Esimerkkejä SQL-kyselyistä MySQL-tietokantaan. Erityisohjeet ja tarjoukset
Kuinka saan selville tietyn toimittajan tuottamien PC-mallien määrän? Kuinka määritetään keskimääräinen hinta tietokoneille, joilla on samat tekniset tiedot? Näihin ja moniin muihin joihinkin tilastotietoihin liittyviin kysymyksiin voidaan vastata yhteenveto (aggregaatti) toiminnot... Standardi tarjoaa seuraavat aggregaattitoiminnot:
Kaikki nämä toiminnot palauttavat yhden arvon. Tässä tapauksessa toiminnot COUNT, MIN ja MAX ovat sovellettavissa mihin tahansa tietotyyppiin, kun taas SUMMA ja AVG käytetään vain numeerisiin kenttiin. Ero toiminnon välillä KREIVI (*) ja KREIVI (<имя поля>) on, että toinen ei ota NULL-arvoja huomioon laskettaessa.
Esimerkki. Löydä henkilökohtaisten tietokoneiden vähimmäis- ja enimmäishinta:
Esimerkki. Etsi valmistajalta A saatavana olevien tietokoneiden määrä:
Esimerkki. Jos olemme kiinnostuneita valmistajan A tuottamien erilaisten mallien lukumäärästä, kysely voidaan muotoilla seuraavasti (käyttämällä sitä tosiasiaa, että tuotetaulukossa kukin malli on kirjattu kerran):
Esimerkki. Etsi valmistajalta A. saatavana olevien erilaisten mallien määrä. Kysely on samanlainen kuin edellinen, jossa vaadittiin valmistajan A tuottamien mallien kokonaismäärän määrittäminen. Täältä löydät myös erilaisten mallien lukumäärän PC-pöytä (eli myynnissä).
Kun halutaan varmistaa, että tilastollisten indikaattoreiden saamisessa käytetään vain yksilöllisiä arvoja aggregaattifunktioiden argumentti voidaan käyttää dISTINCT-parametri... Muu parametri ALL on oletusarvo ja olettaa, että kaikki sarakkeen palautusarvot lasketaan. Operaattori,
Jos meidän on saatava tuotettujen PC-mallien määrä joka valmistajan, sinun on käytettävä gROUP BY -lausekesyntaktisesti seuraa missä lausekkeet.
GROUP BY -lauseke
GROUP BY -lauseke käytetään määrittelemään lähtölinjojen ryhmiä, joihin voidaan soveltaa yhdistetyt toiminnot (COUNT, MIN, MAX, AVG ja SUM)... Jos tämä lause puuttuu ja käytetään aggregaattitoimintoja, kaikki sarakkeet, joissa on mainitut nimet VALITSEtulisi sisällyttää aggregaattitoiminnot, ja näitä toimintoja käytetään koko kysely predikaatin tyydyttävällä rivillä. Muussa tapauksessa kaikki SELECT-luettelon sarakkeet, ei sisälly aggregaattitoiminnoissa, on määritettävä gROUP BY -lausekkeessa... Tämän seurauksena kaikki kyselyn lähtörivit on jaettu ryhmiin, joille on tunnusomaista samat arvoyhdistelmät näissä sarakkeissa. Sen jälkeen kullekin ryhmälle käytetään aggregaattitoimintoja. Huomaa, että GROUP BY: llä kaikkia NULL-arvoja käsitellään yhtä suurina, ts. kun ne ryhmitellään NULL-arvoja sisältävän kentän mukaan, kaikki tällaiset rivit kuuluvat yhteen ryhmään.Jos jos on GROUP BY -lauseke, SELECT-lausekkeessa ei aggregaattitoimintoja, kysely palauttaa yksinkertaisesti yhden rivin kustakin ryhmästä. Tätä ominaisuutta yhdessä DISTINCT-avainsanan kanssa voidaan poistaa päällekkäisistä riveistä tulosjoukossa.
Katsotaanpa yksinkertaista esimerkkiä:
| SELECT-malli, COUNT (malli) AS Määrä_malli, AVG (hinta) AS Keskimääräinen_hinta PC: ltä GROUP BY -malli; |
Tässä pyynnössä määritetään jokaiselle PC-mallille niiden lukumäärä ja keskimääräiset kustannukset. Kaikki samat malliarvot muodostavat ryhmän, ja SELECT-lähtö laskee arvojen lukumäärän ja keskimääräiset hinta-arvot kullekin ryhmälle. Kyselyn tuloksena on seuraava taulukko:
| malli- | Määrä_malli | Keskim. Hinta |
| 1121 | 3 | 850.0 |
| 1232 | 4 | 425.0 |
| 1233 | 3 | 843.33333333333337 |
| 1260 | 1 | 350.0 |
Jos SELECT-sarakkeessa on päivämäärä, nämä indikaattorit voidaan laskea jokaiselle päivämäärälle. Tätä varten sinun on lisättävä päivämäärä ryhmittelysarakkeeksi, jolloin kootut funktiot lasketaan kullekin arvoyhdistelmälle (malli-päiväys).
On olemassa useita erityisiä säännöt yhdistettyjen toimintojen suorittamisesta:
- Jos kyselyn tuloksena ei rivejä vastaanotettu (tai useammalle kuin yhdelle riville tälle ryhmälle), niin lähtötiedot minkä tahansa aggregaattilaskennan laskemiseksi puuttuvat. Tässä tapauksessa COUNT-funktioiden tulos on nolla ja kaikkien muiden toimintojen tulos on NULL.
- Perustelu aggregaattitoiminto ei voi itse sisältää aggregaattitoimintoja (toiminto toiminnosta). Nuo. yhdessä kyselyssä et voi sanoa enimmäisarvoa keskiarvoista.
- COUNT-funktion tulos on kokonaisluku (KOKONAISLUKU). Muut yhdistetyt toiminnot perivät käsiteltävien arvojen tietotyypit.
- Jos suoritettaessa SUM-toimintoa saatiin tulos, joka ylittää käytetyn tietotyypin maksimiarvon, virhe.
Joten, jos pyyntö ei sisällä gROUP BY -lausekkeetsitten aggregaattitoiminnotsisältyy sELECT-lauseke, suoritetaan kaikille tuloksena oleville kyselyriveille. Jos pyyntö sisältää gROUP BY -lauseke, jokaisella rivillä, jolla on sama sarake tai sarakeryhmä, joka on määritelty kohdassa gROUP BY -lauseke, muodostaa ryhmän ja aggregaattitoiminnot suoritetaan kullekin ryhmälle erikseen.
HAVING-lauseke
Jos wHERE-lauseke määrittää predikaatin rivien suodattamiseksi tARJOUS sovellettu ryhmittelyn jälkeen määritellä samanlainen predikaatti suodatusryhmät arvojen perusteella aggregaattitoiminnot... Tätä lauseketta tarvitaan testattaessa arvoja, jotka saadaan aggregaattitoiminto ei erillisestä rivistä tietueessa määritelty tietolähde fROM-lausekeja tällaisten linjojen ryhmät... Siksi tällaista tarkastusta ei voida sisällyttää wHERE-lauseke.
Jokaisen web-kehittäjän on tiedettävä SQL, jotta voidaan kirjoittaa tietokantakyselyjä. Ja vaikka phpMyAdminia ei ole peruutettu, matalan tason SQL: n kirjoittaminen on usein tarpeen likaista kätesi.
Siksi olemme valmistaneet nopean esittelyn SQL: n perusteista. Aloitetaan!
1. Taulukon luominen
CREATE TABLE -käskyä käytetään taulukoiden luomiseen. Argumenttien on oltava sarakkeiden nimi sekä niiden tietotyypit.
Luodaan yksinkertainen taulukko nimeltä kuukausi... Se koostuu 3 sarakkeesta:
- id - kuukauden numero kalenterivuodessa (kokonaisluku).
