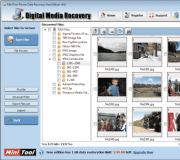
Tabel met ASCII-codes in binair systeem. Coderen van tekstinformatie
Hallo, beste lezers van de blogsite. Vandaag zullen we met je praten over waar krakozyabrs vandaan komen op een website en in programma's, welke tekstcoderingen er zijn en welke moeten worden gebruikt. Laten we de geschiedenis van hun ontwikkeling eens nader bekijken, beginnend bij de basis-ASCII, evenals de uitgebreide versies CP866, KOI8-R, Windows 1251 en eindigend met moderne Unicode-consortiumcoderingen UTF 16 en 8.
Voor sommigen lijkt deze informatie misschien overbodig, maar weet je hoeveel vragen ik specifiek ontvang over de kruipende krakozyabrs (onleesbare reeks karakters). Nu krijg ik de gelegenheid om iedereen naar de tekst van dit artikel te verwijzen en mijn eigen fouten te ontdekken. Maak je klaar om de informatie in je op te nemen en probeer de stroom van het verhaal te volgen.
ASCII - basistekstcodering voor het Latijnse alfabet
De ontwikkeling van tekstcoderingen vond gelijktijdig plaats met de vorming van de IT-industrie, en gedurende deze tijd slaagden ze erin behoorlijk wat veranderingen te ondergaan. Historisch gezien begon het allemaal met EBCDIC, dat nogal dissonant was in de Russische uitspraak, waardoor het mogelijk werd letters van het Latijnse alfabet, Arabische cijfers en leestekens te coderen met controletekens.
Maar toch moet het startpunt voor de ontwikkeling van moderne tekstcoderingen als beroemd worden beschouwd ASCII(Amerikaanse standaardcode voor informatie-uitwisseling, die in het Russisch gewoonlijk wordt uitgesproken als ‘aski’). Het beschrijft de eerste 128 tekens die het meest worden gebruikt door Engelssprekende gebruikers: Latijnse letters, Arabische cijfers en leestekens.
Deze 128 tekens die in ASCII worden beschreven, bevatten ook enkele servicetekens zoals haakjes, hekjes, sterretjes, enz. Sterker nog, je kunt ze zelf zien:
Het zijn deze 128 tekens uit de originele versie van ASCII die de standaard zijn geworden, en in elke andere codering zul je ze zeker vinden en ze zullen in deze volgorde verschijnen.
Maar feit is dat je met één byte aan informatie niet 128, maar maar liefst 256 verschillende waarden kunt coderen (twee tot de macht acht is gelijk aan 256), dus na de basisversie van Asuka een hele reeks uitgebreide ASCII-coderingen, waarin het naast 128 basistekens ook mogelijk was om symbolen van de nationale codering te coderen (bijvoorbeeld Russisch).
Hier is het waarschijnlijk de moeite waard om iets meer te zeggen over de nummersystemen die in de beschrijving worden gebruikt. Ten eerste werkt een computer, zoals jullie allemaal weten, alleen met getallen in het binaire systeem, namelijk met nullen en enen (“Booleaanse algebra”, als iemand dat op een instituut of school heeft gebruikt). , waarvan elk een twee tot de macht is, beginnend bij nul, en maximaal twee tot de zevende:

Het is niet moeilijk te begrijpen dat alle mogelijke combinaties van nullen en enen in een dergelijk ontwerp slechts 256 kunnen zijn. Het omzetten van een getal van het binaire systeem naar het decimale systeem is vrij eenvoudig. Je hoeft alleen maar alle machten van twee bij elkaar op te tellen met de enen erboven.
In ons voorbeeld blijkt dit 1 (2 tot de macht nul) plus 8 (twee tot de macht 3), plus 32 (twee tot de vijfde macht), plus 64 (tot de zesde macht), plus 128 te zijn. (tot de zevende macht). Het totaal is 233 in decimale notatie. Zoals je kunt zien, is alles heel eenvoudig.
Maar als je goed naar de tabel met ASCII-tekens kijkt, zul je zien dat ze in hexadecimale codering worden weergegeven. 'asterisk' komt bijvoorbeeld overeen met het hexadecimale getal 2A in Aski. U weet waarschijnlijk dat in het hexadecimale getalsysteem naast Arabische cijfers ook Latijnse letters van A (betekent tien) tot F (betekent vijftien) worden gebruikt.
Welnu, voor binair getal naar hexadecimaal converteren toevlucht nemen tot de volgende eenvoudige en voor de hand liggende methode. Elke byte aan informatie is verdeeld in twee delen van vier bits, zoals weergegeven in de bovenstaande schermafbeelding. Dat. In elke halve byte kunnen slechts zestien waarden (twee tot de vierde macht) binair worden gecodeerd, wat gemakkelijk kan worden weergegeven als een hexadecimaal getal.
Bovendien moeten in de linkerhelft van de byte de graden opnieuw worden geteld, beginnend bij nul, en niet zoals weergegeven in de schermafbeelding. Als resultaat krijgen we door eenvoudige berekeningen dat het getal E9 in de schermafbeelding is gecodeerd. Ik hoop dat de loop van mijn redenering en de oplossing van deze puzzel voor u duidelijk waren. Laten we nu verder gaan met praten over tekstcoderingen.
Uitgebreide versies van Asuka - CP866- en KOI8-R-coderingen met pseudografische afbeeldingen
Dus begonnen we te praten over ASCII, dat als het ware het startpunt was voor de ontwikkeling van alle moderne coderingen (Windows 1251, Unicode, UTF 8).
Aanvankelijk bevatte het slechts 128 tekens van het Latijnse alfabet, Arabische cijfers en iets anders, maar in de uitgebreide versie werd het mogelijk om alle 256 waarden te gebruiken die in één byte aan informatie kunnen worden gecodeerd. Die. Het werd mogelijk om symbolen van letters van uw taal aan Aski toe te voegen.
