадратов
Значения констант b и a или коэффициента при переменной Х и свободного члена уравнения определяются по формуле:

В табл. 5.1 приведен пример вычисления линейного тренда по данным .
Таблица 5.1. Вычисление линейного тренда

Методы сглаживания колебаний.
При сильных расхождениях между соседними значениями тренд, полученный методом регрессии, трудно поддается анализу. При прогнозировании, когда ряд содержит данные с большим разбросом колебаний соседних значений, следует их сгладить по определенным правилам, а потом искать смысл в прогнозе. К методу сглаживания колебаний
относят: метод скользящих средних (рассчитывается n-точечное среднее), метод экспоненциального сглаживания. Рассмотрим их.
Метод «скользящих средних» (МСС).
МСС позволяет сгладить ряд значений с тем, чтобы выделить тренд. При использовании этого метода берется среднее (обычно среднеарифметическое) фиксированного числа значений. Например, трехточечное скользящее среднее. Берется первая тройка значений, составленная из данных за январь, февраль и март (10 + 12 + 13), и определяется среднее, равное 35: 3 = 11,67.
Полученное значение 11,67 ставится в центре диапазона, т.е. по строке февраля. Затем «скользим на один месяц» и берется вторая тройка чисел, начиная с февраля по апрель (12 + 13 + 16), и рассчитывается среднее, равное 41: 3 = 13,67, и таким приемом обрабатываем данные по всему ряду. Полученные средние представляют новый ряд данных для построения тренда и его аппроксимации. Чем больше берется точек для вычисления скользящей средней, тем сильнее происходит сглаживание колебаний. Пример из МВА построения тренда дан в табл. 5.2 и на рис. 5.4.
Таблица 5.2 Расчет тренда методом трехточечного скользящего среднего

Характер колебаний исходных данных и данных, полученных методом скользящего среднего, иллюстрирован на рис. 5.4. Из сравнения графиков рядов исходных значений (ряд 3) и трехточечных скользящих средних (ряд 4), видно, что колебания удается сгладить. Чем большее число точек будет вовлекаться в диапазон вычисления скользящей средней, тем нагляднее будет вырисовываться тренд (ряд 1). Но процедура укрупнения диапазона приводит к сокращению числа конечных значений и это снижает точность прогноза.
Прогнозы следует делать исходя из оценок линии регрессии, составленной по значениям исходных данных или скользящих средних.

Рис. 5.4. Характер изменения объема продаж по месяцам года:
исходные данные (ряд 3); скользящие средние (ряд 4); экспоненциальное сглаживание (ряд 2); тренд, построенный методом регрессии (ряд 1)
Метод экспоненциального сглаживания.
Альтернативный подход к сокращению разброса значений ряда состоит в использовании метода экспоненциального сглаживания. Метод получил название «экспоненциальное сглаживание» в связи с тем, что каждое значение периодов, уходящих в прошлое, уменьшается на множитель (1 – α).
Каждое сглаженное значение рассчитывается по формуле вида:
St =aYt +(1−α)St−1,
где St – текущее сглаженное значение;
Yt – текущее значение временного ряда; St – 1 – предыдущее сглаженное значение; α – сглаживающая константа, 0 ≤ α ≤ 1.
Чем меньше значение константы α , тем менее оно чувствительно к изменениям тренда в данном временном ряду.
Прогнозирование – это очень важный элемент практически любой сферы деятельности, начиная от экономики и заканчивая инженерией. Существует большое количество программного обеспечения, специализирующегося именно на этом направлении. К сожалению, далеко не все пользователи знают, что обычный табличный процессор Excel имеет в своем арсенале инструменты для выполнения прогнозирования, которые по своей эффективности мало чем уступают профессиональным программам. Давайте выясним, что это за инструменты, и как сделать прогноз на практике.
Целью любого прогнозирования является выявление текущей тенденции, и определение предполагаемого результата в отношении изучаемого объекта на определенный момент времени в будущем.
Способ 1: линия тренда
Одним из самых популярных видов графического прогнозирования в Экселе является экстраполяция выполненная построением линии тренда.
Попробуем предсказать сумму прибыли предприятия через 3 года на основе данных по этому показателю за предыдущие 12 лет.