- nimi - Kuukauden nimi (merkkijono, enintään 10 merkkiä).
- päivää - Päivien määrä tässä kuussa (kokonaisluku).
Näin vastaava SQL-kysely näyttää:
LUO TAULUKKO kuukautta (id int, nimi varchar (10), päivää int);
Lisäksi taulukoita luodessa on suositeltavaa lisätä ensisijainen avain yhteen sarakkeisiin. Tämä pitää tietueet ainutlaatuisina ja nopeuttaa hakupyyntöjä. Olkoon kuukauden nimi yksilöllinen tapauksessamme (sarake nimi)
LUO TAULUKKO kuukautta (id int, name varchar (10), days int, PRIMARY KEY (name));
| Tietotyyppi | Kuvaus |
|---|---|
| PÄIVÄMÄÄRÄ | Päivämääräarvot |
| TREFFIAIKA | Päivämäärä- ja aika-arvot ovat rahapajan tarkat |
| AIKA | Aika-arvot |
2. Lisää rivejä
Täytetään nyt taulukko kuukaudet hyödyllistä tietoa. Tietueiden lisääminen taulukkoon tapahtuu INSERT-käskyn kautta. On kaksi tapaa kirjoittaa tämä ohje.
Ensimmäinen tapa ei ole määrittää niiden sarakkeiden nimiä, joihin tiedot lisätään, vaan määrittää vain arvot.
Tämä kirjoitustapa on yksinkertainen, mutta vaarallinen, koska ei ole takeita siitä, että projektin laajentuessa ja taulukkoa muokattaessa sarakkeet ovat samassa järjestyksessä kuin aiemmin. Turvallinen (ja samalla hankalampi) tapa kirjoittaa INSERT-käsky edellyttää, että määritetään sekä arvot että sarakkeiden järjestys:
Tässä on luettelon ensimmäinen arvo ARVOT vastaa ensimmäistä määritettyä sarakkeen nimeä ja niin edelleen.
3. Haetaan tietoja taulukoista
SELECT-käsky on paras ystävämme, kun haluamme hakea tietoja tietokannasta. Sitä käytetään hyvin usein, joten lue tämä kohta huolellisesti.
Yksinkertaisin valinta SELECT-käskyssä on kysely, joka palauttaa kaikki taulukon sarakkeet ja rivit (esimerkiksi taulukot nimen mukaan merkkiä):
VALITSE * FROM "merkeistä"
Tähti (*) tarkoittaa, että haluamme saada tietoja kaikista sarakkeista. Koska SQL-tietokannat koostuvat yleensä useammasta kuin yhdestä taulukosta, FROM-avainsana on määritettävä ja sen jälkeen taulukon nimi välilyönnillä erotettuna.
Joskus emme halua saada tietoja kaikista taulukon sarakkeista. Tätä varten meidän on kirjoitettava tähtien (*) sijaan muistiin haluttujen sarakkeiden nimet pilkuilla erotettuna.
SELECT tunnus, nimi FROM kuukausi
Monissa tapauksissa haluamme myös, että tulokset lajitellaan tietyssä järjestyksessä. SQL: ssä teemme tämän ORDER BY: llä. Se voi vaatia valinnaisen muokkaajan - ASC (oletus) -lajittelun nousevassa järjestyksessä tai DESC-lajittelun laskevassa järjestyksessä:
VALITSE tunnus, nimi kuukaudesta TILAUS NIMEN KUVA
Kun käytät ORDER BY -ohjelmaa, varmista, että se on viimeinen SELECT-käskyssä. Muussa tapauksessa virheilmoitus tulee näkyviin.
4. Tietojen suodatus
Olet oppinut valitsemaan tarkasti määritellyt sarakkeet tietokannasta SQL-kyselyn avulla, mutta entä jos tarvitsemme myös tiettyjä rivejä? WHERE-lauseke tulee tässä pelastamaan, jolloin voimme suodattaa tietoja olosuhteista riippuen.
Tässä kyselyssä valitsemme taulukosta vain ne kuukaudet kuukausijossa yli 30 päivää operaattorin käyttäminen enemmän (\u003e).
SELECT tunnus, nimi kuukaudesta WHERE päivää\u003e 30
5. Edistynyt tietojen suodatus. JA ja TAI operaattorit
Aikaisemmin käytimme tietojen suodatusta yhdellä kriteerillä. Kehittyneempää tietojen suodatusta varten voit käyttää AND- ja OR-operaattoreita ja vertailuoperaattoreita (\u003d,<,>,<=,>=,<>).
Tässä meillä on taulukko, joka sisältää neljä kaikkien aikojen myydyintä albumia. Valitaan ne, jotka luokitellaan rockiksi ja joilla on alle 50 miljoonaa kappaletta myyty. Tämä voidaan tehdä helposti asettamalla AND-operaattori näiden kahden ehdon väliin.
 VALITSE * FROM albumeista WHERE genre \u003d "rock" JA myyntimillarit<= 50
ORDER BY released
VALITSE * FROM albumeista WHERE genre \u003d "rock" JA myyntimillarit<= 50
ORDER BY released
6. In / välillä / Like
WHERE tukee myös useita erikoiskomentoja, joiden avulla voit nopeasti tarkistaa useimmin käytetyt kyselyt. Täällä he ovat:
- IN - osoittaa erilaisten ehtojen, jotka kaikki voidaan täyttää
- BETWEEN - Tarkistaa, onko arvo määritetyn alueen sisällä
- LIKE - etsii tiettyjä malleja
Esimerkiksi, jos haluamme valita albumit pop- ja sielu musiikkia, voimme käyttää IN ("arvo1", "arvo2").
SELECT * FROM albumeista WHERE genre IN ("pop", "soul");
Jos haluamme saada kaikki albumit julkaistuksi vuosina 1975-1985, meidän on tallennettava:
SELECT * FROM-albumeista, Missä julkaistiin VUOSI 1975 JA 1985;
7. Toiminnot
SQL on täynnä toimintoja, jotka tekevät hyödyllisiä asioita. Joitakin yleisimmin käytettyjä ovat:
- COUNT () - palauttaa rivien määrän
- SUM () - Palauttaa numeerisen sarakkeen kokonaissumman
- AVG () - Palauttaa arvoryhmän keskiarvon
- MIN () / MAX () - saa min / max-arvon sarakkeesta
Viimeisen vuoden saamiseksi taulukkoon meidän on kirjoitettava seuraava SQL-kysely:
SELECT MAX (julkaistu) albumista;
8. Alakyselyt
Edellisessä kappaleessa opimme kuinka tehdä yksinkertaisia \u200b\u200blaskelmia datalla. Jos haluamme käyttää näiden laskelmien tulosta, emme voi tehdä ilman sisäkkäisiä kyselyitä. Oletetaan, että haluamme tuottaa taiteilija, albumi ja julkaisuvuosi taulukon vanhimmalle albumille.
Tiedämme, kuinka saada nämä erityiset sarakkeet:
SELECT-esittäjä, albumi, julkaistu FROM-albumeista;
Tiedämme myös, kuinka saada aikaisin vuosi:
SELECT MIN (julkaistu) albumista;
Tarvitset vain yhdistää nämä kaksi kyselyä WHERE-sovelluksella:
SELECT taiteilija, albumi, julkaistu albumeista WHERE atbrīvettu \u003d (SELECT MIN (julkaistu) albumeista);
9. Taulukoiden ketjutus
Monimutkaisemmissa tietokannoissa on useita toisiinsa liittyviä taulukoita. Esimerkiksi alla on kaksi taulukkoa videopeleistä ( videopelit) ja videopelien kehittäjät ( game_developers).