Hier zullen we opnieuw moeten afdwalen om uit te leggen - waarom hebben we überhaupt coderingen nodig? teksten en waarom het zo belangrijk is. De karakters op uw computerscherm worden gevormd op basis van twee dingen: sets vectorvormen (representaties) van verschillende karakters (ze bevinden zich in bestanden met ) en code waarmee u deze set vectorvormen (lettertypebestand ) precies het teken dat op de juiste plaats moet worden ingevoegd.
Het is duidelijk dat de lettertypen zelf verantwoordelijk zijn voor de vectorvormen, maar het besturingssysteem en de daarin gebruikte programma's zijn verantwoordelijk voor de codering. Die. elke tekst op uw computer bestaat uit een reeks bytes, die elk één enkel teken van deze tekst coderen.
Het programma dat deze tekst op het scherm weergeeft (teksteditor, browser, etc.) leest bij het parseren van de code de codering van het volgende teken en zoekt naar de bijbehorende vectorvorm in het benodigde lettertypebestand, dat is aangesloten om dit weer te geven tekstdocument. Alles is eenvoudig en banaal.
Dit betekent dat om elk teken dat we nodig hebben (bijvoorbeeld uit het nationale alfabet) te kunnen coderen, aan twee voorwaarden moet worden voldaan: de vectorvorm van dit teken moet in het gebruikte lettertype zijn en dit teken kan worden gecodeerd in uitgebreide ASCII-coderingen in één byte. Daarom zijn er een heleboel van dergelijke opties. Alleen al voor het coderen van tekens in de Russische taal zijn er verschillende varianten van uitgebreide Aska.
Oorspronkelijk verschenen bijvoorbeeld CP866, dat de mogelijkheid had om tekens uit het Russische alfabet te gebruiken en een uitgebreide versie van ASCII was.
Die. het bovenste gedeelte viel volledig samen met de basisversie van Aska (128 Latijnse karakters, cijfers en andere onzin), die wordt weergegeven in de schermafbeelding hierboven, maar het onderste deel van de tabel met CP866-codering zag er zo uit als aangegeven in de schermafdruk eronder en stond je toe nog eens 128 tekens te coderen (Russische letters en allerlei pseudografische tekens):

Zie je, in de rechterkolom beginnen de cijfers met 8, omdat... getallen van 0 tot 7 verwijzen naar het basisgedeelte van ASCII (zie eerste screenshot). Dat. De Russische letter "M" in CP866 heeft de code 9C (deze bevindt zich op het snijpunt van de overeenkomstige rij met 9 en kolom met het getal C in het hexadecimale getalsysteem), die in één byte aan informatie kan worden geschreven, en als er een geschikt lettertype met Russische karakters is, zal deze letter zonder problemen in de tekst verschijnen.
Waar kwam dit bedrag vandaan? pseudografische afbeeldingen in CP866? Het hele punt is dat deze codering voor Russische tekst werd ontwikkeld in die ruige jaren, toen grafische besturingssystemen nog niet zo wijdverspreid waren als nu. En in Dosa en soortgelijke tekstbesturingssystemen maakten pseudografische afbeeldingen het mogelijk om op zijn minst op de een of andere manier het ontwerp van teksten te diversifiëren, en daarom zijn CP866 en al zijn andere collega's uit de categorie van uitgebreide versies van Asuka er in overvloed aanwezig.
CP866 werd gedistribueerd door IBM, maar daarnaast is er een aantal coderingen ontwikkeld voor karakters in de Russische taal. Hetzelfde type (uitgebreide ASCII) kan bijvoorbeeld worden toegeschreven KOI8-R:

Het werkingsprincipe blijft hetzelfde als dat van de CP866 die iets eerder werd beschreven: elk tekstteken wordt gecodeerd door één enkele byte. De schermafbeelding toont de tweede helft van de KOI8-R-tabel, omdat de eerste helft komt volledig overeen met de basis Asuka, die te zien is in de eerste screenshot van dit artikel.
Onder de kenmerken van de KOI8-R-codering kan worden opgemerkt dat de Russische letters in de tabel niet in alfabetische volgorde staan, zoals bijvoorbeeld in CP866.
Als je naar de allereerste schermafbeelding kijkt (van het basisgedeelte, dat is opgenomen in alle uitgebreide coderingen), zul je merken dat in KOI8-R Russische letters zich in dezelfde cellen van de tabel bevinden als de overeenkomstige letters van het Latijnse alfabet uit het eerste deel van de tabel. Dit werd gedaan voor het gemak van het overschakelen van Russische naar Latijnse karakters door slechts één bit weg te gooien (twee tot de zevende macht of 128).
Windows 1251 - de moderne versie van ASCII en waarom de scheuren naar buiten komen
De verdere ontwikkeling van tekstcoderingen was te danken aan het feit dat grafische besturingssystemen aan populariteit wonnen en de noodzaak om daarin pseudografische afbeeldingen te gebruiken in de loop van de tijd verdween. Als gevolg hiervan ontstond een hele groep die in wezen nog steeds uitgebreide versies van Asuka waren (één tekstteken is gecodeerd met slechts één byte aan informatie), maar zonder het gebruik van pseudografische symbolen.
Ze behoorden tot de zogenaamde ANSI-coderingen, die waren ontwikkeld door het American Standards Institute. In het gewone taalgebruik werd de naam Cyrillisch ook gebruikt voor de versie met ondersteuning voor de Russische taal. Een voorbeeld hiervan zou zijn.
Het verschilde gunstig van de eerder gebruikte CP866 en KOI8-R doordat de plaats van pseudografische symbolen daarin werd ingenomen door de ontbrekende symbolen van de Russische typografie (behalve het accentteken), evenals door symbolen die in Slavische talen werden gebruikt die dicht bij Russisch (Oekraïens, Wit-Russisch, enz.):

Vanwege zo'n overvloed aan Russische taalcoderingen hadden lettertypefabrikanten en softwarefabrikanten voortdurend hoofdpijn, en jij en ik, beste lezers, kregen vaak diezelfde beruchte krakozyabry toen er verwarring ontstond met de versie die in de tekst werd gebruikt.