Способ 2: оператор ПРЕДСКАЗ
Экстраполяцию для табличных данных можно произвести через стандартную функцию Эксель ПРЕДСКАЗ . Этот аргумент относится к категории статистических инструментов и имеет следующий синтаксис:
ПРЕДСКАЗ(X;известные_значения_y;известные значения_x)
«X» – это аргумент, значение функции для которого нужно определить. В нашем случае в качестве аргумента будет выступать год, на который следует произвести прогнозирование.
«Известные значения y» — база известных значений функции. В нашем случае в её роли выступает величина прибыли за предыдущие периоды.
«Известные значения x» — это аргументы, которым соответствуют известные значения функции. В их роли у нас выступает нумерация годов, за которые была собрана информация о прибыли предыдущих лет.
Естественно, что в качестве аргумента не обязательно должен выступать временной отрезок. Например, им может являться температура, а значением функции может выступать уровень расширения воды при нагревании.
При вычислении данным способом используется метод линейной регрессии.
Давайте разберем нюансы применения оператора ПРЕДСКАЗ на конкретном примере. Возьмем всю ту же таблицу. Нам нужно будет узнать прогноз прибыли на 2018 год.


Но не стоит забывать, что, как и при построении линии тренда, отрезок времени до прогнозируемого периода не должен превышать 30% от всего срока, за который накапливалась база данных.
Способ 3: оператор ТЕНДЕНЦИЯ
Для прогнозирования можно использовать ещё одну функцию – ТЕНДЕНЦИЯ . Она также относится к категории статистических операторов. Её синтаксис во многом напоминает синтаксис инструмента ПРЕДСКАЗ и выглядит следующим образом:
ТЕНДЕНЦИЯ(Известные значения_y;известные значения_x; новые_значения_x;[конст])
Как видим, аргументы «Известные значения y» и «Известные значения x» полностью соответствуют аналогичным элементам оператора ПРЕДСКАЗ , а аргумент «Новые значения x» соответствует аргументу «X» предыдущего инструмента. Кроме того, у ТЕНДЕНЦИЯ имеется дополнительный аргумент «Константа» , но он не является обязательным и используется только при наличии постоянных факторов.
Данный оператор наиболее эффективно используется при наличии линейной зависимости функции.
Посмотрим, как этот инструмент будет работать все с тем же массивом данных. Чтобы сравнить полученные результаты, точкой прогнозирования определим 2019 год.


Способ 4: оператор РОСТ
Ещё одной функцией, с помощью которой можно производить прогнозирование в Экселе, является оператор РОСТ. Он тоже относится к статистической группе инструментов, но, в отличие от предыдущих, при расчете применяет не метод линейной зависимости, а экспоненциальной. Синтаксис этого инструмента выглядит таким образом:
РОСТ(Известные значения_y;известные значения_x; новые_значения_x;[конст])
Как видим, аргументы у данной функции в точности повторяют аргументы оператора ТЕНДЕНЦИЯ , так что второй раз на их описании останавливаться не будем, а сразу перейдем к применению этого инструмента на практике.


Способ 5: оператор ЛИНЕЙН
Оператор ЛИНЕЙН при вычислении использует метод линейного приближения. Его не стоит путать с методом линейной зависимости, используемым инструментом ТЕНДЕНЦИЯ . Его синтаксис имеет такой вид:
ЛИНЕЙН(Известные значения_y;известные значения_x; новые_значения_x;[конст];[статистика])
Последние два аргумента являются необязательными. С первыми же двумя мы знакомы по предыдущим способам. Но вы, наверное, заметили, что в этой функции отсутствует аргумент, указывающий на новые значения. Дело в том, что данный инструмент определяет только изменение величины выручки за единицу периода, который в нашем случае равен одному году, а вот общий итог нам предстоит подсчитать отдельно, прибавив к последнему фактическому значению прибыли результат вычисления оператора ЛИНЕЙН , умноженный на количество лет.


