Нелинейная регрессия в excel. Простая линейная регрессия
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
Регрессия бывает:
· линейной (у = а + bx);
· параболической (y = a + bx + cx 2);
· экспоненциальной (y = a * exp(bx));
· степенной (y = a*x^b);
· гиперболической (y = b/x + a);
· логарифмической (y = b * 1n(x) + a);
· показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.
Модель линейной регрессии имеет следующий вид:
У = а 0 + а 1 х 1 +…+а к х к.
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
1. Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».

2. Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
3. Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.

После активации надстройка будет доступна на вкладке «Данные».

Теперь займемся непосредственно регрессионным анализом.
1. Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».

2. Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.

3. После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).

В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Построение линейной регрессии, оценивание ее параметров и их значимости можно выполнить значительнее быстрей при использовании пакета анализа Excel (Регрессия). Рассмотрим интерпретацию полученных результатов в общем случае (k объясняющих переменных) по данным примера 3.6.
В таблице регрессионной статистики приводятся значения:
Множественный R – коэффициент множественной корреляции ;
R - квадрат – коэффициент детерминации R 2 ;
Нормированный R - квадрат – скорректированный R 2 с поправкой на число степеней свободы;
Стандартная ошибка – стандартная ошибка регрессии S ;
Наблюдения – число наблюдений n .
В таблице Дисперсионный анализ приведены:
1. Столбец df - число степеней свободы, равное
для строки Регрессия df = k ;
для строкиОстаток df = n – k – 1;
для строкиИтого df = n – 1.
2. Столбец SS – сумма квадратов отклонений, равная
для строки Регрессия ;
для строкиОстаток ;
для строкиИтого .
3. Столбец MS дисперсии, определяемые по формуле MS = SS /df :
для строки Регрессия – факторная дисперсия;
для строкиОстаток – остаточная дисперсия.
4. Столбец F – расчетное значение F -критерия, вычисляемое по формуле
F = MS (регрессия)/MS (остаток).
5. Столбец Значимость F –значение уровня значимости, соответствующее вычисленной F -статистике.
Значимость F = FРАСП(F- статистика, df (регрессия), df (остаток)).
Если значимость F < стандартного уровня значимости, то R 2 статистически значим.
| Коэффи-циенты | Стандартная ошибка | t-cта-тистика | P-значение | Нижние 95% | Верхние 95% | |
| Y | 65,92 | 11,74 | 5,61 | 0,00080 | 38,16 | 93,68 |
| X | 0,107 | 0,014 | 7,32 | 0,00016 | 0,0728 | 0,142 |
В этой таблице указаны:
1. Коэффициенты – значения коэффициентов a , b .
2. Стандартная ошибка –стандартные ошибки коэффициентов регрессии S a , S b .
3. t- статистика – расчетные значения t -критерия, вычисляемые по формуле:
t-статистика = Коэффициенты / Стандартная ошибка.
4.Р -значение (значимость t ) – это значение уровня значимости, соответствующее вычисленной t- статистике.
Р -значение = СТЬЮДРАСП (t -статистика, df (остаток)).
Если Р -значение < стандартного уровня значимости, то соответствующий коэффициент статистически значим.
5. Нижние 95% и Верхние 95% – нижние и верхние границы 95 %-ных доверительных интервалов для коэффициентов теоретического уравнения линейной регрессии.
| ВЫВОД ОСТАТКА | ||
| Наблюдение | Предсказанное y | Остатки e |
| 72,70 | -29,70 | |
| 82,91 | -20,91 | |
| 94,53 | -4,53 | |
| 105,72 | 5,27 | |
| 117,56 | 12,44 | |
| 129,70 | 19,29 | |
| 144,22 | 20,77 | |
| 166,49 | 24,50 | |
| 268,13 | -27,13 |
В таблице ВЫВОД ОСТАТКА указаны:
в столбце Наблюдение – номер наблюдения;
в столбце Предсказанное y – расчетные значения зависимой переменной;
в столбце Остатки e – разница между наблюдаемыми и расчетными значениями зависимой переменной.
Пример 3.6. Имеются данные (усл. ед.) о расходах на питание y и душевого дохода x для девяти групп семей:
| x | |||||||||
| y |