Heel vaak kwamen ze naar buiten bij het verzenden en ontvangen van berichten per e-mail, wat de creatie van zeer complexe conversietabellen met zich meebracht, die dit probleem in feite niet fundamenteel konden oplossen, en gebruikers gebruikten vaak voor correspondentie om de beruchte trucs te vermijden bij het gebruik Russische coderingen zoals CP866, KOI8-R of Windows 1251.
In feite waren de scheuren die verschenen in plaats van de Russische tekst het gevolg van onjuist gebruik van de codering van deze taal, die niet overeenkwam met de taal waarin het sms-bericht oorspronkelijk was gecodeerd.
Laten we zeggen dat als u tekens probeert weer te geven die zijn gecodeerd met CP866 met behulp van de Windows 1251-codetabel, ditzelfde gebrabbel (een betekenisloze reeks tekens) naar buiten zal komen, waardoor de tekst van het bericht volledig wordt vervangen.

Een soortgelijke situatie doet zich heel vaak voor op forums of blogs, wanneer tekst met Russische karakters per ongeluk wordt opgeslagen in de verkeerde codering die standaard op de site wordt gebruikt, of in de verkeerde teksteditor, die grappen aan de code toevoegt die niet zichtbaar zijn voor het blote oog.
Uiteindelijk werden veel mensen deze situatie met veel coderingen en voortdurend kruipende onzin beu, en de voorwaarden verschenen voor de creatie van een nieuwe universele variant die alle bestaande zou vervangen en uiteindelijk het probleem met het uiterlijk zou oplossen van onleesbare teksten. Daarnaast was er het probleem van talen als het Chinees, waar er veel meer taalkarakters waren dan 256.
Unicode - universele coderingen UTF 8, 16 en 32
Deze duizenden karakters van de Zuidoost-Aziatische taalgroep konden onmogelijk worden beschreven in één byte aan informatie die was toegewezen voor het coderen van karakters in uitgebreide versies van ASCII. Als gevolg hiervan ontstond een consortium genaamd Unicode(Unicode - Unicode Consortium) met de medewerking van veel leiders in de IT-industrie (degenen die software produceren, hardware coderen, lettertypen maken), die geïnteresseerd waren in de opkomst van een universele tekstcodering.
De eerste variant die onder auspiciën van het Unicode Consortium werd uitgebracht was UTF32. Het getal in de coderingsnaam betekent het aantal bits dat wordt gebruikt om één teken te coderen. 32 bits zijn gelijk aan 4 bytes aan informatie die nodig zijn om één enkel teken te coderen in de nieuwe universele UTF-codering.
Als gevolg hiervan zal hetzelfde bestand met tekst gecodeerd in de uitgebreide versie van ASCII en in UTF-32, in het laatste geval, vier keer groter zijn (wegen). Dit is slecht, maar nu hebben we de mogelijkheid om met behulp van YTF een aantal tekens te coderen dat gelijk is aan twee tot de macht van tweeëndertig ( miljarden karakters, die elke echt noodzakelijke waarde met een kolossale marge zal dekken).
Maar veel landen met talen van de Europese groep hoefden helemaal niet zo'n groot aantal tekens te gebruiken bij het coderen, maar bij gebruik van UTF-32 kregen ze zonder enige reden een viervoudige toename van het gewicht van tekstdocumenten, en als gevolg daarvan een toename van het volume van het internetverkeer en het volume van de opgeslagen gegevens. Dit is veel, en niemand kan zich zo'n verspilling veroorloven.
Als gevolg van de ontwikkeling van Unicode, UTF-16, dat zo succesvol bleek te zijn dat het standaard werd overgenomen als basisruimte voor alle tekens die we gebruiken. Het gebruikt twee bytes om één teken te coderen. Laten we eens kijken hoe dit ding eruit ziet.
In het Windows-besturingssysteem kunt u het pad "Start" - "Programma's" - "Accessoires" - "Systeemwerkset" - "Tekentabel" volgen. Als gevolg hiervan wordt een tabel geopend met de vectorvormen van alle lettertypen die op uw systeem zijn geïnstalleerd. Als u de Unicode-tekenset selecteert in de “Geavanceerde opties”, kunt u voor elk lettertype afzonderlijk het volledige scala aan tekens zien dat erin zit.
Trouwens, door op een van deze te klikken, kun je de twee bytes ervan zien code in UTF-16-formaat, bestaande uit vier hexadecimale cijfers:

Hoeveel tekens kunnen in UTF-16 worden gecodeerd met 16 bits? 65.536 (twee tot de macht zestien), en dit is het getal dat werd aangenomen als de basisruimte in Unicode. Bovendien zijn er manieren om er ongeveer twee miljoen tekens mee te coderen, maar deze waren beperkt tot een uitgebreide ruimte van een miljoen tekens tekst.
Maar zelfs deze succesvolle versie van de Unicode-codering bracht niet veel voldoening voor degenen die bijvoorbeeld programma's alleen in het Engels schreven, omdat voor hen, na de overgang van de uitgebreide versie van ASCII naar UTF-16, het gewicht van de documenten verdubbelde ( één byte per teken in Aski en twee bytes voor hetzelfde teken in YUTF-16).
Juist om iedereen en alles in het Unicode-consortium tevreden te stellen, werd besloten om op de proppen te komen codering met variabele lengte. Het heette UTF-8. Ondanks de acht in de naam heeft het eigenlijk een variabele lengte, d.w.z. Elk tekstteken kan worden gecodeerd in een reeks van één tot zes bytes lang.
In de praktijk gebruikt UTF-8 alleen het bereik van één tot vier bytes, omdat het verder dan vier bytes aan code zelfs theoretisch niet meer mogelijk is om iets voor te stellen. Alle Latijnse karakters daarin zijn gecodeerd in één byte, net als in de goede oude ASCII.