Как видим, прогнозируемая величина прибыли, рассчитанная методом линейного приближения, в 2019 году составит 4614,9 тыс. рублей.
Способ 6: оператор ЛГРФПРИБЛ
Последний инструмент, который мы рассмотрим, будет ЛГРФПРИБЛ . Этот оператор производит расчеты на основе метода экспоненциального приближения. Его синтаксис имеет следующую структуру:
ЛГРФПРИБЛ (Известные значения_y;известные значения_x; новые_значения_x;[конст];[статистика])
Как видим, все аргументы полностью повторяют соответствующие элементы предыдущей функции. Алгоритм расчета прогноза немного изменится. Функция рассчитает экспоненциальный тренд, который покажет, во сколько раз поменяется сумма выручки за один период, то есть, за год. Нам нужно будет найти разницу в прибыли между последним фактическим периодом и первым плановым, умножить её на число плановых периодов (3) и прибавить к результату сумму последнего фактического периода.


Прогнозируемая сумма прибыли в 2019 году, которая была рассчитана методом экспоненциального приближения, составит 4639,2 тыс. рублей, что опять не сильно отличается от результатов, полученных при вычислении предыдущими способами.
Мы выяснили, какими способами можно произвести прогнозирование в программе Эксель. Графическим путем это можно сделать через применение линии тренда, а аналитическим – используя целый ряд встроенных статистических функций. В результате обработки идентичных данных этими операторами может получиться разный итог. Но это не удивительно, так как все они используют разные методы расчета. Если колебание небольшое, то все эти варианты, применимые к конкретному случаю, можно считать относительно достоверными.
Как поступить в случае, если для определенных объемов/размеров продукции хронометражные замеры отсутствуют? Или число замеров недостаточно, а дополнительные наблюдения в ближайшее время осуществить невозможно? Наилучший способ решения данной проблемы – построение расчетных зависимостей (уравнений регрессии) с помощью линий тренда в MS Excel.
Рассмотрим реальную ситуацию: на складе с целью установления величины трудовых затрат по коробочной отборке заказа были проведены хронометражные наблюдения. Результаты этих наблюдений представлены в таблице 1 ниже.
Впоследствии возникла необходимость определения затрат времени на отборку 0,6 и 0,9 м3 товара/заказа. В связи с невозможностью проведения дополнительных хронометражных исследований затраты времени на отборку данных объемов заказа были рассчитаны с помощью уравнений регрессии в MS Excel. Для этого таблица 1 была преобразована в таблицу 2.

Выбор точечной диаграммы, рис. 1

Следующий шаг: курсор мыши был установлен на одной из точек графика и с помощью правой кнопки мыши было вызвано контекстное меню, в котором был выбран пункт: «добавить линию тренда» (рис.2).
Добавление линии тренда, рис. 2

В появившемся окне настройки формата линии тренда (рис. 3) были последовательно выбраны: тип линии линейная/степенная и установлены флажки на следующие пункты: «показать уравнение на диаграмме» и «поместить на диаграмме величину достоверности аппроксимации (R^2)» (коэффициент детерминации).
Формат линии тренда, рис. 3

В результате были получены графики, представленные на рис. 4 и 5.
Линейная расчетная зависимость, рис. 4

Степенная расчетная зависимость, рис. 5

Наглядный анализ графиков однозначно свидетельствует о близости полученных зависимостей. Кроме того, величина достоверности аппроксимации (R^2), которую также называют коэффициентом детерминации, в случае обеих зависимостей составляет одну и ту же величину 0,97. Известно, что чем ближе коэффициент детерминации к 1, тем больше линия тренда соответствует действительности. Также можно констатировать, что изменение затрат времени на обработку заказа на 97% объясняется изменением количества товара. Поэтому в данном случае не принципиально: какую расчетную зависимость выбрать в качестве основной для последующего расчета временных затрат.
Примем за основную - линейную расчетную зависимость. Тогда значения затрат времени в зависимости от количества товара будут определяться по формуле: y = 54,511x + 0,1489. Результаты этих расчетов для количества товара, по которому ранее были проведены хронометражные наблюдения, представлены в таблице 3 ниже.