Используя результаты работы пакета анализа Excel (Регрессия), проанализируем зависимость расходов на питание от величины душевого дохода.
Результаты регрессионного анализа принято записывать в виде:
![]()
где в скобках указаны стандартные ошибки коэффициентов регрессии.
Коэффициенты регрессии а = 65,92 и b = 0,107. Направление связи между y и x определяет знак коэффициентарегрессии b = 0,107, т.е. связь является прямой и положительной. Коэффициент b = 0,107 показывает, что при увеличении душевого дохода на 1 усл. ед. расходы на питание увеличиваются на 0,107 усл. ед.
Оценим значимость коэффициентов полученной модели. Значимость коэффициентов (a, b ) проверяется по t -тесту:
Р-значение (a ) = 0,00080 < 0,01 < 0,05
Р-значение (b ) = 0,00016 < 0,01 < 0,05,
следовательно, коэффициенты (a, b ) значимы при 1 %-ном уровне, а тем более при 5 %-ном уровне значимости. Таким образом, коэффициенты регрессии значимы и модель адекватна исходным данным.
Результаты оценивания регрессии совместимы не только с полученными значениями коэффициентов регрессии, но и с некоторым их множеством (доверительным интервалом). С вероятностью 95 % доверительные интервалы для коэффициентов есть (38,16 – 93,68) для a и (0,0728 – 0,142) для b.
Качество модели оценивается коэффициентом детерминации R 2 .
Величина R 2 = 0,884 означает, что фактором душевого дохода можно объяснить 88,4 % вариации (разброса) расходов на питание.
Значимость R 2 проверяется по F- тесту: значимость F = 0,00016 < 0,01 < 0,05, следовательно, R 2 значим при 1 %-ном уровне, а тем более при 5 %-ном уровне значимости.
В случае парной линейной регрессии коэффициент корреляции можно определить как ![]() . Полученное значение коэффициента корреляции свидетельствует, что связь между расходами на питание и душевым доходом очень тесная.
. Полученное значение коэффициента корреляции свидетельствует, что связь между расходами на питание и душевым доходом очень тесная.
Метод линейной регрессии позволяет нам описывать прямую линию, максимально соответствующую ряду упорядоченных пар (x, y). Уравнение для прямой линии, известное как линейное уравнение, представлено ниже:
ŷ — ожидаемое значение у при заданном значении х,
x — независимая переменная,
a — отрезок на оси y для прямой линии,
b — наклон прямой линии.
На рисунке ниже это понятие представлено графически:
На рисунке выше показана линия, описанная уравнением ŷ =2+0.5х. Отрезок на оси у — это точка пересечения линией оси у; в нашем случае а = 2. Наклон линии, b, отношение подъема линии к длине линии, имеет значение 0.5. Положительный наклон означает, что линия поднимается слева направо. Если b = 0, линия горизонтальна, а это значит, что между зависимой и независимой переменными нет никакой связи. Иными словами, изменение значения x не влияет на значение y.
Часто путают ŷ и у. На графике показаны 6 упорядоченных пар точек и линия, в соответствии с данным уравнением
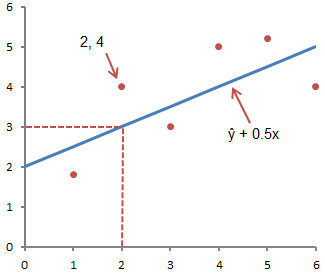
На этом рисунке показана точка, соответствующая упорядоченной паре х = 2 и у = 4. Обратите внимание, что ожидаемое значение у в соответствии с линией при х = 2 является ŷ. Мы можем подтвердить это с помощью следующего уравнения:
ŷ = 2 + 0.5х =2 +0.5(2) =3.
Значение у представляет собой фактическую точку, а значение ŷ — это ожидаемое значение у с использованием линейного уравнения при заданном значении х.
Следующий шаг - определить линейное уравнение, максимально соответствующее набору упорядоченных пар, об этом мы говорили в предыдущей статье, где определяли вид уравнения по .
Использование Excel для определения линейной регрессии
Для того, чтобы воспользоваться инструментом регрессионного анализа встроенного в Excel, необходимо активировать надстройку Пакет анализа . Найти ее можно, перейдя по вкладке Файл –> Параметры (2007+), в появившемся диалоговом окне Параметры Excel переходим во вкладку Надстройки. В поле Управление выбираем Надстройки Excel и щелкаем Перейти. В появившемся окне ставим галочку напротив Пакет анализа, жмем ОК.

Во вкладке Данные в группе Анализ появится новая кнопка Анализ данных.

Чтобы продемонстрировать работу надстройки, воспользуемся данными , где парень и девушка делят столик в ванной. Введите данные нашего примера с ванной в столбцы А и В чистого листа.
Перейдите во вкладку Данные, в группе Анализ щелкните Анализ данных. В появившемся окне Анализ данных выберите Регрессия , как показано на рисунке, и щелкните ОК.

Установите необходимыe параметры регрессии в окне Регрессия , как показано на рисунке:

Щелкните ОК. На рисунке ниже показаны полученные результаты:
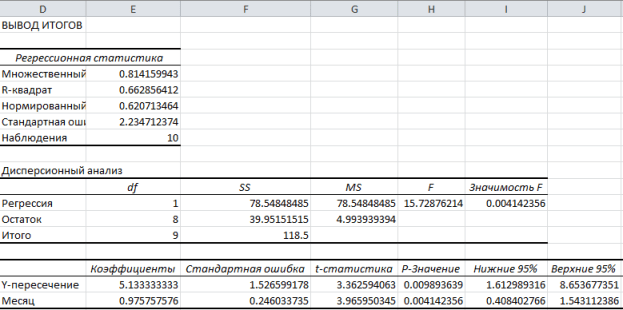
Эти результаты соответствуют тем, которые мы получили путем самостоятельных вычислений в .
Линия регрессии является графическим отражением взаимосвязи между явлениями. Очень наглядно можно построить линию регрессии в программе Excel.
Для этого необходимо:
1.Открыть программу Excel
2.Создать столбцы с данными. В нашем примере мы будем строить линию регрессии, или взаимосвязи, между агрессивностью и неуверенностью в себе у детей-первоклассников. В эксперименте участвовали 30 детей, данные представлены в таблице эксель:
1 столбик — № испытуемого
2 столбик — агрессивность в баллах
3 столбик — неуверенность в себе в баллах

3.Затем необходимо выделить оба столбика (без названия столбика), нажать вкладку вставка , выбрать точечная , а из предложенных макетов выбрать самый первый точечная с маркерами .

4.Итак у нас получилась заготовка для линии регрессии — так называемая — диаграмма рассеяния . Для перехода к линии регрессии нужно щёлкнуть на получившийся рисунок, нажать вкладку конструктор, найти на панели макеты диаграмм и выбрать Ма кет9 , на нем ещё написано f(x)

5.Итак, у нас получилась линия регрессии. На графике также указано её уравнение и квадрат коэффициента корреляции

6.Осталось добавить название графика, название осей. Также по желанию можно убрать легенду, уменьшить количество горизонтальных линий сетки (вкладка макет , затем сетка ). Основные изменения и настройки производятся во вкладке Макет

Линия регрессии построена в MS Excel. Теперь её можно добавить в текст работы.
Пакет MS Excel позволяет при построении уравнения линейной регрессии большую часть работы сделать очень быстро. Важно понять, как интерпретировать полученные результаты. Для построения модели регрессии необходимо выбрать пункт Сервис\Анализ данных\Регрессия (в Excel 2007 этот режим находится в блоке Данные/Анализ данных/Регрессия). Затем полученные результаты скопировать в блок для анализа.