Wat opmerkelijk is, is dat in het geval van het coderen van alleen het Latijnse alfabet, zelfs programma's die Unicode niet begrijpen, nog steeds zullen lezen wat er in YTF-8 is gecodeerd. Die. het kerngedeelte van Asuka werd eenvoudigweg overgebracht naar deze oprichting van het Unicode-consortium.
Cyrillische tekens in UTF-8 worden gecodeerd in twee bytes, en Georgische tekens worden bijvoorbeeld gecodeerd in drie bytes. Het Unicode Consortium heeft, na het creëren van UTF 16 en 8, het grootste probleem opgelost - nu hebben we dat gedaan lettertypen hebben een enkele coderuimte. En nu kunnen hun fabrikanten het alleen vullen met vectorvormen van teksttekens op basis van hun sterke punten en mogelijkheden. Nu komen ze zelfs in sets.
In de “Tekenstabel” hierboven kun je zien dat verschillende lettertypen verschillende aantallen tekens ondersteunen. Sommige Unicode-rijke lettertypen kunnen behoorlijk zwaar zijn. Maar nu verschillen ze niet doordat ze voor verschillende coderingen zijn gemaakt, maar doordat de lettertypefabrikant de enkele coderuimte wel of niet volledig heeft gevuld met bepaalde vectorvormen.
Gekke woorden in plaats van Russische letters - hoe je dit kunt oplossen
Laten we nu kijken hoe krakozyabrs verschijnen in plaats van tekst, of, met andere woorden, hoe de juiste codering voor Russische tekst wordt geselecteerd. Eigenlijk wordt het ingesteld in het programma waarin u deze tekst maakt of bewerkt, of codeert met behulp van tekstfragmenten.
Voor het bewerken en maken van tekstbestanden gebruik ik persoonlijk een naar mijn mening zeer goed . Het kan echter de syntaxis van honderden andere programmeer- en opmaaktalen benadrukken, en heeft ook de mogelijkheid om uit te breiden met plug-ins. Lees een gedetailleerd overzicht van dit prachtige programma via de meegeleverde link.
In het bovenste menu van Notepad++ bevindt zich een item “Coders”, waar u de mogelijkheid heeft om een bestaande optie om te zetten naar de optie die standaard op uw site wordt gebruikt:

In het geval van een site op Joomla 1.5 en hoger, evenals in het geval van een blog op WordPress, moet u de optie selecteren om de schijn van scheuren te voorkomen UTF 8 zonder stuklijst. Wat is het stuklijstvoorvoegsel?
Feit is dat toen ze de YUTF-16-codering aan het ontwikkelen waren, ze om de een of andere reden besloten om er zoiets aan toe te voegen als de mogelijkheid om de tekencode zowel in directe volgorde (bijvoorbeeld 0A15) als in omgekeerde volgorde (150A) te schrijven. . En zodat programma's precies konden begrijpen in welke volgorde de codes moesten worden gelezen, werd het uitgevonden BOM(Byte Order Mark of, met andere woorden, handtekening), wat tot uiting kwam in het toevoegen van drie extra bytes aan het begin van de documenten.
In de UTF-8-codering waren geen BOM's voorzien in het Unicode-consortium, en daarom verhindert het toevoegen van een handtekening (die beruchte extra drie bytes aan het begin van het document) eenvoudigweg dat sommige programma's de code kunnen lezen. Daarom moeten we bij het opslaan van bestanden in UTF altijd de optie zonder stuklijst (zonder handtekening) selecteren. Je bent dus op voorhand bescherm jezelf tegen kruipende krakozyabrs.
Opmerkelijk is dat sommige programma's in Windows dit niet kunnen (ze kunnen geen tekst opslaan in UTF-8 zonder een stuklijst), bijvoorbeeld hetzelfde beruchte Windows Kladblok. Het slaat het document op in UTF-8, maar voegt nog steeds de handtekening (drie extra bytes) toe aan het begin ervan. Bovendien zullen deze bytes altijd hetzelfde zijn: lees de code in directe volgorde. Maar op servers kan vanwege dit kleine ding een probleem ontstaan: er zullen boeven naar buiten komen.
Daarom onder geen beding Gebruik geen gewoon Windows-kladblok om documenten op uw site te bewerken als u niet wilt dat er scheuren verschijnen. Ik beschouw de reeds genoemde Notepad++-editor als de beste en eenvoudigste optie, die vrijwel geen nadelen heeft en alleen uit voordelen bestaat.
Wanneer u in Notepad++ een codering selecteert, heeft u de mogelijkheid om tekst te converteren naar UCS-2-codering, die qua aard zeer dicht bij de Unicode-standaard ligt. Ook in Kladblok zal het mogelijk zijn om tekst in ANSI te coderen, d.w.z. met betrekking tot de Russische taal zal dit Windows 1251 zijn, die we hierboven al hebben beschreven. Waar komt deze informatie vandaan?
Het wordt geregistreerd in het register van uw Windows-besturingssysteem - welke codering u moet kiezen in het geval van ANSI, welke u moet kiezen in het geval van OEM (voor de Russische taal zal dit CP866 zijn). Als u een andere standaardtaal op uw computer instelt, worden deze coderingen vervangen door soortgelijke coderingen uit de ANSI- of OEM-categorie voor diezelfde taal.
Nadat u het document in Notepad++ heeft opgeslagen in de codering die u nodig heeft of nadat u het document vanaf de site hebt geopend om te bewerken, kunt u de naam ervan in de rechter benedenhoek van de editor zien:
Om rednecks te voorkomen Naast de hierboven beschreven acties is het handig om informatie over deze codering in de header van de broncode van alle pagina's van de site te schrijven, zodat er geen verwarring ontstaat op de server of de lokale host.
Over het algemeen gebruiken alle hypertext-opmaaktalen behalve HTML een speciale xml-declaratie, die de tekstcodering specificeert.