Определим среднее отклонение затрат времени, рассчитанных по уравнению регрессии от затрат времени, рассчитанных по данным хронометражных наблюдений: (-0,05+0,10-0,05+0,01)/4=0,0019. Таким образом, затраты времени, рассчитанные по уравнению регрессии отличаются от затрат времени, рассчитанных по данным хронометражных наблюдений всего на 0,19%. Расхождение данных ничтожно мало.
По формуле: y = 54,511x + 0,1489 установим затраты времени для количества товара, по которому ранее не были проведены хронометражные наблюдения (таблица 4).

Таким образом, построение расчетных зависимостей с помощью линий тренда в MS Excel – это отличный способ установления затрат времени по операциям, которые в силу различных причин не были охвачены хронометражными наблюдениями.
Назначение сервиса . Сервис используется для расчета параметров тренда временного ряда y t онлайн с помощью метода наименьших квадратов (МНК) (см. пример нахождения уравнения тренда), а также способом от условного нуля. Для этого строится система уравнений:a 0 n + a 1 ∑t = ∑y
a 0 ∑t + a 1 ∑t 2 = ∑y t
и таблица следующего вида:
| t | y | t 2 | y 2 | t y | y(t) |
| 1 | |||||
| ... | ... | ... | ... | ... | ... |
| N | |||||
| ИТОГО | ∑ | ∑ | ∑ | ∑ | ∑ |
Инструкция . Укажите количество данных (количество строк). Полученное решение сохраняется в файле Word и Excel .
Тенденция временного ряда характеризует совокупность факторов, оказывающих долговременное влияние и формирующих общую динамику изучаемого показателя.
Способ отсчета времени от условного начала
Для определения параметров математической функции при анализе тренда в рядах динамики используется способ отсчета времени от условного начала. Он основан на обозначении в ряду динамики показаний времени таким образом, чтобы ∑t i . При этом в ряду динамики с нечетным числом уровней порядковый номер уровня, находящегося в середине ряда, обозначают через нулевое значение и принимают его за условное начало отсчета времени с интервалом +1 всех последующих уровней и –1 всех предыдущих уровней. Например, при обозначения времени будут: –2, –1, 0, +1, +2 . При четном числе уровней порядковые номера верхней половины ряда (от середины) обозначаются числами: –1, –3, –5 , а нижней половины ряда обозначаются +1, +3, +5 .Пример . Статистическое изучение динамики численности населения.
- С помощью цепных, базисных, средних показателей динамики оцените изменение численности, запишите выводы.
- С помощью метода аналитического выравнивания (по прямой и параболе, определив коэффициенты с помощью МНК) выявите основную тенденцию в развитии явления (численность населения Республики Коми). Оцените качество полученных моделей с помощью ошибок и коэффициентов аппроксимации.
- Определите коэффициенты линейного и параболического трендов с помощью средств «Мастера диаграмм». Дайте точечный и интервальный прогнозы численности на 2010 г. Запишите выводы.