Pöydässä videopelit on kehittäjän sarake ( kehittäjän_tunnus), mutta se sisältää kokonaisluvun, ei kehittäjän nimeä. Tämä numero on tunniste ( id) vastaavan kehittäjän pelikehittäjätaulukosta ( game_developers), linkittämällä nämä kaksi luetteloa loogisesti, jolloin voimme käyttää molempiin luetteloihin tallennettuja tietoja samanaikaisesti.
Jos haluamme luoda kyselyn, joka palauttaa kaiken tiedettävän peleistä, voimme INNER JOIN -toiminnon avulla linkittää sarakkeet molemmista taulukoista.
VALITSE video_games.name, video_games.genre, game_developers.name, game_developers.country FROM video_games INNER JOIN peli_developers ON video_games.developer_id \u003d game_developers.id;
Tämä on yksinkertaisin ja yleisin JOIN-tyyppi. On olemassa useita muita vaihtoehtoja, mutta ne koskevat harvinaisempia tapauksia.
10. aliakset
Jos tarkastelet edellistä esimerkkiä, huomaat, että siellä on kaksi saraketta nimi... Tämä on hämmentävää, joten asetetaan aliakseksi esimerkiksi yksi toistuvista sarakkeista nimi pöydältä game_developers kutsutaan kehittäjä.
Voimme myös lyhentää kyselyä määrittämällä aliaksia taulukkojen nimille: videopelit soitetaan pelejä, game_developers - kehittäjät:
VALITSE games.name, games.genre, devs.name kehittäjänä, devs.country videopeleistä AS games INNER JOIN game_developers AS devs ON games.developer_id \u003d devs.id;
11. Tietojen päivittäminen
Meidän on usein muutettava tietoja joillakin riveillä. SQL: ssä tämä tehdään UPDATE-käskyn avulla. UPDATE-käsky koostuu:
- Taulukko, joka sisältää korvausarvon;
- Sarakkeiden nimet ja niiden uudet arvot;
- WHERE valitut rivit, jotka haluamme päivittää. Jos tätä ei tehdä, kaikki taulukon rivit muuttuvat.
Alla on taulukko tV-sarja sarjoilla ja luokituksillaan. Pöytään hiili kuitenkin pieni virhe: vaikka sarja Valtaistuinpeli ja häntä kuvataan komediana, hän ei todellakaan ole. Korjataan se!
 Tv_series-taulukon tiedot PÄIVITÄ tv_series SET genre \u003d "draama" WHERE id \u003d 2;
Tv_series-taulukon tiedot PÄIVITÄ tv_series SET genre \u003d "draama" WHERE id \u003d 2; 12. Tietojen poistaminen
Rivin poistaminen taulukosta SQL: n avulla on hyvin yksinkertainen prosessi. Sinun tarvitsee vain valita taulukko ja poistettava rivi. Poistetaan taulukon viimeinen rivi edellisestä esimerkistä. tV-sarja... Tämä tehdään käskyllä\u003e POISTA.
POISTA tv_seriesistä MISSÄ id \u003d 4
Ole varovainen kirjoittaessasi DELETE-käskyä ja varmista, että WHERE-lauseke on olemassa, muuten kaikki taulukon rivit poistetaan!
13. Pöydän pudottaminen
Jos haluamme poistaa kaikki rivit, mutta poistumme itse taulukosta, käytä sitten TRUNCATE-komentoa:
TRUNCATE TABLE taulukon_nimi;
Siinä tapauksessa, että haluamme todella poistaa sekä tiedot että itse taulukon, DROP-komento on kätevä:
DROP TABLE taulukon_nimi;
Ole varovainen näiden komentojen suhteen. Niitä ei voi kumota! / P\u003e
Tämä päättää SQL-opetusohjelmamme! Emme ole käsitelleet paljoakaan, mutta sen, mitä jo tiedät, pitäisi riittää antamaan sinulle käytännön taitoja web-urallasi.
Pyynnöt kirjoitetaan välttämättä lainauksia, koska MySQL, MS SQL ja PostGree he ovat erilaisia.
SQL-kysely: määritettyjen (pakollisten) kenttien saaminen taulukosta
SELECT id, country_title, count_people FROM taulukon_nimiSaamme luettelon tietueista: KAIKKI maat ja niiden väestö. Vaadittujen kenttien nimet erotetaan pilkuilla.
VALITSE * FROM taulukon_nimi
* tarkoittaa kaikkia kenttiä. Eli tulee olemaan vaikutelmia KAIKKI tietokentät.
SQL-kysely: tulostetietueet taulukosta ilman kaksoiskappaleita
Valitse DISTINCT country_title FROM taulukon_nimiSaamme luettelon tietueista: maat, joissa käyttäjämme sijaitsevat. Käyttäjiä voi olla useita yhdestä maasta. Tässä tapauksessa tämä on pyyntösi.
SQL-kysely: tietueiden näyttäminen taulukosta määritetyn ehdon mukaan
SELECT id, country_title, city_title FROM taulukon_nimi WHERE count_people\u003e 100000000Saamme luettelon tietueista: maat, joissa ihmisten määrä on yli 100 000 000.
SQL-kysely: tietueiden näyttäminen taulukosta järjestyksellä
SELECT id, city_title FROM taulukon_nimi TILAA BY city_titleSaamme luettelon tietueista: kaupungit aakkosjärjestyksessä. A: n alussa, I: n lopussa.
SELECT id, city_title FROM taulukon_nimi ORDER BY city_title DESC
Saamme luettelon tietueista: kaupungit taaksepäin ( DESC) Tilaus. Alussa minä, lopussa A.
SQL-kysely: tietueiden määrän laskeminen
Valitse COUNT (*) FROM taulukon_nimiSaamme taulukon tietueiden määrän (lukumäärän). Tässä tapauksessa EI ole luetteloa tietueista.
SQL-kysely: tuota vaadittu tietueiden alue
VALITSE * FROM taulukon_nimi RAJA 2, 3Saamme 2 (toinen) ja 3 (kolmas) tietuetta taulukosta. Pyyntö on hyödyllinen, kun luot navigointia WEB-sivuilla.
SQL-kyselyt ehdoilla
Tietueiden tuotos taulukosta tietyn ehdon mukaan loogisten operaattoreiden avulla.
SQL-kysely: JA rakentaminen
SELECT id, city_title FROM table_name WHERE maa \u003d "Venäjä" JA öljy \u003d 1Saamme luettelon tietueista: kaupungit Venäjältä JA öljyä. Kun operaattoria käytetään JA, niin molempien ehtojen on vastattava toisiaan.
SQL-kysely: TAI rakenna
VALITSE tunnus, city_title FROM taulukon_nimi WHERE country \u003d "Russia" TAI country \u003d "USA"Saamme luettelon tietueista: kaikki kaupungit Venäjältä TAI USA. Kun operaattoria käytetään TAI, niin ainakin yhden ehdon on vastattava.
SQL-kysely: EI EI rakentamista
SELECT id, user_login FROM taulukon_nimi WHERE country \u003d "Venäjä" EIKÄ count_kommentteja<7Saamme luettelon tietueista: kaikki käyttäjät Venäjältä JA kuka teki EI VÄHEMPÄÄ 7 kommenttia.
SQL-kysely: IN (B) -rakenne
SELECT id, user_login FROM table_name WHERE maa IN ("Venäjä", "Bulgaria", "Kiina")Saamme luettelon tietueista: kaikki käyttäjät, jotka asuvat ( SISÄÄN) (Venäjä, Bulgaria tai Kiina)
SQL-kysely: EI rakentamisessa
SELECT id, user_login FROM table_name WHERE country NOT IN ("Venäjä", "Kiina")Saamme luettelon tietueista: kaikki käyttäjät, jotka eivät asu ( EI SISÄLLÄ) (Venäjä tai Kiina).