Voordat de code wordt geparseerd, weet de browser welke versie wordt gebruikt en hoe hij de tekencodes van die taal precies moet interpreteren. Maar wat opmerkelijk is, is dat als u het document opslaat in de standaard Unicode, deze xml-declaratie kan worden weggelaten (de codering wordt beschouwd als UTF-8 als er geen stuklijst is, of als UTF-16 als er wel een stuklijst is).
In het geval van een HTML-taaldocument wordt de codering gebruikt om aan te geven Meta-element, dat is geschreven tussen de openings- en sluitingstag Head:
... ...
Deze inzending verschilt behoorlijk van de inzending, maar is volledig in overeenstemming met de nieuwe Html 5-standaard die langzaam wordt geïntroduceerd, en zal volledig correct worden begrepen door alle browsers die momenteel worden gebruikt.
In theorie zou het beter zijn om een Meta-element te plaatsen dat de codering van het HTML-document aangeeft zo hoog mogelijk in de documentkop zodat de browser op het moment dat hij het eerste teken in de tekst tegenkomt, niet afkomstig van de basis-ANSI (die altijd correct en in elke variatie wordt gelezen), al informatie zou moeten hebben over hoe de codes van deze tekens moeten worden geïnterpreteerd.
Veel succes! Tot binnenkort op de pagina's van de blogsite
Je kunt meer video's bekijken door naar te gaan");">

Misschien ben je geïnteresseerd
 Wat zijn URL-adressen, hoe verschillen absolute en relatieve links voor een site?
Wat zijn URL-adressen, hoe verschillen absolute en relatieve links voor een site?  OpenServer - een moderne lokale server en een voorbeeld van hoe u deze kunt gebruiken om WordPress op een computer te installeren
OpenServer - een moderne lokale server en een voorbeeld van hoe u deze kunt gebruiken om WordPress op een computer te installeren  Wat is Chmod, welke rechten moet je toewijzen aan bestanden en mappen (777, 755, 666) en hoe doe je dat via PHP
Wat is Chmod, welke rechten moet je toewijzen aan bestanden en mappen (777, 755, 666) en hoe doe je dat via PHP  Yandex zoeken op site en online winkel
Yandex zoeken op site en online winkel
Om ASCII correct te kunnen gebruiken, is het noodzakelijk om uw kennis op dit gebied en over codeermogelijkheden uit te breiden.
Wat het is?
ASCII is een coderingstabel van afgedrukte karakters (zie screenshot nr. 1) die op een computertoetsenbord worden getypt om informatie en enkele codes te verzenden. Met andere woorden: het alfabet en de decimale cijfers worden gecodeerd in overeenkomstige symbolen die de noodzakelijke informatie vertegenwoordigen en bevatten.
ASCII is ontwikkeld in Amerika, dus de standaardtekenset bevat meestal het Engelse alfabet met cijfers, voor een totaal van ongeveer 128 tekens. Maar dan rijst er een terechte vraag: wat te doen als codering van het nationale alfabet vereist is?
Er zijn andere versies van de ASCII-tabel ontwikkeld om soortgelijke problemen aan te pakken. Voor talen met een vreemde structuur zijn bijvoorbeeld de letters van het Engelse alfabet verwijderd of zijn er extra tekens aan toegevoegd in de vorm van een nationaal alfabet. De ASCII-codering kan dus Russische letters bevatten voor nationaal gebruik (zie screenshot nr. 2).

Waar wordt het ASCII-coderingssysteem gebruikt?
Dit coderingssysteem is niet alleen nodig voor het typen van tekstinformatie op het toetsenbord. Het wordt ook gebruikt in grafische afbeeldingen. In het ASCII Art Maker-programma bestaan grafische afbeeldingen van verschillende extensies bijvoorbeeld uit een reeks ASCII-tekens (zie screenshot nr. 3).

In de regel kunnen dergelijke programma's worden onderverdeeld in programma's die de functie van grafische editors vervullen, waarbij een afbeelding in tekst wordt omgezet, en programma's die een afbeelding in ASCII-afbeeldingen converteren. De bekende emoticon (of zoals deze ook wel “ lachend menselijk gezicht") is ook een voorbeeld van een coderingsteken.
Deze coderingsmethode kan ook worden gebruikt bij het schrijven of maken van een HTML-document. U voert bijvoorbeeld een specifieke en noodzakelijke reeks tekens in en wanneer u de pagina zelf bekijkt, wordt het symbool dat met deze code overeenkomt op het scherm weergegeven.
Dit type codering is onder meer nodig bij het maken van een meertalige website, omdat tekens die niet in een of andere nationale tabel voorkomen, moeten worden vervangen door ASCII-codes. Als de lezer rechtstreeks verbonden is met informatie- en communicatietechnologieën (ICT), dan zal het voor hem nuttig zijn om vertrouwd te raken met systemen als:
- Draagbare tekenset;
- Controlekarakters;
- EBCDIC;
- VISCII;
- YUSCII;
- Unicode;
- ASCII-kunst;
- KOI-8.
ASCII-tabeleigenschappen
Zoals elk systematisch programma heeft ASCII zijn eigen karakteristieke eigenschappen. Het decimale getalsysteem (cijfers van 0 tot en met 9) wordt dus bijvoorbeeld geconverteerd naar het binaire getalsysteem (dat wil zeggen, elk decimaal cijfer wordt respectievelijk geconverteerd naar binair 288 = 1001000).
De letters in de bovenste en onderste kolommen verschillen slechts een beetje van elkaar, wat de complexiteit van het controleren en bewerken van de casus aanzienlijk vermindert.
Met al deze eigenschappen werkt ASCII-codering als 8-bits, hoewel het oorspronkelijk bedoeld was als 7-bits.
Gebruik van ASCII in Microsoft Office-programma's:
Indien nodig kan deze optie voor het coderen van informatie worden gebruikt in Microsoft Notepad en Microsoft Office Word. Binnen deze toepassingen kan het document in ASCII-formaat worden opgeslagen, maar in dit geval kunt u bepaalde functies niet gebruiken bij het typen van tekst.