| 1990 | 1996 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 |
| 1249 | 1133 | 1043 | 1030 | 1016 | 1005 | 996 | 985 | 975 | 968 |
а) Линейное уравнение тренда имеет вид y = bt + a
1. Находим параметры уравнения методом наименьших квадратов
. Используем способ отсчета времени от условного начала.
Система уравнений МНК для линейного тренда имеет вид:
a 0 n + a 1 ∑t = ∑y
a 0 ∑t + a 1 ∑t 2 = ∑y t
| t | y | t 2 | y 2 | t y |
| -9 | 1249 | 81 | 1560001 | -11241 |
| -7 | 1133 | 49 | 1283689 | -7931 |
| -5 | 1043 | 25 | 1087849 | -5215 |
| -3 | 1030 | 9 | 1060900 | -3090 |
| -1 | 1016 | 1 | 1032256 | -1016 |
| 1 | 1005 | 1 | 1010025 | 1005 |
| 3 | 996 | 9 | 992016 | 2988 |
| 5 | 985 | 25 | 970225 | 4925 |
| 7 | 975 | 49 | 950625 | 6825 |
| 9 | 968 | 81 | 937024 | 8712 |
| 0 | 10400 | 330 | 10884610 | -4038 |
Для наших данных система уравнений примет вид:
10a 0 + 0a 1 = 10400
0a 0 + 330a 1 = -4038
Из первого уравнения выражаем а 0 и подставим во второе уравнение
Получаем a 0 = -12.236, a 1 = 1040
Уравнение тренда:
y = -12.236 t + 1040
Оценим качество уравнения тренда с помощью ошибки абсолютной аппроксимации.
Ошибка аппроксимации в пределах 5%-7% свидетельствует о хорошем подборе уравнения тренда к исходным данным.
![]()
б) выравнивание по параболе
Уравнение тренда имеет вид y = at 2 + bt + c
1. Находим параметры уравнения методом наименьших квадратов.
Система уравнений МНК:
a 0 n + a 1 ∑t + a 2 ∑t 2 = ∑y
a 0 ∑t + a 1 ∑t 2 + a 2 ∑t 3 = ∑yt
a 0 ∑t 2 + a 1 ∑t 3 + a 2 ∑t 4 = ∑yt 2
| t | y | t 2 | y 2 | t y | t 3 | t 4 | t 2 y |
| -9 | 1249 | 81 | 1560001 | -11241 | -729 | 6561 | 101169 |
| -7 | 1133 | 49 | 1283689 | -7931 | -343 | 2401 | 55517 |
| -5 | 1043 | 25 | 1087849 | -5215 | -125 | 625 | 26075 |
| -3 | 1030 | 9 | 1060900 | -3090 | -27 | 81 | 9270 |
| -1 | 1016 | 1 | 1032256 | -1016 | -1 | 1 | 1016 |
| 1 | 1005 | 1 | 1010025 | 1005 | 1 | 1 | 1005 |
| 3 | 996 | 9 | 992016 | 2988 | 27 | 81 | 8964 |
| 5 | 985 | 25 | 970225 | 4925 | 125 | 625 | 24625 |
| 7 | 975 | 49 | 950625 | 6825 | 343 | 2401 | 47775 |
| 9 | 968 | 81 | 937024 | 8712 | 729 | 6561 | 78408 |
| 0 | 10400 | 330 | 10884610 | -4038 | 0 | 19338 | 353824 |
Для наших данных система уравнений имеет вид
10a 0 + 0a 1 + 330a 2 = 10400
0a 0 + 330a 1 + 0a 2 = -4038
330a 0 + 0a 1 + 19338a 2 = 353824
Получаем a 0 = 1.258, a 1 = -12.236, a 2 = 998.5
Уравнение тренда:
y = 1.258t 2 -12.236t+998.5
Ошибка аппроксимации для параболического уравнения тренда.
![]()
Поскольку ошибка меньше 7%, то данное уравнение можно использовать в качестве тренда.
Минимальная ошибка аппроксимации при выравнивании по параболе. К тому же коэффициент детерминации R 2 выше чем при линейной. Следовательно, для прогнозирования необходимо использовать уравнение по параболе.
Интервальный прогноз.
Определим среднеквадратическую ошибку прогнозируемого показателя.