SQL-kysely: IS NULL -rakenne (tyhjät tai EI tyhjät arvot)
SELECT id, user_login FROM taulukon_nimi WHERE tila on NULLSaamme luettelon merkinnöistä: kaikki käyttäjät, joiden tilaa ei ole määritelty. NULL on erillinen aihe, joten se tarkistetaan erikseen.
SELECT id, user_login FROM taulukon_nimi WHERE tila EI OLE NULL
Saamme luettelon tietueista: kaikki käyttäjät, joiden tila on määritelty (EI NOLLA).
SQL-kysely: LIKE-rakenne
SELECT id, user_login FROM taulukon_nimi WHERE sukunimi LIKE "Ivan%"Saamme luettelon tietueista: käyttäjät, joiden sukunimi alkaa yhdistelmällä "Ivan". % -Merkki tarkoittaa mitä tahansa merkkiä. % -Merkin löytämiseksi on käytettävä pakenevaa "Ivan \\%" -merkkiä.
SQL-kysely: Rakenteen välillä
SELECT id, user_login FROM table_name WHERE palkka VÄLILLÄ 25000 JA 50000Saamme luettelon tietueista: käyttäjät, jotka saavat palkkaa 25000 - 50000 mukaan lukien.
Loogisia operaattoreita on paljon, joten tutustu SQL-palvelimen ohjeisiin yksityiskohtaisesti.
Monimutkaiset SQL-kyselyt
SQL-kysely: useiden kyselyiden yhdistäminen
(SELECT-tunnus, user_login FROM taulukon_nimi1) UNION (SELECT-tunnus, user_login FROM taulukon_nimi2)Saamme luettelon merkinnöistä: käyttäjät, jotka ovat rekisteröityneet järjestelmään, sekä ne käyttäjät, jotka ovat rekisteröityneet foorumille erikseen. UNION-operaattori voi yhdistää useita kyselyjä. UNION toimii kuten SELECT DISTINCT, eli se hylkää päällekkäiset arvot. Saadaksesi kaikki tietueet, sinun on käytettävä UNION ALL -operaattoria.
SQL-kysely: lasketaan kentän arvot MAX, MIN, SUM, AVG, COUNT
Yhden tulos, laskurin maksimiarvo taulukossa:
Valitse MAX (laskuri) FROM taulukon_nimiYhden tulos, laskurin vähimmäisarvo taulukossa:
Valitse MIN (laskuri) FROM taulukon_nimiKaikkien laskuriarvojen summa näytetään taulukossa:
Valitse SUMMA (laskuri) FROM taulukon_nimiLaskurin keskiarvon näyttäminen taulukossa:
Valitse AVG (laskuri) FROM taulukon_nimiLaskurien määrän näyttäminen taulukossa:
SELECT COUNT (laskuri) FROM taulukon_nimiTyöpajan nro 1 laskurien määrän näyttö taulukossa:
SELECT COUNT (laskuri) FROM table_name WHERE toimisto \u003d "Kauppa # 1"Nämä ovat suosituimpia komentoja. Laskennassa on suositeltavaa käyttää tällaisia \u200b\u200bSQL-kyselyjä, mikäli mahdollista, koska mikään ohjelmointiympäristö ei voi verrata tietojenkäsittelynopeutta kuin itse SQL-palvelin omien tietojensa käsittelyssä.
SQL-kysely: tietueiden ryhmittely
VALITSE maanosa, SUMMA (maa_alue) maaryhmittäin maanosan mukaanSaamme luettelon tietueista: maanosan nimen ja kaikkien maiden pinta-alojen summan kanssa. Toisin sanoen, jos on hakemisto maista, joissa jokaisen maan pinta-ala on kirjattu, GROUP BY -lausekkeen avulla voit selvittää kunkin maanosan koon (maanosan mukaan ryhmittelyn perusteella).
SQL-kysely: useiden taulukoiden käyttäminen aliaksen kautta
VALITSE o.order_no, o.amount_paid, c.company FROM tilauksista AS o, asiakas AS with WHERE o.custno \u003d c.custno JA c.city \u003d "Tyumen"Saamme luettelon tietueista: tilaukset asiakkailta, jotka asuvat vain Tyumenissa.
Itse asiassa oikein suunnitellulla tämän tyyppisellä tietokannalla kysely on yleisimpiä, joten MySQL: ssä otettiin käyttöön erityinen operaattori, joka toimii monta kertaa nopeammin kuin yllä kirjoitettu koodi.
VALITSE o.order_no, o.amount_paid, z.company FROM tilauksista AS o LEFT JOIN asiakas AS z ON (z.custno \u003d o.custno)
Sisäkkäiset alakyselyt
SELECT * FROM taulukon_nimi WHERE palkka \u003d (SELECT MAX (palkka) työntekijältä)Saamme yhden tietueen: tiedot käyttäjästä, jolla on enimmäispalkka.
Huomio! Sisäkkäiset alikyselyt ovat yksi SQL-palvelinten pullonkauloista. Yhdessä joustavuutensa ja tehonsa lisäksi ne lisäävät merkittävästi palvelimen kuormitusta. Mikä johtaa muiden käyttäjien katastrofaaliseen hidastumiseen. Rekursiiviset puhelut, joissa on sisäkkäisiä kyselyitä, ovat hyvin yleisiä. Siksi suosittelen voimakkaasti EI käyttämään sisäkkäisiä kyselyjä, vaan jakamaan ne pienempiin. Tai käytä yllä olevaa VASEN JOIN -yhdistelmää. Tämän tyyppisten pyyntöjen lisäksi tietoturvaloukkaukset kohdistuvat yhä enemmän pyyntöihin. Jos päätät käyttää sisäkkäisiä alikyselyjä, sinun on suunniteltava ne erittäin huolellisesti ja tehtävä alkuajot tietokantojen (testitietokantojen) kopioille.
SQL-kyselyt muuttavat tietoja
SQL-kysely: INSERT
Ohjeet LISÄÄ voit lisätä tietueita taulukkoon. Luo yksinkertaisilla sanoilla taulukon tiedot sisältävä rivi.
Vaihtoehdon numero 1. Ohjeita käytetään usein:
INSERT INTO taulukon_nimi (id, user_login) ARVOT (1, "ivanov"), (2, "petrov")Pöydässä " taulukon_nimi"2 (kaksi) käyttäjää lisätään kerralla.
Vaihtoehdon numero 2. Tyyliä on helpompi käyttää:
INSERT taulukon_nimi SET id \u003d 1, user_login \u003d "ivanov"; INSERT taulukon_nimi SET id \u003d 2, user_login \u003d "petrov";Tällä on etuja ja haittoja.
Tärkeimmät haitat:
- Monet pienet SQL-kyselyt suoritetaan hieman hitaammin kuin yksi iso SQL-kysely, mutta muut kyselyt jonotetaan palveluun. Toisin sanoen, jos suuri SQL-kysely suoritetaan 30 minuutin ajan, niin koko tämän ajan loput kyselyt tupakoivat bambua ja odottavat vuoroaan.
- Pyyntö osoittautuu massiivisemmaksi kuin edellinen versio.
Tärkeimmät edut:
- Pienissä SQL-kyselyissä muita SQL-kyselyjä ei estetä.
- Lukemisen helppous.
- Joustavuus. Tässä vaihtoehdossa et voi seurata rakennetta, mutta lisätä vain tarvittavat tiedot.
- Kun muodostat arkistoja tällä tavalla, voit helposti kopioida yhden rivin ja ajaa sen komentorivin (konsolin) läpi, jolloin et palauta koko ARKISTOA.
- Kirjoitustyyli on samanlainen kuin UPDATE-lause, mikä helpottaa muistamista.