In het bijzonder zullen vetgedrukte en vetgedrukte gegevens niet beschikbaar zijn omdat codering alleen de betekenis van de getypte informatie behoudt, en niet het algemene uiterlijk en de vorm. U kunt dergelijke codes aan een document toevoegen met behulp van de volgende softwaretoepassingen:
- Microsoft Excel;
- Microsoft FrontPage;
- Microsoft InfoPath;
- Microsoft OneNote;
- Microsoft Outlook;
- Microsoft PowerPoint;
- Microsoft-project.
Het is de moeite waard om te overwegen dat u bij het typen van ASCII-code in deze toepassingen de ALT-toets ingedrukt moet houden.
Natuurlijk vereisen alle noodzakelijke codes een langer en gedetailleerder onderzoek, maar dit valt buiten het bestek van ons artikel van vandaag. Ik hoop dat je het erg nuttig vond.
Tot ziens!
Goed slecht
Unicode (Unicode in het Engels) is een tekencoderingsstandaard. Simpel gezegd is dit een tabel met correspondentie tussen teksttekens (, letters, interpunctie-elementen) binaire codes. De computer begrijpt alleen de volgorde van nullen en enen. Om ervoor te zorgen dat hij weet wat hij precies op het scherm moet weergeven, is het noodzakelijk om elk personage een eigen uniek nummer te geven. In de jaren tachtig werden karakters gecodeerd in één byte, dat wil zeggen acht bits (elke bit is een 0 of 1). Het bleek dus dat één tabel (ook wel codering of set genoemd) slechts 256 tekens kan bevatten. Zelfs voor één taal is dit misschien niet voldoende. Daarom verschenen er veel verschillende coderingen, waardoor verwarring vaak leidde tot vreemd gebrabbel op het scherm in plaats van leesbare tekst. Er was één enkele standaard nodig, namelijk Unicode. De meest gebruikte codering is UTF-8 (Unicode Transformation Format), waarbij 1 tot 4 bytes worden gebruikt om een teken weer te geven.
Symbolen
Tekens in Unicode-tabellen zijn genummerd met hexadecimale getallen. De Cyrillische hoofdletter M wordt bijvoorbeeld aangeduid met U+041C. Dit betekent dat het op het snijpunt van rij 041 en kolom C staat. Je kunt het eenvoudig kopiëren en vervolgens ergens plakken. Om niet door een lijst van meerdere kilometers te snuffelen, moet u de zoekopdracht gebruiken. Wanneer u naar de symboolpagina gaat, ziet u het Unicode-nummer en hoe het in verschillende lettertypen is geschreven. U kunt het bord zelf in de zoekbalk invoeren, zelfs als er in plaats daarvan een vierkant wordt getekend, om er tenminste achter te komen wat het was. Ook zijn er op deze site speciale (en willekeurige) sets van hetzelfde type iconen, verzameld uit verschillende secties, voor gebruiksgemak.
De Unicode-standaard is internationaal. Het bevat personages uit bijna alle scripts van de wereld. Inclusief de apparaten die niet meer worden gebruikt. Egyptische hiërogliefen, Germaanse runen, Maya-schrift, spijkerschrift en alfabetten van oude staten. Benamingen van maten en gewichten, muzieknotatie en wiskundige concepten worden ook gepresenteerd.
Het Unicode Consortium bedenkt zelf geen nieuwe karakters. De iconen die hun nut vinden in de samenleving worden aan de tabellen toegevoegd. Het roebelteken werd bijvoorbeeld zes jaar lang actief gebruikt voordat het aan Unicode werd toegevoegd. Emoji-pictogrammen (emoticons) werden ook voor het eerst veel gebruikt in Japan voordat ze in de codering werden opgenomen. Maar handelsmerken en bedrijfslogo’s worden in principe niet toegevoegd. Zelfs gewone exemplaren als de Apple-appel of de Windows-vlag. Tot op heden zijn ongeveer 120.000 tekens gecodeerd in versie 8.0.
De set tekens waarmee tekst wordt geschreven, wordt aangeroepen alfabet.
Het aantal tekens in het alfabet is het aantal stroom.
Formule voor het bepalen van de hoeveelheid informatie: N=2b,
waarbij N de macht van het alfabet is (aantal tekens),
b – aantal bits (informatiegewicht van het symbool).
Het alfabet met een capaciteit van 256 tekens kan bijna alle benodigde tekens bevatten. Dit alfabet heet voldoende.
Omdat 256 = 2 8, dan is het gewicht van 1 teken 8 bits.
De maateenheid 8 bits kreeg de naam 1 byte:
1 byte = 8 bits.
De binaire code van elk teken in computertekst neemt 1 byte geheugen in beslag.
Hoe wordt tekstinformatie weergegeven in het computergeheugen?
Het gemak van byte-voor-byte tekencodering ligt voor de hand omdat een byte het kleinste adresseerbare deel van het geheugen is en daarom de processor elk teken afzonderlijk kan benaderen bij het verwerken van tekst. Aan de andere kant is 256 tekens ruim voldoende om een grote verscheidenheid aan symbolische informatie weer te geven.
Nu rijst de vraag welke acht-bits binaire code aan elk teken moet worden toegewezen.
Het is duidelijk dat dit een voorwaardelijke kwestie is; je kunt veel coderingsmethoden bedenken.
Alle tekens van het computeralfabet zijn genummerd van 0 tot 255. Elk getal komt overeen met een acht-bits binaire code van 00000000 tot 11111111. Deze code is eenvoudigweg het serienummer van het teken in het binaire getalsysteem.
Een tabel waarin aan alle tekens van het computeralfabet serienummers zijn toegewezen, wordt een coderingstabel genoemd.
Verschillende typen computers gebruiken verschillende coderingstabellen.
De tafel is de internationale standaard voor pc's geworden ASCII(lees aski) (Amerikaanse standaardcode voor informatie-uitwisseling).
De ASCII-codetabel is verdeeld in twee delen.
Alleen de eerste helft van de tabel is de internationale standaard, d.w.z. symbolen met cijfers van 0 (00000000), tot 127 (01111111).