m = 1 - количество влияющих факторов в уравнении тренда.
Uy = y n+L ± K
где

L - период упреждения; у n+L - точечный прогноз по модели на (n + L)-й момент времени; n - количество наблюдений во временном ряду; Sy - стандартная ошибка прогнозируемого показателя; T табл - табличное значение критерия Стьюдента для уровня значимости α и для числа степеней свободы, равного n-2
.
По таблице Стьюдента находим Tтабл
T табл (n-m-1;α/2) = (8;0.025) = 2.306
Точечный прогноз, t = 10: y(10) = 1.26*10 2 -12.24*10 + 998.5 = 1001.89 тыс. чел.
1001.89 - 71.13 = 930.76 ; 1001.89 + 71.13 = 1073.02
Интервальный прогноз:
t = 9+1 = 10: (930.76;1073.02)
Глядя на любой набор данных распределенных во времени (динамический ряд), мы можем визуально определить падения и подъемы показателей, которые он содержит. Закономерность подъемов и падений называется трендом, который может говорить о том, увеличиваются или уменьшаются наши данные.
Пожалуй, цикл статей о прогнозировании я начну с самого простого — построении функции тренда. Для примера возьмем данные о продажах и построим модель, которая опишет зависимость продаж от времени.
Базовые понятия
Думаю, еще со школы все знакомы с линейной функцией, она как раз и лежит в основе тренда:
Y(t) = a0 + a1*t + E
Y — это объем продаж, та переменная, которую мы будем объяснять временем и от которого она зависит, то есть Y(t);
t — номер периода (порядковый номер месяца), который объясняет план продаж Y;
a0 — это нулевой коэффициент регрессии, который показывает значение Y(t), при отсутствии влияния объясняющего фактора (t=0);
a1 — коэффициент регрессии, который показывает, на сколько исследуемый показатель продаж Y зависит от влияющего фактора t;
E — случайные возмущения, которые отражают влияния других неучтенных в модели факторов, кроме времени t.
Построение модели
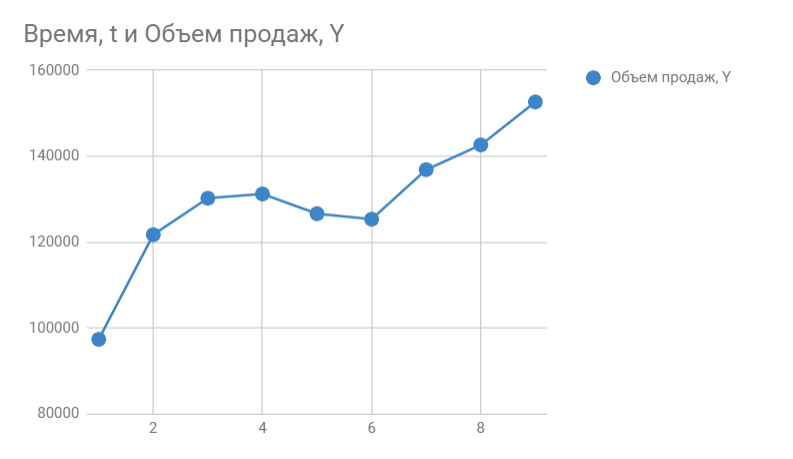
Итак, мы знаем объем продаж за прошедшие 9 месяцев. Вот, что из себя представляет наша табличка:
Следующее, что мы должны сделать — это определить коэффициенты a0 и a1 для прогнозирования объема продаж за 10-ый месяц.
Определение коэффициентов модели
Строим график. По горизонтали видим отложенные месяцы, по вертикали объем продаж:
В Google Sheets выбираем Редактор диаграмм -> Дополнительные и ставим галочку возле Линии тренда . В настройках выбираем Ярлык — Уравнение и Показать R^2 .
Если вы делаете все в MS Excel, то правой кнопкой мыши кликаем на график и в выпадающем меню выбираем «Добавить линию тренда».
По умолчанию строится линейная функция. Справа выбираем «Показывать уравнение на диаграмме» и «Величину достоверности аппроксимации R^2».
Вот, что получилось:

На графике мы видим уравнение функции:
y = 4856*x + 105104
Она описывает объем продаж в зависимости от номера месяца, на который мы хотим эти продажи спрогнозировать. Рядом видим коэффициент детерминации R^2, который говорит о качестве модели и на сколько хорошо она описывает наши продажи (Y). Чем ближе к 1, тем лучше.
У меня R^2 = 0,75. Это средний показатель, он говорит о том, что в модели не учтены какие-то другие значимые факторы помимо времени t, например, это может быть сезонность.
Прогнозируем
y = 4856*10 + 105104
Получаем 153664 продажи в следующем месяце. Если добавим новую точку на график, то сразу видим, что R^2 улучшился.

Таким образом вы можете спрогнозировать данные на несколько месяцев вперед, но без учета других факторов ваш прогноз будет лежать на линии тренда и будет не таким информативным как хотелось бы. К тому же, долгосрочный прогноз, сделанный таким способом будет очень приблизительным.
Повысить точность модели можно добавлением сезонности к функции тренда, что мы и сделаем в следующей статье.