SQL-kysely: PÄIVITÄ
UPDATE table_name SET user_login \u003d "ivanov", käyttäjän_sukunimi \u003d "Ivanov" WHERE id \u003d 1Pöydässä " taulukon_nimi"Tietueessa, jonka id \u003d 1, user_login ja user_surname -kenttien arvot muutetaan määritetyiksi arvoiksi.
SQL-kysely: POISTA
POISTA taulukon_nimi -kohdasta WHERE id \u003d 3Tietue, jonka tunnus on 3, poistetaan taulukon_nimi taulukosta.
- On suositeltavaa kirjoittaa kaikki kenttien nimet pienillä kirjaimilla ja tarvittaessa erottaa ne pakotetulla välilyönnillä "_" yhteensopivuuden takaamiseksi eri ohjelmointikielillä, kuten Delphi, Perl, Python ja Ruby.
- Kirjoita SQL-komennot isoilla kirjaimilla luettavuuden takaamiseksi. Muista aina, että muut ihmiset voivat lukea koodin jälkeensi ja todennäköisesti sinä itse N ajan kuluttua.
- Nimeä kentät substantiivin alusta ja toimi. Esimerkiksi: city_status, user_login, user_name.
- Yritä välttää varakielisanoja eri kielillä, jotka voivat aiheuttaa ongelmia SQL: ssä, PHP: ssä tai Perlissä, kuten (nimi, määrä, linkki). Esimerkiksi: linkkiä voidaan käyttää MS SQL: ssä, mutta se on varattu MySQL: ään.
Tämä materiaali on lyhyt viite jokapäiväiseen työhön, eikä sitä väitetä olevan erittäin mega-arvovaltainen lähde, joka on tietyn tietokannan ensisijainen SQL-kyselyjen lähde.
- Siirtää
- Opetusohjelma
Tarvitsetko “SELECT * WHERE a \u003d b FROM c” tai “SELECT WHERE a \u003d b FROM c ON *”?
Jos olet kuin minä, niin olet samaa mieltä: SQL on yksi niistä asioista, jotka ensi silmäyksellä vaikuttavat helpoilta (se lukee ikään kuin englanniksi!), Mutta jostain syystä sinun on google jokaisen yksinkertaisen kyselyn löytää oikea syntaksin.
Ja sitten liittymiset, aggregaatit, alikyselyt alkavat, ja se osoittautuu täysin hölynpölyksi. Näyttää siltä:
VALITSE jäsenet. Etunimi || "" || members.lastname AS "Koko nimi" lainoista INNER JOIN jäsenet ON jäsenet.memberid \u003d lainat.memberid INNER JOIN kirjat ON books.bookid \u003d lainat.bookid WHERE lainat.bookid IN (SELECT bookid FROM books WHERE stock\u003e (SELECT keskim. (varastossa) ) Kirjoista)) RYHMÄ jäsenten mukaan. Etunimi, jäsenet.sukunimi;
Bue! Tämä pelottaa kaikki aloittelijat tai jopa välikehittäjät, jos hän näkee SQL: n ensimmäistä kertaa. Mutta se ei ole kaikki niin paha.
On helppo muistaa, mikä on intuitiivista, ja tämän opetusohjelman avulla toivon alentavan aloittelijoiden SQL-merkinnän kynnystä ja tarjoavan kokeneille uuden ilmeen SQL: ään.
Vaikka SQL-syntakse on melkein sama eri tietokannoissa, tässä artikkelissa kyselyihin käytetään PostgreSQL: ää. Jotkut esimerkit toimivat MySQL: ssä ja muissa tietokannoissa.
1. Kolme taikasanaa
SQL: ssä on monia avainsanoja, mutta SELECT, FROM ja WHERE näkyvät lähes jokaisessa kyselyssä. Hieman myöhemmin huomaat, että nämä kolme sanaa edustavat tietokantakyselyjen perustavanlaatuisia näkökohtia, ja muut, monimutkaisemmat kyselyt ovat vain niiden päällä olevia lisäosia.
2. Meidän tukikohta
Katsotaanpa tietokantaa, jota käytämme esimerkkinä tässä artikkelissa:


Meillä on kirjasto ja ihmisiä. Annettujen kirjojen kirjanpitoa varten on myös erityinen taulukko.
- Kirjat-taulukossa on tietoja kirjan otsikosta, tekijästä, julkaisupäivästä ja saatavuudesta. Se on yksinkertaista.
- Taulukossa "jäsenet" - kaikkien kirjastoon rekisteröityneiden ihmisten nimet ja sukunimet.
- Taulukko "lainat" tallentaa tietoja kirjastosta lainatuista kirjoista. Bookid-sarake viittaa kirjan ID-kirjaan ”kirjat” -taulukossa ja jäsen-sarake viittaa vastaavaan henkilöön jäsenet-taulukosta. Meillä on myös julkaisupäivä ja päivä, jolloin kirja on palautettava.
3. Yksinkertainen pyyntö
Aloitetaan yksinkertaisella kyselyllä: tarvitsemme nimet ja tunnisteet (id) kaikista kirjailijan "Dan Brown" kirjoittamista kirjoista
Pyyntö on seuraava:
VALITSE bookid AS "id", otsikko kirjoista WHERE author \u003d "Dan Brown";
Ja tulos on seuraava:
| id | otsikko |
|---|---|
| 2 | Kadonnut symboli |
| 4 | Inferno |
Melko yksinkertainen. Katsotaanpa pyyntö ymmärtääksesi, mitä tapahtuu.
3.1 FROM - mistä saamme tiedot
Tämä saattaa tuntua itsestään selvältä nyt, mutta FROM on erittäin tärkeä asia myöhemmin, kun pääsemme liittymisiin ja alakyselyihin.
FROM osoittaa taulukkoon, jota vastaan \u200b\u200bkysely tehdään. Tämä voi olla olemassa oleva taulukko (kuten yllä olevassa esimerkissä) tai taulukko, joka on luotu lennossa liitosten tai alakyselyjen kautta.
3.2 Missä - mitä tietoja näytetään
WHERE vain käyttäytyy kuin suodatin jousetjonka haluamme tuottaa. Meidän tapauksessamme haluamme nähdä vain ne rivit, joiden arvo kirjoittajasarakkeessa on “Dan Brown”.
3.3 SELECT - kuinka tiedot näytetään
Nyt kun meillä on kaikki tarvitsemamme taulukon sarakkeet, meidän on päätettävä, kuinka nämä tiedot näytetään. Meidän tapauksessamme tarvitaan vain kirjojen otsikot ja tunnisteet, joten me ja me valita painikkeella SELECT. Samalla voit nimetä sarakkeen uudelleen AS: n avulla.
Koko kysely voidaan visualisoida yksinkertaisella kaavalla:

4. Liitännät (liittymät)
Haluamme nyt nähdä kaikkien kirjastosta otettujen Dan Brownin kirjojen nimet (ei välttämättä ainutlaatuiset) ja kun nämä kirjat on palautettava:
VALITSE books.title AS "Otsikko", borrowings.returndate AS "Palautuspäivä" FROM lainauksista LIITY kirjoja ON lainanotto.bookid \u003d books.bookid WHERE books.author \u003d "Dan Brown";
Tulos:
| Otsikko | Palautuspäivä |
|---|---|
| Kadonnut symboli | 2016-03-23 00:00:00 |
| Inferno | 2016-04-13 00:00:00 |
| Kadonnut symboli | 2016-04-19 00:00:00 |
Suurimmaksi osaksi pyyntö on samanlainen kuin edellinen. lukuunottamatta Kohteista. Se tarkoittaa sitä pyydämme tietoja toisesta taulukosta... Emme käytä kirjoja tai lainataulukoita. Sen sijaan me käännymme uusi pöytäjoka luotiin yhdistämällä kaksi taulukkoa.
lainat JOIN books ON borrowings.bookid \u003d books.bookid on uusi taulukko, joka muodostettiin yhdistämällä kaikki "kirjat" - ja "lainat" -taulukoiden tietueet, joissa bookid-arvot ovat samat. Tällaisen yhdistämisen tulos on:

Ja sitten kysymme tästä taulukosta samalla tavalla kuin yllä olevassa esimerkissä. Tämä tarkoittaa, että liittyessäsi pöytiin sinun tarvitsee vain huolehtia siitä, kuinka liittyä siihen. Ja sitten pyyntö tulee yhtä selväksi kuin kohdassa 3 olevan "yksinkertaisen pyynnön" tapauksessa.