ASCII-coderingstabelstructuur
Serienummer |
Code |
Symbool |
0 - 31 |
00000000 - 00011111 |
Symbolen met cijfers van 0 tot en met 31 worden gewoonlijk controlesymbolen genoemd. |
32 - 127 |
00100000 - 01111111 |
Standaard onderdeel van de tafel (Engels). Dit omvat kleine letters en hoofdletters van het Latijnse alfabet, decimale cijfers, leestekens, allerlei soorten haakjes, commerciële en andere symbolen. |
128 - 255 |
10000000 - 11111111 |
Alternatief deel van de tabel (Russisch). |
Eerste helft van de ASCII-codetabel
 |
Houd er rekening mee dat in de coderingstabel de letters (hoofdletters en kleine letters) in alfabetische volgorde zijn gerangschikt en de cijfers in oplopende volgorde. Deze naleving van de lexicografische volgorde bij de rangschikking van symbolen wordt het principe van sequentiële codering van het alfabet genoemd.
Voor letters van het Russische alfabet wordt ook het principe van sequentiële codering in acht genomen.
Tweede helft van de ASCII-codetabel

Helaas zijn er momenteel vijf verschillende Cyrillische coderingen (KOI8-R, Windows, MS-DOS, Macintosh en ISO). Hierdoor ontstaan er vaak problemen bij het overbrengen van Russische tekst van de ene computer naar de andere, van het ene softwaresysteem naar het andere.
Chronologisch gezien was KOI8 ("Information Exchange Code, 8-bit") een van de eerste standaarden voor het coderen van Russische letters op computers. Deze codering werd al in de jaren zeventig gebruikt op computers uit de ES-computerserie en vanaf het midden van de jaren tachtig werd deze gebruikt in de eerste Russified-versies van het UNIX-besturingssysteem.
Vanaf het begin van de jaren negentig, de tijd van dominantie van het MS DOS-besturingssysteem, blijft de CP866-codering bestaan ("CP" betekent "Code Page", "code page").
Apple-computers met het Mac OS-besturingssysteem gebruiken hun eigen Mac-codering.
Bovendien heeft de International Standards Organization (ISO) een andere codering goedgekeurd, genaamd ISO 8859-5, als standaard voor de Russische taal.
De meest gebruikte codering is Microsoft Windows, afgekort CP1251.
Sinds eind jaren negentig is het probleem van het standaardiseren van tekencodering opgelost door de introductie van een nieuwe internationale standaard genaamd Unicode. Dit is een 16-bits codering, d.w.z. het wijst voor elk teken 2 bytes geheugen toe. Dit verhoogt natuurlijk de hoeveelheid geheugen die in beslag wordt genomen met 2 keer. Maar in een dergelijke codetabel kunnen maximaal 65536 tekens worden opgenomen. De volledige specificatie van de Unicode-standaard omvat alle bestaande, uitgestorven en kunstmatig gecreëerde alfabetten van de wereld, evenals vele wiskundige, muzikale, chemische en andere symbolen.
Laten we proberen een ASCII-tabel te gebruiken om ons voor te stellen hoe woorden er in het geheugen van de computer uit zullen zien.
Interne representatie van woorden in computergeheugen
Soms komt het voor dat een tekst bestaande uit letters van het Russische alfabet, ontvangen van een andere computer, niet kan worden gelezen - er is een soort "abracadabra" zichtbaar op het beeldscherm. Dit gebeurt omdat computers verschillende tekencoderingen gebruiken voor de Russische taal.
[8-bit coderingen: ASCII, KOI-8R en CP1251] De eerste coderingstabellen die in de Verenigde Staten werden gemaakt, gebruikten niet de achtste bit in een byte. De tekst werd weergegeven als een reeks bytes, maar er werd geen rekening gehouden met de achtste bit (deze werd gebruikt voor officiële doeleinden).
De tafel is een algemeen aanvaarde standaard geworden ASCII(Amerikaanse standaardcode voor informatie-uitwisseling). De eerste 32 tekens van de ASCII-tabel (00 tot 1F) werden gebruikt voor niet-afdrukbare tekens. Ze zijn ontworpen om een afdrukapparaat enz. te besturen. De rest – van 20 tot 7F – zijn gewone (afdrukbare) tekens.
Tabel 1 - ASCII-codering
|
|
Zoals u gemakkelijk kunt zien, bevat deze codering alleen Latijnse letters en letters die in de Engelse taal worden gebruikt. Er zijn ook rekenkundige en andere servicesymbolen. Maar er zijn geen Russische letters, en zelfs geen speciale Latijnse letters voor Duits of Frans. Dit is eenvoudig uit te leggen: de codering is speciaal ontwikkeld als Amerikaanse standaard. Toen computers over de hele wereld gebruikt werden, moesten andere karakters gecodeerd worden.
Om dit te doen, werd besloten om in elke byte de achtste bit te gebruiken. Hierdoor kwamen er nog 128 waarden beschikbaar (van 80 tot FF) die gebruikt konden worden om karakters te coderen. De eerste van de acht-bits tabellen is “extended ASCII” ( Uitgebreide ASCII) - bevatte verschillende varianten van Latijnse karakters die in sommige talen van West-Europa worden gebruikt. Het bevatte ook andere aanvullende symbolen, waaronder pseudografische afbeeldingen.
Met pseudografische tekens kunt u de schijn van een afbeelding creëren door alleen teksttekens op het scherm weer te geven. Het bestandsbeheerprogramma FAR Manager werkt bijvoorbeeld met pseudografische afbeeldingen.
Er waren geen Russische letters in de uitgebreide ASCII-tabel. Rusland (voorheen de USSR) en andere landen creëerden hun eigen coderingen die het mogelijk maakten om specifieke "nationale" karakters weer te geven in 8-bits tekstbestanden - Latijnse letters van de Poolse en Tsjechische taal, Cyrillisch (inclusief Russische letters) en andere alfabetten.
