Введение в искусственные нейронные сети. Обучение без учителя
Нейронные сети - класс аналитических методов, построенных на (гипотетических) принципах обучения мыслящим существ и функционированию мозга, которые позволяют прогнозировать значения некоторых сменных в новых наблюдениях на основе результатов других наблюдений (для этих же или других сменных) после прохождения этапа так называемого обучения на имеющихся данных.
Основные понятия о нейронных сетях
Наиболее часто нейронные сети используются для решения следующих задач:
классификация образов - указание на принадлежность входного образа, представленного вектором признаков, одному или нескольким предварительно определенным классам;
кластеризация - классификация образов при отсутствии учебной выборки с метками классов;
прогнозирование - предусмотрение значения y(tn+1) при известной последовательности y(t1), y(t2) ... y(tn);
оптимизация - обнаружение решения, которое удовлетворяет систему ограничений и максимизирует или минимизирует целевую функцию. Память, которая адресуется по смыслу (ассоциативная память) - память, доступная при указании заданного содержания;
управление - расчет такого входного влияния на систему, за который система работает по желательной траектории.
Структурной основой нейронной сети является формальный нейрон. Нейронные сети возникли из попыток воссоздать способность биологических систем учиться, моделируя низкокорневую структуру мозга. Для этого в основу нейросетевой модели ложится элемент, который имитирует в первом приближении свойства биологического нейрона - формальный нейрон(далее просто нейрон). В организме человека нейроны это особые клетки, способны распространять электрохимические сигналы.
Нейрон имеет разветвленную структуру для введения информации (дендриты), ядро и выход, который разветвляется (аксон). Будучи соединенными определенным образом, нейроны образовывают нейронную сеть. Каждый нейрон характеризуется определенным текущим состоянием и имеет группу синапсов - однонаправленных входных связей, соединенных с выходами других нейронов, а также имеет аксон - исходная связь данного нейрона, за которым сигнал (нарушение или торможение) поступает на синапсы следующих нейронов (рис. 8.1).
Рис. 8.1. Структура формального нейрона.
Каждый синапс характеризуется величиной синапсичной связи или его весом wi, что по физическому содержанию эквивалентная электрической проводимости.
Текущее состояние (уровень активации) нейрона определяется, если взвешенная сумма его входов:
![]() (1)
(1)
где множество сигналов, обозначенных x1, x2,..., xn, поступает на вход нейрона, каждый сигнал увеличивается на соответствующий вес w1, w2,...,wn,и формирует уровень его активации - S. Выход нейрона есть функция уровня его активации:
Y=f(S) (2)
При функционировании нейронных сетей выполняется принцип параллельной обработки сигналов. Он достигается путем объединения большого числа нейронов в так называемые пласты и соединения определенным образом нейронов разных пластов, а также, в некоторых конфигурациях, и нейронов одного пласта между собой, причем обработка взаимодействия всех нейронов ведется послойно.
Р ис.
8.2.
Архитектура нейронной сети с n нейронами
во входном и тремя нейронами в исходном
пласте (однослойный персептрон).
ис.
8.2.
Архитектура нейронной сети с n нейронами
во входном и тремя нейронами в исходном
пласте (однослойный персептрон).
В качестве примера простейшей нейронной сети, рассмотрим однослойный перcептрон с n нейронами во входном и тремя нейронами в исходном пласте (рис. 8.2). Когда на n входов поступают какие-то сигналы, они проходят по синапсам на 3 исходные нейрона. Эта система образовывает единый пласт нейронной сети и выдает три исходных сигнала:
Очевидно, что все весовые коэффициенты синапсов одного пласта нейронов можно свести в матрицу wj, каждый элемент которой wij задает величину синапсичной связи i-го нейрона входного и j-го нейрона исходного пласта(3).
 (3)
(3)
Таким образом, процесс, который происходит в нейронной сети, может быть записан в матричной форме:
где x и y - соответственно входной и исходный векторы, f(v) - активационная функция, которая применяется поэлементно к компонентам вектора v.
Выбор структуры нейронной сети осуществляется согласно особенностям и сложности задачи. Для решения некоторых отдельных типов задач уже существуют оптимальные конфигурации. Если же задача не может быть сведена ни к одному из известных типов, разработчику приходится решать сложную проблему синтеза новой конфигурации.
Возможная такая классификация существующих нейросетей:
По типу входной информации:
сети, которые анализируют двоичную информацию;
сети, которые оперируют с действительными числами.
По методу обучения:
сети, которые необходимо научить перед их применением;
сети, которые не нуждаются в предыдущем обучении, способны обучаться самостоятельно в процессе работы.
По характеру распространения информации:
однонаправленные, в которых информация распространяется только в одном направлении от одного пласта к другому;
рекурентные сети, в которых исходный сигнал элемента может снова поступать на этот элемент и другие элементы сети этого или предыдущего пласта как входной сигнал.
По способу преобразования входной информации:
автоассоциативные;
гетероассоциативные.
Развивая дальше вопрос о возможной классификации нейронных сетей, важно отметить существования бинарных и аналоговых сетей. Первые оперируют с двоичными сигналами, и выход каждого нейрона может принимать только два значения: логический нуль ("приостановленное" состояние) и логическая единица ("возбужденное" состояние). Еще одна классификация разделяет нейронные сети на синхронные и асинхронные. В первом случае в каждый момент времени свое состояние изменяет лишь один нейрон. Во второму - состояние изменяется сразу у целой группы нейронов, как правило, во всем пласте.
Сети также можно классифицировать по количеству пластов. На рис. 8.3 представлен двухслойный персептрон, полученный из персептрона на рис. 8.2 путем добавления второго пласта, который состоит из двух нейронов.
Р ис.
8.3. Архитектура нейронной сети с
однонаправленным распространением
сигнала – двухслойный персептрон.
ис.
8.3. Архитектура нейронной сети с
однонаправленным распространением
сигнала – двухслойный персептрон.
Если рассматривать работу нейронных сетей, которые решают задачу классификации образов, то вообще их работа сводится к классификации (обобщения) входных сигналов, которые принадлежат n-мерному гиперпространству, по некоторому числу классов. С математической точки зрения это происходит путем разбивки гиперпространства гиперплоскостями (запись для случая однослойного персептрона)
![]() ,
(5),
,
(5),
где k=1...m – номер класса.
Каждая полученная область является областью определения отдельного класса. Число таких классов для одной нейронной сети персептронного типа не превышает 2m, где m - число выходов сети. Однако не все из них могут быть распределены данной нейронной сетью.
Искусственная нейронная сеть — совокупность нейронов, взаимодействующих друг с другом. Они способны принимать, обрабатывать и создавать данные. Это настолько же сложно представить, как и работу человеческого мозга. Нейронная сеть в нашем мозгу работает для того, чтобы вы сейчас могли это прочитать: наши нейроны распознают буквы и складывают их в слова.
Искусственная нейронная сеть - это подобие мозга. Изначально она программировалась с целью упростить некоторые сложные вычислительные процессы. Сегодня у нейросетей намного больше возможностей. Часть из них находится у вас в смартфоне. Ещё часть уже записала себе в базу, что вы открыли эту статью. Как всё это происходит и для чего, читайте далее.
С чего всё началось
Людям очень хотелось понять, откуда у человека разум и как работает мозг. В середине прошлого века канадский нейропсихолог Дональд Хебб это понял. Хебб изучил взаимодействие нейронов друг с другом, исследовал, по какому принципу они объединяются в группы (по-научному - ансамбли) и предложил первый в науке алгоритм обучения нейронных сетей.
Спустя несколько лет группа американских учёных смоделировала искусственную нейросеть, которая могла отличать фигуры квадратов от остальных фигур.
Как же работает нейросеть?
Исследователи выяснили, нейронная сеть - это совокупность слоёв нейронов, каждый из которых отвечает за распознавание конкретного критерия: формы, цвета, размера, текстуры, звука, громкости и т. д. Год от года в результате миллионов экспериментов и тонн вычислений к простейшей сети добавлялись новые и новые слои нейронов. Они работают по очереди. Например, первый определяет, квадрат или не квадрат, второй понимает, квадрат красный или нет, третий вычисляет размер квадрата и так далее. Не квадраты, не красные и неподходящего размера фигуры попадают в новые группы нейронов и исследуются ими.
Какими бывают нейронные сети и что они умеют
Учёные развили нейронные сети так, что те научились различать сложные изображения, видео, тексты и речь. Типов нейронных сетей сегодня очень много. Они классифицируются в зависимости от архитектуры - наборов параметров данных и веса этих параметров, некой приоритетности. Ниже некоторые из них.
Свёрточные нейросети
Нейроны делятся на группы, каждая группа вычисляет заданную ей характеристику. В 1993 году французский учёный Ян Лекун показал миру LeNet 1 - первую свёрточную нейронную сеть, которая быстро и точно могла распознавать цифры, написанные на бумаге от руки. Смотрите сами:
Сегодня свёрточные нейронные сети используются в основном с мультимедиными целями: они работают с графикой, аудио и видео.
Рекуррентные нейросети
Нейроны последовательно запоминают информацию и строят дальнейшие действия на основе этих данных. В 1997 году немецкие учёные модифицировали простейшие рекуррентные сети до сетей с долгой краткосрочной памятью. На их основе затем были разработаны сети с управляемыми рекуррентными нейронами.
Сегодня с помощью таких сетей пишутся и переводятся тексты, программируются боты, которые ведут осмысленные диалоги с человеком, создаются коды страниц и программ.
Использование такого рода нейросетей - это возможность анализировать и генерировать данные, составлять базы и даже делать прогнозы.
В 2015 году компания SwiftKey выпустила первую в мире клавиатуру, работающую на рекуррентной нейросети с управляемыми нейронами. Тогда система выдавала подсказки в процессе набранного текста на основе последних введённых слов. В прошлом году разработчики обучили нейросеть изучать контекст набираемого текста, и подсказки стали осмысленными и полезными:

Комбинированные нейросети (свёрточные + рекуррентные)
Такие нейронные сети способны понимать, что находится на изображении, и описывать это. И наоборот: рисовать изображения по описанию. Ярчайший пример продемонстрировал Кайл Макдональд, взяв нейронную сеть на прогулку по Амстердаму. Сеть мгновенно определяла, что находится перед ней. И практически всегда точно:

Нейросети постоянно самообучаются. Благодаря этому процессу:
1. Skype внедрил возможность синхронного перевода уже для 10 языков. Среди которых, на минуточку, есть русский и японский - одни из самых сложных в мире. Конечно, качество перевода требует серьёзной доработки, но сам факт того, что уже сейчас вы можете общаться с коллегами из Японии по-русски и быть уверенными, что вас поймут, вдохновляет.
2. Яндекс на базе нейронных сетей создал два поисковых алгоритма: «Палех» и «Королёв». Первый помогал найти максимально релевантные сайты для низкочастотных запросов. «Палех» изучал заголовки страниц и сопоставлял их смысл со смыслом запросов. На основе «Палеха» появился «Королёв». Этот алгоритм оценивает не только заголовок, но и весь текстовый контент страницы. Поиск становится всё точнее, а владельцы сайтов разумнее начинают подходить к наполнению страниц.
3. Коллеги сеошников из Яндекса создали музыкальную нейросеть: она сочиняет стихи и пишет музыку. Нейрогруппа символично называется Neurona, и у неё уже есть первый альбом:

4. У Google Inbox с помощью нейросетей осуществляется ответ на сообщение. Развитие технологий идет полный ходом, и сегодня сеть уже изучает переписку и генерирует возможные варианты ответа. Можно не тратить время на печать и не бояться забыть какую-нибудь важную договорённость.

5. YouTube использует нейронные сети для ранжирования роликов, причём сразу по двум принципам: одна нейронная сеть изучает ролики и реакции аудитории на них, другая проводит исследование пользователей и их предпочтений. Именно поэтому рекомендации YouTube всегда в тему.
6. Facebook активно работает над DeepText AI - программой для коммуникаций, которая понимает жаргон и чистит чатики от обсценной лексики.
7. Приложения вроде Prisma и Fabby, созданные на нейросетях, создают изображения и видео:

Colorize восстанавливает цвета на чёрно-белых фото (удивите бабушку!).

MakeUp Plus подбирает для девушек идеальную помаду из реального ассортимента реальных брендов: Bobbi Brown, Clinique, Lancome и YSL уже в деле.

8.
Apple и Microsoft постоянно апгрейдят свои нейронные Siri и Contana. Пока они только исполняют наши приказы, но уже в ближайшем будущем начнут проявлять инициативу: давать рекомендации и предугадывать наши желания.
А что ещё нас ждет в будущем?
Самообучающиеся нейросети могут заменить людей: начнут с копирайтеров и корректоров. Уже сейчас роботы создают тексты со смыслом и без ошибок. И делают это значительно быстрее людей. Продолжат с сотрудниками кол-центров, техподдержки, модераторами и администраторами пабликов в соцсетях. Нейронные сети уже умеют учить скрипт и воспроизводить его голосом. А что в других сферах?
Аграрный сектор
Нейросеть внедрят в спецтехнику. Комбайны будут автопилотироваться, сканировать растения и изучать почву, передавая данные нейросети. Она будет решать - полить, удобрить или опрыскать от вредителей. Вместо пары десятков рабочих понадобятся от силы два специалиста: контролирующий и технический.
Медицина
В Microsoft сейчас активно работают над созданием лекарства от рака. Учёные занимаются биопрограммированием - пытаются оцифрить процесс возникновения и развития опухолей. Когда всё получится, программисты смогут найти способ заблокировать такой процесс, по аналогии будет создано лекарство.
Маркетинг
Маркетинг максимально персонализируется. Уже сейчас нейросети за секунды могут определить, какому пользователю, какой контент и по какой цене показать. В дальнейшем участие маркетолога в процессе сведётся к минимуму: нейросети будут предсказывать запросы на основе данных о поведении пользователя, сканировать рынок и выдавать наиболее подходящие предложения к тому моменту, как только человек задумается о покупке.
Ecommerce
Ecommerce будет внедрён повсеместно. Уже не потребуется переходить в интернет-магазин по ссылке: вы сможете купить всё там, где видите, в один клик. Например, читаете вы эту статью через несколько лет. Очень вам нравится помада на скрине из приложения MakeUp Plus (см. выше). Вы кликаете на неё и попадаете сразу в корзину. Или смотрите видео про последнюю модель Hololens (очки смешанной реальности) и тут же оформляете заказ прямо из YouTube.
Едва ли не в каждой области будут цениться специалисты со знанием или хотя бы пониманием устройства нейросетей, машинного обучения и систем искусственного интеллекта. Мы будем существовать с роботами бок о бок. И чем больше мы о них знаем, тем спокойнее нам будет жить.
P. S.
Зинаида Фолс - нейронная сеть Яндекса, пишущая стихи. Оцените произведение, которое машина написала, обучившись на Маяковском (орфография и пунктуация сохранены):
« Это »
это
всего навсего
что-то
в будущем
и мощь
у того человека
есть на свете все или нет
это кровьа вокруг
по рукам
жиреет
слава у
земли
с треском в клюве
Впечатляет, правда?
Решение задачи классификации является одним из важнейших применений нейронных сетей.
Задача классификации представляет собой задачу отнесения образца к одному из нескольких попарно не пересекающихся множеств. Примером таких задач может быть, например, задача определения кредитоспособности клиента банка, медицинские задачи, в которых необходимо определить, например, исход заболевания, решение задач управления портфелем ценных бумаг (продать купить или "придержать" акции в зависимости от ситуации на рынке), задача определения жизнеспособных и склонных к банкротству фирм.
Цель классификации
При решении задач классификации необходимо отнести имеющиеся статические образцы (характеристики ситуации на рынке, данные медосмотра, информация о клиенте) к определенным классам. Возможно несколько способов представления данных. Наиболее распространенным является способ, при котором образец представляется вектором. Компоненты этого вектора представляют собой различные характеристики образца, которые влияют на принятие решения о том, к какому классу можно отнести данный образец. Например, для медицинских задач в качестве компонентов этого вектора могут быть данные из медицинской карты больного. Таким образом, на основании некоторой информации о примере, необходимо определить, к какому классу его можно отнести. Классификатор таким образом относит объект к одному из классов в соответствии с определенным разбиением N-мерного пространства, которое называется пространством входов, и размерность этого пространства является количеством компонент вектора.
Прежде всего, нужно определить уровень сложности системы. В реальных задачах часто возникает ситуация, когда количество образцов ограничено, что осложняет определение сложности задачи. Возможно выделить три основных уровня сложности. Первый (самый простой) – когда классы можно разделить прямыми линиями (или гиперплоскостями, если пространство входов имеет размерность больше двух) – так называемая линейная разделимость . Во втором случае классы невозможно разделить линиями (плоскостями), но их возможно отделить с помощью более сложного деления – нелинейная разделимость . В третьем случае классы пересекаются и можно говорить только о вероятностной разделимости .
В идеальном варианте после предварительной обработки мы должны получить линейно разделимую задачу, так как после этого значительно упрощается построение классификатора. К сожалению, при решении реальных задач мы имеем ограниченное количество образцов, на основании которых и производится построение классификатора. При этом мы не можем провести такую предобработку данных, при которой будет достигнута линейная разделимость образцов.
Использование нейронных сетей в качестве классификатора
Сети с прямой связью являются универсальным средством аппроксимации функций, что позволяет их использовать в решении задач классификации. Как правило, нейронные сети оказываются наиболее эффективным способом классификации, потому что генерируют фактически большое число регрессионных моделей (которые используются в решении задач классификации статистическими методами).
К сожалению, в применении нейронных сетей в практических задачах возникает ряд проблем. Во-первых, заранее не известно, какой сложности (размера) может потребоваться сеть для достаточно точной реализации отображения. Эта сложность может оказаться чрезмерно высокой, что потребует сложной архитектуры сетей. Так Минский в своей работе "Персептроны" доказал, что простейшие однослойные нейронные сети способны решать только линейно разделимые задачи. Это ограничение преодолимо при использовании многослойных нейронных сетей. В общем виде можно сказать, что в сети с одним скрытым слоем вектор, соответствующий входному образцу, преобразуется скрытым слоем в некоторое новое пространство, которое может иметь другую размерность, а затем гиперплоскости, соответствующие нейронам выходного слоя, разделяют его на классы. Таким образом сеть распознает не только характеристики исходных данных, но и "характеристики характеристик", сформированные скрытым слоем.
Подготовка исходных данных
Для построения классификатора необходимо определить, какие параметры влияют на принятие решения о том, к какому классу принадлежит образец. При этом могут возникнуть две проблемы. Во-первых, если количество параметров мало, то может возникнуть ситуация, при которой один и тот же набор исходных данных соответствует примерам, находящимся в разных классах. Тогда невозможно обучить нейронную сеть, и система не будет корректно работать (невозможно найти минимум, который соответствует такому набору исходных данных). Исходные данные обязательно должны быть непротиворечивы . Для решения этой проблемы необходимо увеличить размерность пространства признаков (количество компонент входного вектора, соответствующего образцу). Но при увеличении размерности пространства признаков может возникнуть ситуация, когда число примеров может стать недостаточным для обучения сети, и она вместо обобщения просто запомнит примеры из обучающей выборки и не сможет корректно функционировать. Таким образом, при определении признаков необходимо найти компромисс с их количеством.
Далее необходимо определить способ представления входных данных для нейронной сети, т.е. определить способ нормирования. Нормировка необходима, поскольку нейронные сети работают с данными, представленными числами в диапазоне 0..1, а исходные данные могут иметь произвольный диапазон или вообще быть нечисловыми данными. При этом возможны различные способы, начиная от простого линейного преобразования в требуемый диапазон и заканчивая многомерным анализом параметров и нелинейной нормировкой в зависимости от влияния параметров друг на друга.
Кодирование выходных значений
Задача классификации при наличии двух классов может быть решена на сети с одним нейроном в выходном слое, который может принимать одно из двух значений 0 или 1, в зависимости от того, к какому классу принадлежит образец. При наличии нескольких классов возникает проблема, связанная с представлением этих данных для выхода сети. Наиболее простым способом представления выходных данных в таком случае является вектор, компоненты которого соответствуют различным номерам классов. При этом i-я компонента вектора соответствует i-му классу. Все остальные компоненты при этом устанавливаются в 0. Тогда, например, второму классу будет соответствовать 1 на 2 выходе сети и 0 на остальных. При интерпретации результата обычно считается, что номер класса определяется номером выхода сети, на котором появилось максимальное значение. Например, если в сети с тремя выходами мы имеем вектор выходных значений (0.2,0.6,0.4), то мы видим, что максимальное значение имеет вторая компонента вектора, значит класс, к которому относится этот пример, – 2. При таком способе кодирования иногда вводится также понятие уверенности сети в том, что пример относится к этому классу. Наиболее простой способ определения уверенности заключается в определении разности между максимальным значением выхода и значением другого выхода, которое является ближайшим к максимальному. Например, для рассмотренного выше примера уверенность сети в том, что пример относится ко второму классу, определится как разность между второй и третьей компонентой вектора и равна 0.6-0.4=0.2. Соответственно чем выше уверенность, тем больше вероятность того, что сеть дала правильный ответ. Этот метод кодирования является самым простым, но не всегда самым оптимальным способом представления данных.
Известны и другие способы. Например, выходной вектор представляет собой номер кластера, записанный в двоичной форме. Тогда при наличии 8 классов нам потребуется вектор из 3 элементов, и, скажем, 3 классу будет соответствовать вектор 011. Но при этом в случае получения неверного значения на одном из выходов мы можем получить неверную классификацию (неверный номер кластера), поэтому имеет смысл увеличить расстояние между двумя кластерами за счет использования кодирования выхода по коду Хемминга, который повысит надежность классификации.
Другой подход состоит в разбиении задачи с k классами на k*(k-1)/2 подзадач с двумя классами (2 на 2 кодирование) каждая. Под подзадачей в данном случае понимается то, что сеть определяет наличие одной из компонент вектора. Т.е. исходный вектор разбивается на группы по два компонента в каждой таким образом, чтобы в них вошли все возможные комбинации компонент выходного вектора. Число этих групп можно определить как количество неупорядоченных выборок по два из исходных компонент. Из комбинаторики
$A_k^n = \frac{k!}{n!\,(k\,-\,n)!} = \frac{k!}{2!\,(k\,-\,2)!} = \frac{k\,(k\,-\,1)}{2}$
Тогда, например, для задачи с четырьмя классами мы имеем 6 выходов (подзадач) распределенных следующим образом:
| N подзадачи(выхода) | КомпонентыВыхода |
|---|---|
| 1 | 1-2 |
| 2 | 1-3 |
| 3 | 1-4 |
| 4 | 2-3 |
| 5 | 2-4 |
| 6 | 3-4 |
Где 1 на выходе говорит о наличии одной из компонент. Тогда мы можем перейти к номеру класса по результату расчета сетью следующим образом: определяем, какие комбинации получили единичное (точнее близкое к единице) значение выхода (т.е. какие подзадачи у нас активировались), и считаем, что номер класса будет тот, который вошел в наибольшее количество активированных подзадач (см. таблицу).
Это кодирование во многих задачах дает лучший результат, чем классический способ кодирование.
Выбор объема сети
Правильный выбор объема сети имеет большое значение. Построить небольшую и качественную модель часто бывает просто невозможно, а большая модель будет просто запоминать примеры из обучающей выборки и не производить аппроксимацию, что, естественно, приведет к некорректной работе классификатора. Существуют два основных подхода к построению сети – конструктивный и деструктивный. При первом из них вначале берется сеть минимального размера, и постепенно увеличивают ее до достижения требуемой точности. При этом на каждом шаге ее заново обучают. Также существует так называемый метод каскадной корреляции, при котором после окончания эпохи происходит корректировка архитектуры сети с целью минимизации ошибки. При деструктивном подходе вначале берется сеть завышенного объема, и затем из нее удаляются узлы и связи, мало влияющие на решение. При этом полезно помнить следующее правило: число примеров в обучающем множестве должно быть больше числа настраиваемых весов . Иначе вместо обобщения сеть просто запомнит данные и утратит способность к классификации – результат будет неопределен для примеров, которые не вошли в обучающую выборку.
Выбор архитектуры сети
При выборе архитектуры сети обычно опробуется несколько конфигураций с различным количеством элементов. При этом основным показателем является объем обучающего множества и обобщающая способность сети. Обычно используется алгоритм обучения Back Propagation (обратного распространения) с подтверждающим множеством.
Алгоритм построения классификатора на основе нейронных сетей
- Работа с данными
- Составить базу данных из примеров, характерных для данной задачи
- Разбить всю совокупность данных на два множества: обучающее и тестовое (возможно разбиение на 3 множества: обучающее, тестовое и подтверждающее).
- Предварительная обработка
- Выбрать систему признаков, характерных для данной задачи, и преобразовать данные соответствующим образом для подачи на вход сети (нормировка, стандартизация и т.д.). В результате желательно получить линейно отделяемое пространство множества образцов.
- Выбрать систему кодирования выходных значений (классическое кодирование, 2 на 2 кодирование и т.д.)
- Конструирование, обучение и оценка качества сети
- Выбрать топологию сети: количество слоев, число нейронов в слоях и т.д.
- Выбрать функцию активации нейронов (например "сигмоида")
- Выбрать алгоритм обучения сети
- Оценить качество работы сети на основе подтверждающего множества или другому критерию, оптимизировать архитектуру (уменьшение весов, прореживание пространства признаков)
- Остановится на варианте сети, который обеспечивает наилучшую способность к обобщению и оценить качество работы по тестовому множеству
- Использование и диагностика
- Выяснить степень влияния различных факторов на принимаемое решение (эвристический подход).
- Убедится, что сеть дает требуемую точность классификации (число неправильно распознанных примеров мало)
- При необходимости вернутся на этап 2, изменив способ представления образцов или изменив базу данных.
- Практически использовать сеть для решения задачи.
Для того, чтобы построить качественный классификатор, необходимо иметь качественные данные. Никакой из методов построения классификаторов, основанный на нейронных сетях или статистический, никогда не даст классификатор нужного качества, если имеющийся набор примеров не будет достаточно полным и представительным для той задачи, с которой придется работать системе.
В наши дни возрастает необходимость в системах, которые способны не только выполнять однажды запрограммированную последовательность действий над заранее определенными данными, но и способны сами анализировать вновь поступающую информацию, находить в ней закономерности, производить прогнозирование и т.д. В этой области приложений самым лучшим образом зарекомендовали себя так называемые нейронные сети – самообучающиеся системы, имитирующие деятельность человеческого мозга. Рассмотрим подробнее структуру искусственных нейронных сетей (НС) и их применение в конкретных задачах.
Искусственный нейрон
Несмотря на большое разнообразие вариантов нейронных сетей, все они имеют общие черты. Так, все они, так же, как и мозг человека, состоят из большого числа связанных между собой однотипных элементов – нейронов , которые имитируют нейроны головного мозга. На рис. 1 показана схема нейрона.
Из рисунка видно, что искусственный нейрон, так же, как и живой, состоит из синапсов, связывающих входы нейрона с ядром; ядра нейрона, которое осуществляет обработку входных сигналов и аксона, который связывает нейрон с нейронами следующего слоя. Каждый синапс имеет вес, который определяет, насколько соответствующий вход нейрона влияет на его состояние. Состояние нейрона определяется по формуле
$S =\sum \limits_{i=1}^{n} \,x_iw_i$, (1)
$\sum \limits_{k=1}^{N} k^2$, (1)
n – число входов нейрона
x i – значение i-го входа нейрона
w i – вес i-го синапса.
Затем определяется значение аксона нейрона по формуле
$Y = f\,(S)$, (2)
Где f – некоторая функция, которая называется активационной . Наиболее часто в качестве активационной функции используется так называемый сигмоид , который имеет следующий вид:
$f\,(x) = \frac{1}{1\,+\,\mbox e^{-ax}}$, (3)
Основное достоинство этой функции в том, что она дифференцируема на всей оси абсцисс и имеет очень простую производную:
$f"\,(x) = \alpha f(x)\,\bigl(1\,-\,f\,(x)\bigr)$, (4)
При уменьшении параметра a сигмоид становится более пологим, вырождаясь в горизонтальную линию на уровне 0,5 при a=0. При увеличении a сигмоид все больше приближается к функции единичного скачка.

Нейронные сети обратного распространения
Нейронные сети обратного распространения – это мощнейший инструмент поиска закономерностей, прогнозирования, качественного анализа. Такое название – сети обратного распространения (back propagation) они получили из-за используемого алгоритма обучения, в котором ошибка распространяется от выходного слоя к входному, т. е. в направлении, противоположном направлению распространения сигнала при нормальном функционировании сети.
Нейронная сеть обратного распространения состоит из нескольких слоев нейронов, причем каждый нейрон слоя i связан с каждым нейроном слоя i+1 , т. е. речь идет о полносвязной НС.
В общем случае задача обучения НС сводится к нахождению некой функциональной зависимости Y=F(X) где X – входной, а Y – выходной векторы. В общем случае такая задача, при ограниченном наборе входных данных, имеет бесконечное множество решений. Для ограничения пространства поиска при обучении ставится задача минимизации целевой функции ошибки НС, которая находится по методу наименьших квадратов:
$E\,(w) = \frac{1}{2}\sum \limits_{j=1}^{p} \, {(y_i\,-\,d_i)}^2$, (5)
y j – значение j-го выхода нейросети,
d j – целевое значение j-го выхода,
p – число нейронов в выходном слое.
Обучение нейросети производится методом градиентного спуска, т. е. на каждой итерации изменение веса производится по формуле:
$\Delta\,w_{ij} = -\,\eta\,\cdot\,\frac{\partial\,E}{\partial\,w_{ij}}$, (6)
где h – параметр, определяющий скорость обучения.
$\frac{\partial\,E}{\partial\,w_{ij}} = \frac{\partial\,E}{\partial\,y_i}\,\cdot\,\frac{dy_i}{dS_j}\,\cdot\,\frac{\partial\,S_j}{\partial\,w_{ij}}$, (7)
y j – значение выхода j-го нейрона,
S j – взвешенная сумма входных сигналов, определяемая по формуле (1).
При этом множитель
$\frac{\partial\,S_j}{\partial\,w_{ij}} = x_i$, (8)
x i – значение i-го входа нейрона.
$\frac{\partial\,E}{\partial\,y_j} = \sum \limits_{k}^{} \frac{\partial\,E}{\partial\,y_k}\,\cdot\,\frac{dy_k}{dS_k}\,\cdot\,\frac{\partial\,S_k}{\partial\,y_j} = \sum \limits_{k}^{} \frac{\partial\,E}{\partial\,y_k}\,\cdot\,\frac{dy_k}{dS_k}\,\cdot\,w_{jk}^{(n+1)}$, (9)
k – число нейронов в слое n+1 .
Введем вспомогательную переменную
$\delta_j^{(n)}= \frac{\partial\,E}{\partial\,y_j}\,\cdot\,\frac{dy_j}{dS_j}$, (10)
Тогда мы сможем определить рекурсивную формулу для определения n -ного слоя, если нам известно следующего (n+1) -го слоя.
$\delta_j^{(n)}= \biggl[ \sum \limits_{k}^{} \delta_k^{(n+1)}\,\cdot\,w_{jk}^{(n+1)}\biggr]\,\cdot\,\frac{dy_j}{dS_j}$, (11)
Нахождение же для последнего слоя НС не представляет трудности, так как нам известен целевой вектор, т. е. вектор тех значений, которые должна выдавать НС при данном наборе входных значений.
$\delta_j^{(N)}= \bigl(y_i^{(N)}-\,d_i\bigr)\,\cdot\,\frac{dy_j}{dS_j}$, (12)
И наконец запишем формулу (6) в раскрытом виде
$\Delta w_{ij}^{(n)}= -\,\eta\,\cdot\,\delta_j^{(n)}\,\cdot\,x_i^n$, (13)
Рассмотрим теперь полный алгоритм обучения нейросети:
- подать на вход НС один из требуемых образов и определить значения выходов нейронов нейросети
- рассчитать для выходного слоя НС по формуле (12) и рассчитать изменения весов выходного слоя N по формуле (13)
- Рассчитать по формулам (11) и (13) соответственно и $\Delta w_{ij}^{(N)}$ для остальных слоев НС, n = N-1..1
- Скорректировать все веса НС
$w_{ij}^{(n)}\,(t) = w_{ij}^{(n)}\,(t\,-\,1) \,+\,\Delta w_{ij}^{(n)}\,(t)$, (14)
- Если ошибка существенна, то перейти на шаг 1
На этапе 2 сети поочередно в случайном порядке предъявляются вектора из обучающей последовательности.
Повышение эффективности обучения НС обратного распространения
Простейший метод градиентного спуска, рассмотренный выше, очень неэффективен в случае, когда производные по различным весам сильно отличаются. Это соответствует ситуации, когда значение функции S для некоторых нейронов близка по модулю к 1 или когда модуль некоторых весов много больше 1. В этом случае для плавного уменьшения ошибки надо выбирать очень маленькую скорость обучения, но при этом обучение может занять непозволительно много времени.
Простейшим методом усовершенствования градиентного спуска является введение момента m , когда влияние градиента на изменение весов изменяется со временем. Тогда формула (13) примет вид
$\Delta w_{ij}^{(n)}\,(t) = -\,\eta\,\cdot\,\delta_j^{(n)}\,\cdot\,x_i^n\,+\,\mu\,\Delta w_{ij}^{(n)}\,(t\,-\,1)$ , (13.1)
Дополнительным преимуществом от введения момента является способность алгоритма преодолевать мелкие локальные минимумы.
Представление входных данных
Основное отличие НС в том, что в них все входные и выходные параметры представлены в виде чисел с плавающей точкой обычно в диапазоне . В то же время данные предметной области часто имеют другое кодирование. Так, это могут быть числа в произвольном диапазоне, даты, символьные строки. Таким образом данные о проблеме могут быть как количественными, так и качественными. Рассмотрим сначала преобразование качественных данных в числовые, а затем рассмотрим способ преобразования входных данных в требуемый диапазон.
Качественные данные мы можем разделить на две группы: упорядоченные (ординальные) и неупорядоченные. Для рассмотрения способов кодирования этих данных мы рассмотрим задачу о прогнозировании успешности лечения какого-либо заболевания. Примером упорядоченных данных могут, например, являться данные, например, о дополнительных факторах риска при данном заболевании.
А также возможным примером может быть, например, возраст больного:
Опасность каждого фактора возрастает в таблицах при движении слева направо.
В первом случае мы видим, что у больного может быть несколько факторов риска одновременно. В таком случае нам необходимо использовать такое кодирование, при котором отсутствует ситуация, когда разным комбинациям факторов соответствует одно и то же значение. Наиболее распространен способ кодирования, когда каждому фактору ставится в соответствие разряд двоичного числа. 1 в этом разряде говорит о наличии фактора, а 0 о его отсутствии. Параметру нет можно поставить в соответствии число 0. Таким образом для представления всех факторов достаточно 4-х разрядного двоичного числа. Таким образом число 1010 2 = 10 10 означает наличие у больного гипертонии и употребления алкоголя, а числу 0000 2 соответствует отсутствие у больного факторов риска. Таким образом факторы риска будут представлены числами в диапазоне .
Во втором случае мы также можем кодировать все значения двоичными весами, но это будет нецелесообразно, т.к. набор возможных значений будет слишком неравномерным. В этом случае более правильным будет установка в соответствие каждому значению своего веса, отличающегося на 1 от веса соседнего значения. Так, число 3 будет соответствовать возрасту 50-59 лет. Таким образом возраст будет закодирован числами в диапазоне .
В принципе аналогично можно поступать и для неупорядоченных данных, поставив в соответствие каждому значению какое-либо число. Однако это вводит нежелательную упорядоченность, которая может исказить данные, и сильно затруднить процесс обучения. В качестве одного из способов решения этой проблемы можно предложить поставить в соответствие каждому значению одного из входов НС. В этом случае при наличии этого значения соответствующий ему вход устанавливается в 1 или в 0 при противном случае. К сожалению, данный способ не является панацеей, ибо при большом количестве вариантов входного значения число входов НС разрастается до огромного количества. Это резко увеличит затраты времени на обучение. В качестве варианта обхода этой проблемы можно использовать несколько другое решение. В соответствие каждому значению входного параметра ставится бинарный вектор, каждый разряд которого соответствует отдельному входу НС.
Литература
- Dirk Emma Baestaens, Willem Max Van Den Bergh, Douglas Wood, "Neural Network Solution for Trading in Financial Markets", Pitman publishing
- R. M. Hristev, "Artifical Neural Networks"
- С. Короткий, "Нейронные сети: Алгоритм обратного распространения"
- С. Короткий, "Нейронные сети: Основные положения"
Что такое нейронная сеть?

Нейронная сеть - это последовательность нейронов, соединенных между собой синапсами. Структура нейронной сети пришла в мир программирования прямиком из биологии. Благодаря такой структуре, машина обретает способность анализировать и даже запоминать различную информацию. Нейронные сети также способны не только анализировать входящую информацию, но и воспроизводить ее из своей памяти. Заинтересовавшимся обязательно к просмотру 2 видео из TED Talks: Видео 1 , Видео 2). Другими словами, нейросеть это машинная интерпретация мозга человека, в котором находятся миллионы нейронов передающих информацию в виде электрических импульсов.
Какие бывают нейронные сети?
Пока что мы будем рассматривать примеры на самом базовом типе нейронных сетей - это сеть прямого распространения (далее СПР). Также в последующих статьях я введу больше понятий и расскажу вам о рекуррентных нейронных сетях. СПР как вытекает из названия это сеть с последовательным соединением нейронных слоев, в ней информация всегда идет только в одном направлении.Для чего нужны нейронные сети?
Нейронные сети используются для решения сложных задач, которые требуют аналитических вычислений подобных тем, что делает человеческий мозг. Самыми распространенными применениями нейронных сетей является:Классификация - распределение данных по параметрам. Например, на вход дается набор людей и нужно решить, кому из них давать кредит, а кому нет. Эту работу может сделать нейронная сеть, анализируя такую информацию как: возраст, платежеспособность, кредитная история и тд.
Предсказание - возможность предсказывать следующий шаг. Например, рост или падение акций, основываясь на ситуации на фондовом рынке.
Распознавание - в настоящее время, самое широкое применение нейронных сетей. Используется в Google, когда вы ищете фото или в камерах телефонов, когда оно определяет положение вашего лица и выделяет его и многое другое.
Теперь, чтобы понять, как же работают нейронные сети, давайте взглянем на ее составляющие и их параметры.
Что такое нейрон?

Нейрон - это вычислительная единица, которая получает информацию, производит над ней простые вычисления и передает ее дальше. Они делятся на три основных типа: входной (синий), скрытый (красный) и выходной (зеленый). Также есть нейрон смещения и контекстный нейрон о которых мы поговорим в следующей статье. В том случае, когда нейросеть состоит из большого количества нейронов, вводят термин слоя. Соответственно, есть входной слой, который получает информацию, n скрытых слоев (обычно их не больше 3), которые ее обрабатывают и выходной слой, который выводит результат. У каждого из нейронов есть 2 основных параметра: входные данные (input data) и выходные данные (output data). В случае входного нейрона: input=output. В остальных, в поле input попадает суммарная информация всех нейронов с предыдущего слоя, после чего, она нормализуется, с помощью функции активации (пока что просто представим ее f(x)) и попадает в поле output.

Важно помнить , что нейроны оперируют числами в диапазоне или [-1,1]. А как же, вы спросите, тогда обрабатывать числа, которые выходят из данного диапазона? На данном этапе, самый простой ответ - это разделить 1 на это число. Этот процесс называется нормализацией, и он очень часто используется в нейронных сетях. Подробнее об этом чуть позже.
Что такое синапс?

Синапс это связь между двумя нейронами. У синапсов есть 1 параметр - вес. Благодаря ему, входная информация изменяется, когда передается от одного нейрона к другому. Допустим, есть 3 нейрона, которые передают информацию следующему. Тогда у нас есть 3 веса, соответствующие каждому из этих нейронов. У того нейрона, у которого вес будет больше, та информация и будет доминирующей в следующем нейроне (пример - смешение цветов). На самом деле, совокупность весов нейронной сети или матрица весов - это своеобразный мозг всей системы. Именно благодаря этим весам, входная информация обрабатывается и превращается в результат.
Важно помнить , что во время инициализации нейронной сети, веса расставляются в случайном порядке.
Как работает нейронная сеть?

В данном примере изображена часть нейронной сети, где буквами I обозначены входные нейроны, буквой H - скрытый нейрон, а буквой w - веса. Из формулы видно, что входная информация - это сумма всех входных данных, умноженных на соответствующие им веса. Тогда дадим на вход 1 и 0. Пусть w1=0.4 и w2 = 0.7 Входные данные нейрона Н1 будут следующими: 1*0.4+0*0.7=0.4. Теперь когда у нас есть входные данные, мы можем получить выходные данные, подставив входное значение в функцию активации (подробнее о ней далее). Теперь, когда у нас есть выходные данные, мы передаем их дальше. И так, мы повторяем для всех слоев, пока не дойдем до выходного нейрона. Запустив такую сеть в первый раз мы увидим, что ответ далек от правильно, потому что сеть не натренирована. Чтобы улучшить результаты мы будем ее тренировать. Но прежде чем узнать как это делать, давайте введем несколько терминов и свойств нейронной сети.
Функция активации
Функция активации - это способ нормализации входных данных (мы уже говорили об этом ранее). То есть, если на входе у вас будет большое число, пропустив его через функцию активации, вы получите выход в нужном вам диапазоне. Функций активации достаточно много поэтому мы рассмотрим самые основные: Линейная, Сигмоид (Логистическая) и Гиперболический тангенс. Главные их отличия - это диапазон значений.Линейная функция
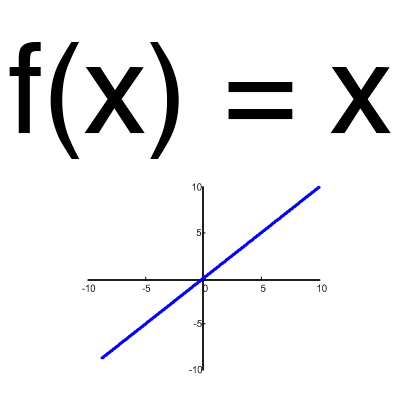
Эта функция почти никогда не используется, за исключением случаев, когда нужно протестировать нейронную сеть или передать значение без преобразований.
Сигмоид

Это самая распространенная функция активации, ее диапазон значений . Именно на ней показано большинство примеров в сети, также ее иногда называют логистической функцией. Соответственно, если в вашем случае присутствуют отрицательные значения (например, акции могут идти не только вверх, но и вниз), то вам понадобиться функция которая захватывает и отрицательные значения.
Гиперболический тангенс

Имеет смысл использовать гиперболический тангенс, только тогда, когда ваши значения могут быть и отрицательными, и положительными, так как диапазон функции [-1,1]. Использовать эту функцию только с положительными значениями нецелесообразно так как это значительно ухудшит результаты вашей нейросети.
Тренировочный сет
Тренировочный сет - это последовательность данных, которыми оперирует нейронная сеть. В нашем случае исключающего или (xor) у нас всего 4 разных исхода то есть у нас будет 4 тренировочных сета: 0xor0=0, 0xor1=1, 1xor0=1,1xor1=0.Итерация
Это своеобразный счетчик, который увеличивается каждый раз, когда нейронная сеть проходит один тренировочный сет. Другими словами, это общее количество тренировочных сетов пройденных нейронной сетью.Эпоха
При инициализации нейронной сети эта величина устанавливается в 0 и имеет потолок, задаваемый вручную. Чем больше эпоха, тем лучше натренирована сеть и соответственно, ее результат. Эпоха увеличивается каждый раз, когда мы проходим весь набор тренировочных сетов, в нашем случае, 4 сетов или 4 итераций.
Важно не путать итерацию с эпохой и понимать последовательность их инкремента. Сначала n
раз увеличивается итерация, а потом уже эпоха и никак не наоборот. Другими словами, нельзя сначала тренировать нейросеть только на одном сете, потом на другом и тд. Нужно тренировать каждый сет один раз за эпоху. Так, вы сможете избежать ошибок в вычислениях.