Yritetään hieman monimutkaisempaa kahden pöydän liittämistä.
Nyt haluamme saada niiden ihmisten nimet, jotka ovat ottaneet kirjailijan kirjasta "Dan Brown".
Tällä kertaa mennään alhaalta ylös:
Vaihe Vaihe 1 - mistä saamme tiedot? Saadaksesi haluamasi tuloksen meidän on liityttävä "jäsen" - ja "kirjat" -taulukoihin "lainat" -taulukon kanssa. JOIN-osio näyttää tältä:
lainat JOIN books ON lainanotto.bookid \u003d books.bookid JOIN-jäsenet ON jäsenet.memberid \u003d lainat.memberid
Yhteystulos näkyy linkistä.
Vaihe 2 - mitä tietoja näytämme? Olemme kiinnostuneita vain tiedoista, joissa kirjan kirjoittaja on “Dan Brown”
WHERE books.author \u003d "Dan Brown"
Vaihe 3 - miten tiedot näytetään? Nyt kun tiedot on vastaanotettu, sinun tarvitsee vain näyttää kirjojen ottaneiden nimi ja sukunimi:
VALITSE jäsenet.nimi AS "Etunimi", jäsenet.sukunimi AS "Sukunimi"
Super! On vain yhdistää kolme komponenttia ja tehdä tarvitsemamme pyyntö:
VALITSE jäsenet.sukunimi AS "Etunimi", jäsenet.sukunimi AS "Sukunimi" Lainanottoista LIITÄ kirjoja ON lainaa.bookid \u003d kirjat.bookid LIITY jäsenet ON jäsenet.memberid \u003d lainat.memberid WHERE books.author \u003d "Dan Brown";
Mikä antaa meille:
| Etunimi | Sukunimi |
|---|---|
| Mike | Willis |
| Ellen | Horton |
| Ellen | Horton |
Hieno! Mutta nimet toistetaan (ne eivät ole ainutlaatuisia). Korjaamme tämän pian.
5. Yhdistäminen
Karkeasti ottaen aggregaatteja tarvitaan monien rivien muuntamiseksi yhdeksi... Samaan aikaan aggregaation aikana eri sarakkeille käytetään erilaista logiikkaa.
Jatketaan esimerkkimme kanssa, jossa esiintyy kaksoiskappaleita. Voidaan nähdä, että Ellen Horton lainasi useampaa kuin yhtä kirjaa, mutta tämä ei ole paras tapa näyttää näitä tietoja. Toinen pyyntö voidaan tehdä:
VALITSE jäsenet.sukunimi AS "Etunimi", jäsenet.sukunimi AS "Sukunimi", lukumäärä (*) AS "Lainattujen kirjojen lukumäärä" Lainasta LISÄÄ JOIN kirjoja lainauksiin. .memberid WHERE books.author \u003d "Dan Brown" GROUP BY jäsenet.nimi, jäsenet.sukunimi;
Mikä antaa meille toivotun tuloksen:
| Etunimi | Sukunimi | Lainattujen kirjojen lukumäärä |
|---|---|---|
| Mike | Willis | 1 |
| Ellen | Horton | 2 |
Lähes kaikissa yhdistelmissä on GROUP BY -lauseke. Tämä asia muuttaa taulukon, jonka kysely voi noutaa, taulukkoryhmiksi. Jokainen ryhmä vastaa yksilöllistä arvoa (tai arvoryhmää) sarakkeelle, jonka määritimme GROUP BY -ryhmässä. Esimerkissämme muunnamme edellisen harjoituksen tuloksen riviryhmäksi. Yhdistämme myös laskennan, joka muuntaa useita rivejä kokonaisluvuksi (tapauksessamme tämä on rivien lukumäärä). Sitten tämä arvo määritetään kullekin ryhmälle.
Tuloksen kukin rivi on seurausta kunkin ryhmän aggregaatista.
Voit päätyä loogiseen johtopäätökseen, että kaikki tuloksen kentät on joko määriteltävä GROUP BY -ohjelmassa tai niille on suoritettava aggregaatio. Koska kaikki muut kentät voivat erota toisistaan \u200b\u200beri riveillä, ja jos valitset ne SELECT-painikkeella, ei ole selvää, mitkä mahdollisista arvoista tulisi ottaa.
Yllä olevassa esimerkissä laskutoiminto käsitteli kaikki rivit (koska laskimme rivien lukumäärää). Muut toiminnot, kuten summa tai max, käsittelevät vain määritetyt merkkijonot. Esimerkiksi, jos haluamme selvittää kunkin kirjoittajan kirjoittamien kirjojen määrän, tarvitsemme seuraavanlaisen kyselyn:
VALITSE kirjailija, summa (varastossa) FROM books GROUP BY kirjailija;
Tulos:
| kirjailija | summa |
|---|---|
| Robin Sharma | 4 |
| Dan ruskea | 6 |
| John vihreä | 3 |
| Amish tripathi | 2 |
Tässä summafunktio käsittelee vain varastosarakkeen ja laskee kaikkien ryhmien kaikkien arvojen summan.
6. Alakyselyt

Alakyselyt ovat tavallisia SQL-kyselyjä, jotka on upotettu suurempiin kyselyihin. Ne on jaettu kolmeen tyyppiin palautetun tuloksen tyypin mukaan.
6.1 Kaksiulotteinen taulukko
On kyselyjä, jotka palauttavat useita sarakkeita. Hyvä esimerkki on viimeisen aggregaatioharjoituksen kysely. Alihakuna se yksinkertaisesti palauttaa toisen taulukon, jota vastaan \u200b\u200bvoidaan tehdä uusia kyselyjä. Jatkamalla edellistä harjoitusta, jos haluamme selvittää "Robin Sharma" -kirjoittajan kirjoittamien kirjojen lukumäärän, yksi mahdollisista tavoista on käyttää alakyselyjä:
SELECT * FROM (SELECT tekijä, summa (varastossa) FROM kirjoista RYHMÄ tekijän mukaan) AS tulokset WHERE tekijä \u003d "Robin Sharma";
Tulos:
Voidaan kirjoittaa seuraavasti: ["Robin Sharma", "Dan Brown"]
2. Nyt käytämme tätä tulosta uudessa kyselyssä:
VALITSE otsikko, kirjanmerkki kirjoista WHERE author IN (VALITSE kirjailija FROM (SELECT kirjailija, summa (varastossa) FROM kirjoista RYHMÄ tekijän mukaan) AS tulokset WHERE summa\u003e 3);
Tulos:
| otsikko | bookid |
|---|---|
| Kadonnut symboli | 2 |
| Kuka itkee, kun kuolet? | 3 |
| Inferno | 4 |
Tämä on sama kuin:
VALITSE otsikko, kirjat FROM books WHERE kirjailija IN ("Robin Sharma", "Dan Brown");
6.3 Yksittäiset arvot
On kyselyitä, jotka johtavat vain yhteen riviin ja yhteen sarakkeeseen. Niitä voidaan käsitellä vakioarvoina ja niitä voidaan käyttää missä tahansa arvoja, kuten vertailuoperaattoreissa. Niitä voidaan käyttää myös kaksiulotteisina taulukoina tai yhden elementin matriiseina.
Otetaan esimerkiksi tietoja kaikista kirjoista, jotka ovat tällä hetkellä yli kirjaston keskiarvon.
Keskiarvo saadaan seuraavasti:
valitse keskim. (varastossa) kirjoista;
Mikä antaa meille:
7. Kirjoitustoiminnot
Useimmat tietokannan kirjoitukset ovat melko suoraviivaisia \u200b\u200bverrattuna monimutkaisempiin lukemiin.
7.1 Päivitys
UPDATE-kyselyn syntaksi on semanttisesti sama kuin luetun kyselyn. Ainoa ero on se, että SELECT-sarakkeiden valitsemisen sijaan asetamme SET-arvot.
Jos kaikki Dan Brownin kirjat menetetään, sinun on nollattava määrän arvo. Pyyntö tätä varten on seuraava:
PÄIVITÄ kirjat SET varastossa \u003d 0 WHERE tekijä \u003d "Dan Brown";
WHERE tekee saman kuin aiemmin: valitsee rivit. Lukemisen aikana käytetyn SELECTin sijaan käytämme nyt SET. Nyt sinun on kuitenkin määritettävä paitsi sarakkeen nimi myös tämän sarakkeen uusi arvo valituilla riveillä.
7.2 Poista
DELETE-kysely on vain SELECT- tai UPDATE-kysely ilman sarakkeiden nimiä. Vakavasti. Kuten SELECT ja UPDATE, WHERE-lauseke pysyy samana: se valitsee poistettavat rivit. Poistotoiminto tuhoaa koko rivin, joten ei ole järkevää määrittää erillisiä sarakkeita. Joten, jos päätämme olla nollaamatta Dan Brownin kirjojen määrää, mutta poistamme kaikki tietueet kokonaan, voimme tehdä seuraavan pyynnön:
POISTA kirjoista Missä kirjailija \u003d "Dan Brown";
7.3 Asenna
Ehkä ainoa asia, joka eroaa muun tyyppisistä kyselyistä, on INSERT. Muoto on:
INSERT INTO x (a, b, c) ARVOT (x, y, z);
Missä a, b, c ovat sarakkeiden nimet ja x, y ja z ovat näihin sarakkeisiin lisättävät arvot samassa järjestyksessä. Se on pohjimmiltaan se.
Katsotaanpa tiettyä esimerkkiä. Tässä on INSERT-kysely, joka täyttää koko "kirjat" -taulukon:
INSERT INTO books (bookid, title, author, published, stock) ARVOT (1, "Scion of Ikshvaku", "Amish Tripathi", "06-22-2015", 2), (2, "Kadonnut symboli", " Dan Brown "," 22.7.2010 ", 3), (3," Kuka itkee, kun kuolet? "," Robin Sharma "," 15.06.2006 ", 4), (4," Helvetti ") , "Dan Brown", "05.05.2014", 3), (5, "Vika tähdissämme", "John Green", "01-03-2015", 3);
8. Todentaminen
Olemme päässeet loppuun, ehdotan pienen testin. Katso tätä pyyntöä artikkelin alusta. Voitko selvittää sen? Yritä jakaa se SELECT-, FROM-, WHERE-, GROUP BY -lausekkeisiin ja tarkastele alakyselyjen yksittäisiä komponentteja.
Tässä se on luettavammassa muodossa:
VALITSE jäsenet. Etunimi || "" || members.lastname AS "Koko nimi" lainoista INNER JOIN jäsenet ON jäsenet.memberid \u003d lainat.memberid INNER JOIN kirjat ON books.bookid \u003d lainat.bookid WHERE lainat.bookid IN (SELECT bookid FROM books WHERE stock\u003e (SELECT keskim. (varastossa) ) Kirjoista)) RYHMÄ jäsenten mukaan. Etunimi, jäsenet.sukunimi;
Tämä kysely palauttaa luettelon ihmisistä, jotka ovat ostaneet kirjastosta kirjan, jonka kokonaismäärä on keskimääräistä suurempi.
Tulos:
| Koko nimi |
|---|
| Lida tyler |
Toivon, että onnistuit selvittämään sen ongelmitta. Mutta jos ei, kiitän kommenttejasi ja palautettasi, jotta voin parantaa tätä viestiä.
Tunnisteet: Lisää tageja
Taulukkolausekkeet alikyselyt nimetään ja niitä käytetään siellä, missä taulukon odotetaan olevan. Taulukkolausekkeita on kahden tyyppisiä:
johdetut taulukot;
yleistetyt taulukon ilmaisut.
Näitä kahta taulukolausekemuotoa käsitellään seuraavissa osioissa.
Johdetut taulukot
Johdettu taulukko on taulukon lauseke, joka sisältyy kyselyn FROM-lausekkeeseen. Johdettuja taulukoita voidaan käyttää, kun sarakkeiden aliakset eivät ole mahdollisia, koska SQL-kääntäjä käsittelee toisen käskyn ennen aliaksen tuntemista. Alla olevassa esimerkissä yritetään käyttää sarake-aliasta tilanteessa, jossa toinen lauseke käsitellään ennen aliaksen tuntemista:
KÄYTÄ näyteDb; VALITSE KUUKAUSI (EnterDate) enter_kuukaudeksi FROM Works_on GROUP BY enter_month;
Jos yrität suorittaa tämän kyselyn, saat seuraavan virhesanoman:
Viesti 207, taso 16, tila 1, rivi 5 Virheellinen sarakkeen nimi "enter_month". (Viesti 207: Taso 16, tila 1, rivi 5 Virheellinen sarakkeen nimi enter_month)
Virheen syy on se, että GROUP BY -lauseke käsitellään ennen siihen liittyvän SELECT-luettelon käsittelyä ja Enter_month -sarakkeen aliasta ei tunneta tätä ryhmää käsiteltäessä.
Tämä ongelma voidaan ratkaista käyttämällä johdettua taulukkoa, joka sisältää edellisen kyselyn (ilman GROUP BY -lauseketta), koska FROM-lause suoritetaan ennen GROUP BY -lauseketta:
KÄYTÄ näyteDb; SELECT enter_month FROM (SELECT MONTH (EnterDate) enter_month FROM Works_on) AS m GROUP BY enter_month;
Tämän kyselyn suorittamisen tulos on seuraava:
Tyypillisesti taulukon lauseke voidaan sijoittaa mihin tahansa SELECT-käskyyn, missä taulukon nimi saattaa näkyä. (Taulukko-lausekkeen tulos on aina taulukko tai erikoistapauksissa lauseke.) Seuraava esimerkki näyttää taulukko-lausekkeen käytön SELECT-käskyn Select-luettelossa:
Tämän kyselyn tulos:
Yleistetyt taulukon ilmaisut
Yhteinen taulukon ilmaisu (CTE) on nimetty taulukon lauseke, jota tukee Transact-SQL-kieli. Yleistettyjä taulukkolausekkeita käytetään seuraavissa kahdentyyppisissä kyselyissä:
ei-rekursiivinen;
rekursiivinen.
Näitä kahta pyyntötyyppiä käsitellään seuraavissa osioissa.
OTB ja ei-rekursiiviset kyselyt
Voit käyttää ei-rekursiivista OTB-lomaketta vaihtoehtona johdetuille taulukoille ja näkymille. Yleensä OTB määritellään lausekkeilla ja valinnainen kysely, joka viittaa WITH-lauseessa käytettyyn nimeen. WITH-avainsana on moniselitteinen Transact-SQL: ssä. Epäselvyyden välttämiseksi WITH-lauseketta edeltävä lause on lopetettava puolipisteellä.
KÄYTÄ AdventureWorks2012; SELECT SalesOrderID FROM Sales.SalesOrderHeader WHERE TotalDue\u003e (SELECT AVG (TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR (OrderDate) \u003d "2005") JA Freight\u003e (SELECT AVG (TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR / OrderDate 2005 ") 2,5;
Tämän esimerkin kysely valitsee tilaukset, joiden kokonaisverot (TotalDue) ovat suuremmat kuin kaikkien verojen keskiarvo ja joiden rahtikulut (rahti) ovat yli 40% verojen keskiarvosta. Tämän kyselyn pääominaisuus on sen määrä, koska alakysely on kirjoitettava kahdesti. Yksi mahdollinen tapa vähentää kyselyrakenteen kokoa on luoda näkymä, joka sisältää alikyselyn. Tämä ratkaisu on kuitenkin jonkin verran vaikea, koska se vaatii näkymän luomisen ja sen poistamisen kyselyn suorittamisen jälkeen. Paras tapa olisi luoda OTB. Alla oleva esimerkki osoittaa ei-rekursiivisen OTB: n käytön, joka lyhentää yllä olevaa kyselyn määritelmää:
KÄYTÄ AdventureWorks2012; WITH price_calc (vuosi_2005) AS (SELECT AVG (TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR (OrderDate) \u003d "2005") SELECT SalesOrderID FROM Sales.SalesOrderHeader WHERE TotalDue\u003e (SELECT year_2005 FROM price_calc) AND Fre2005) /2.5;
WITH-lausekkeen syntaksi ei-rekursiivisissa kyselyissä on:
Cte_name-parametri edustaa OTB-nimeä, joka määrittelee tuloksena olevan taulukon, ja column_list-parametri edustaa sarakkeiden luetteloa taulukon lausekkeessa. (Yllä olevassa esimerkissä OTB on nimeltään price_calc ja sillä on yksi sarake vuosi_2005.) Internal_query-parametri edustaa SELECT-käskyä, joka määrittelee vastaavan taulukko-lausekkeen tulosjoukon. Määritettyä taulukon lauseketta voidaan sitten käyttää ulkoisen kyselyn ulommassa kyselyssä. (Yllä olevan esimerkin ulompi kysely käyttää OTB price_calc -saraketta ja sen saraketta vuosi_2005 kaksinkertaisen sisäkkäisen kyselyn yksinkertaistamiseksi.)
OTB ja rekursiiviset kyselyt
Tässä osassa esitellään monimutkaisempaa materiaalia. Siksi, kun luet sitä ensimmäisen kerran, on suositeltavaa ohittaa se ja palata siihen myöhemmin. Rekursiot voidaan toteuttaa OTB: n kautta, koska OTB: t voivat sisältää viittauksia itseensä. Rekursiivisen kyselyn OTB-perussyntaksi näyttää tältä:
Parametreilla cte_name ja column_list on sama merkitys kuin OTB: ssä ei-rekursiivisille kyselyille. WITH-lauseke koostuu kahdesta operaattorin yhdistämästä kyselystä UNIONIN KAIKKI... Ensimmäistä kyselyä kutsutaan vain kerran, ja se alkaa kerätä rekursiotulosta. UNION ALL -operaattorin ensimmäinen operandi ei viittaa OTB: hen. Tätä kyselyä kutsutaan viitekyselyksi tai lähteeksi.
Toinen pyyntö sisältää linkin OTB: hen ja edustaa sen rekursiivista osaa. Tämän vuoksi sitä kutsutaan rekursiiviseksi jäseneksi. Ensimmäisessä rekursiivisen osan kutsussa OTB-viite edustaa viitekyselyn tulosta. Rekursiivinen jäsen käyttää kyselyn ensimmäisen kutsun tulosta. Tämän jälkeen järjestelmä kutsuu rekursiivisen osan uudelleen. Puhelu rekursiiviselle jäsenelle lopetetaan, kun edellinen puhelu sille palauttaa tyhjän tulosjoukon.
UNION ALL -operaattori yhdistää tällä hetkellä kertyneet merkkijonot sekä nykyisen puhelun rekursiiviselle jäsenelle lisäämät merkkijonot. (UNION ALL -operaattorin läsnäolo tarkoittaa, että kaksoisrivejä ei poisteta tuloksesta.)
Lopuksi parametri external_query määrittää ulkoisen kyselyn, joka käyttää OTB: tä saadakseen kaikki puhelut molempien jäsenten liittoon.
Rekursiivisen OTB-lomakkeen osoittamiseksi käytämme lentokonetaulukkoa, joka on määritelty ja täytetty alla olevassa esimerkissä esitetyllä koodilla:
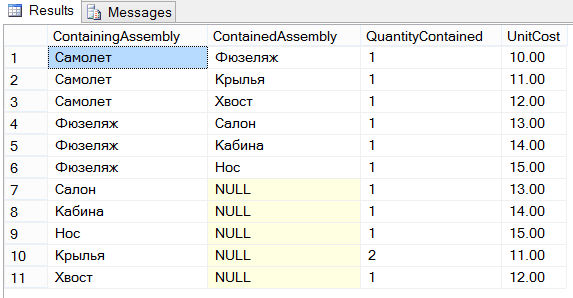
KÄYTÄ näyteDb; LUO TAULUKKO Lentokone (ContainingAssembly VARCHAR (10), ContainedAss Assembly VARCHAR (10), QuantityContained INT, UnitCost DECIMAL (6,2)); ASENNA Lentokoneen arvoihin ("Lentokone", "Runko", 1, 10); ASENNA Lentokoneen arvoihin ("Lentokone", "Siivet", 1, 11); ASENNA Lentokoneen arvoihin ("Lentokone", "Tail", 1, 12); LISÄÄ lentokoneen arvoihin ("Fuselage", "Salon", 1, 13); ASENNA Lentokoneen arvoihin ("Fuselage", "Cabin", 1, 14); ASENNA Lentokoneen arvoihin ("Fuselage", "Nose", 1, 15); LISÄÄ lentokoneen arvoihin ("Salon", NULL, 1.13); ASENNA Lentokoneen ARVOihin ("Hytti", NULL, 1, 14); LISÄÄ lentokoneen arvoihin ("Nenä", NULL, 1, 15); ASENNA Lentokoneen arvoihin ("Siivet", NULL, 2, 11); ASENNA Lentokoneen arvoihin ("Tail", NULL, 1, 12);
Lentopöydässä on neljä saraketta. ContainingAssembly-sarake tunnistaa kokoonpanon ja ContainedAssembly -sarake yksilöi osat (yksi toisensa jälkeen), jotka muodostavat vastaavan kokoonpanon. Alla olevassa kuvassa on graafinen kuva mahdollisesta lentotyypistä ja sen osista:

Lentopöytä koostuu seuraavista 11 rivistä:
Alla olevassa esimerkissä on WITH-lause, jota käytetään määritettäessä kysely, joka laskee kunkin kokoonpanon kokonaiskustannukset:
KÄYTÄ näyteDb; WITH list_of_parts (kokoonpano1, määrä, kustannukset) AS (SELECT ContainingAssembly, QuantityContained, UnitCost FROM Airplane WHERE ContainedAss kokoonpano on NULL UNION ALL SELECT a.ContainingAss Assembly, a.QuantityContained, CAST (l.quantity * l.cost AS DECIMAL ( ) FROM list_of_parts l, lentokone a WHERE l.assembly1 \u003d a.ContainedAssembly) SELECT assembly1 "Part", määrä "Qty", cost "Price" FROM list_of_parts;
WITH-lauseke määrittelee OTB-listan nimeltä list_of_parts, jossa on kolme saraketta: assembly1, määrä ja kustannukset. Esimerkin ensimmäistä SELECT-käskyä kutsutaan vain kerran rekursioprosessin ensimmäisen vaiheen tulosten säilyttämiseksi. Esimerkin viimeisen rivin SELECT-käsky näyttää seuraavan tuloksen.