In alle coderingen die wijdverbreid zijn geworden, zijn de eerste 127 tekens (dat wil zeggen de bytewaarde met het achtste bit gelijk aan 0) hetzelfde als ASCII. Een ASCII-bestand werkt dus in elk van deze coderingen; De letters van de Engelse taal worden op dezelfde manier weergegeven.
Organisatie ISO(International Standardization Organization) heeft een groep normen aangenomen ISO8859. Het definieert 8-bits coderingen voor verschillende taalgroepen. ISO 8859-1 is dus een uitgebreide ASCII-tabel voor de VS en West-Europa. En ISO 8859-5 is een tabel voor het Cyrillische alfabet (inclusief Russisch).
Om historische redenen heeft de ISO 8859-5-codering echter geen wortel geschoten. In werkelijkheid worden de volgende coderingen gebruikt voor de Russische taal:
Codepagina 866 ( CP866), ook bekend als "DOS", ook bekend als "alternatieve GOST-codering". Op grote schaal gebruikt tot halverwege de jaren 90; wordt nu in beperkte mate gebruikt. Praktisch niet gebruikt voor het verspreiden van teksten op internet.
-KOI-8. Ontwikkeld in de jaren 70-80. Het is een algemeen aanvaarde standaard voor het verzenden van e-mailberichten op het Russische internet. Het wordt ook veel gebruikt in besturingssystemen van de Unix-familie, waaronder Linux. De KOI-8-versie, ontworpen voor Russisch, wordt genoemd KOI-8R; Er zijn versies voor andere Cyrillische talen (KOI8-U is bijvoorbeeld een versie voor de Oekraïense taal).
- Codepagina 1251, CP1251,Windows-1251. Ontwikkeld door Microsoft om de Russische taal in Windows te ondersteunen.
Het belangrijkste voordeel van de CP866 was het behoud van pseudo-grafische karakters op dezelfde plaatsen als in Extended ASCII; daarom zouden buitenlandse tekstprogramma's, bijvoorbeeld de beroemde Norton Commander, zonder wijzigingen kunnen werken. De CP866 wordt nu gebruikt voor Windows-programma's die in tekstvensters of tekstmodus op volledig scherm draaien, inclusief FAR Manager.
Teksten in CP866 zijn de afgelopen jaren vrij zeldzaam geweest (maar het wordt gebruikt om Russische bestandsnamen in Windows te coderen). Daarom zullen we dieper ingaan op twee andere coderingen: KOI-8R en CP1251.


Zoals u kunt zien, zijn Russische letters in de CP1251-coderingstabel in alfabetische volgorde gerangschikt (met uitzondering van de letter E). Deze opstelling maakt het voor computerprogramma's heel gemakkelijk om alfabetisch te sorteren.
Maar in KOI-8R lijkt de volgorde van Russische letters willekeurig. Maar eigenlijk is dat niet zo.
In veel oudere programma's ging het 8e bit verloren bij het verwerken of verzenden van tekst. (Nu zijn dergelijke programma's praktisch "uitgestorven", maar eind jaren 80 - begin jaren 90 waren ze wijdverspreid). Om uit een 8-bits waarde een 7-bits waarde te krijgen, trekt u gewoon 8 af van het meest significante cijfer; E1 wordt bijvoorbeeld 61.
Vergelijk nu KOI-8R met de ASCII-tabel (Tabel 1). U zult merken dat Russische letters in duidelijke overeenstemming met Latijnse letters zijn geplaatst. Als het achtste bit verdwijnt, veranderen kleine Russische letters in Latijnse hoofdletters, en Russische hoofdletters in kleine Latijnse letters. E1 in KOI-8 is dus de Russische “A”, terwijl 61 in ASCII de Latijnse “a” is.
Met KOI-8 kunt u dus de leesbaarheid van de Russische tekst behouden wanneer het 8e bit verloren gaat. “Hallo allemaal” wordt “pRIWET WSEM”.
Onlangs hebben zowel de alfabetische volgorde van karakters in de coderingstabel als de leesbaarheid met het verlies van de 8e bit hun doorslaggevende belang verloren. Het achtste bit in moderne computers gaat niet verloren tijdens verzending of verwerking. En alfabetisch sorteren gebeurt rekening houdend met de codering, en niet door simpelweg codes te vergelijken. (Overigens zijn de CP1251-codes niet volledig alfabetisch gerangschikt - de letter E staat niet op zijn plaats).
Vanwege het feit dat er twee algemene coderingen zijn, kunt u bij het werken met internet (e-mail, surfen op websites) soms een betekenisloze reeks letters zien in plaats van Russische tekst. Bijvoorbeeld: "IK BEN SBYUFEMHEL." Dit zijn slechts de woorden “met respect”; maar ze waren gecodeerd in CP1251-codering, en de computer decodeerde de tekst met behulp van de KOI-8-tabel. Als dezelfde woorden daarentegen in KOI-8 zouden worden gecodeerd en de computer de tekst zou decoderen volgens de CP1251-tabel, zou het resultaat "U HCHBTSEOYEN" zijn.
Soms komt het voor dat een computer Russischtalige letters ontcijfert aan de hand van een tabel die niet voor de Russische taal bedoeld is. Vervolgens verschijnt in plaats van Russische letters een betekenisloze reeks symbolen (bijvoorbeeld Latijnse letters van Oost-Europese talen); ze worden vaak "crocozybra's" genoemd.
In de meeste gevallen kunnen moderne programma's zelfstandig de coderingen van internetdocumenten (e-mails en webpagina's) bepalen. Maar soms ‘mislukken’ ze, en dan zie je vreemde reeksen Russische letters of ‘krokozyabry’. Om echte tekst op het scherm weer te geven, is het in een dergelijke situatie in de regel voldoende om de codering handmatig in het programmamenu te selecteren.
Voor dit artikel is informatie van de pagina http://open-office.edusite.ru/TextProcessor/p5aa1.html gebruikt.
Materiaal afkomstig van de site: