Hoe Intel Hyper Threading-technologie in te schakelen. Waar is hyperthreading nodig? Productiviteit is nooit genoeg
In het verleden hadden we het over Simultaneous Multi-Threading (SMT)-technologie, die wordt gebruikt in Intel-processors. En hoewel het aanvankelijk de codenaam Jackson Technology had als mogelijke optie, kondigde Intel zijn technologie afgelopen herfst officieel aan op het IDF-forum. De codenaam Jackson werd vervangen door het meer toepasselijke Hyper-Threading. Om te begrijpen hoe de nieuwe technologie werkt, hebben we dus enige initiële kennis nodig. We moeten namelijk weten wat een thread is en hoe deze threads worden uitgevoerd. Waarom werkt de applicatie? Hoe weet de processor welke bewerkingen hij op welke gegevens moet uitvoeren? Al deze informatie is opgenomen in de gecompileerde code van de actieve applicatie. En zodra de applicatie enig commando, eventuele gegevens van de gebruiker ontvangt, worden threads onmiddellijk naar de processor gestuurd, waardoor deze doet wat hij moet doen als reactie op het verzoek van de gebruiker. Vanuit het oogpunt van de processor is een thread een reeks instructies die moeten worden uitgevoerd. Wanneer je geraakt wordt door een projectiel in Quake III Arena, of wanneer je een Microsoft Word-document opent, krijgt de processor een specifieke set instructies toegestuurd die hij moet uitvoeren.
De verwerker weet precies waar hij deze instructies vandaan moet halen. Voor dit doel is een zelden genoemd register, de Program Counter (PC), ontworpen. Dit register verwijst naar de locatie in het geheugen waar de volgende uit te voeren instructie is opgeslagen. Wanneer een thread naar de processor wordt verzonden, wordt het geheugenadres van de thread in deze programmateller geladen, zodat de processor precies weet waar hij de uitvoering moet starten. Na elke instructie wordt de waarde van dit register verhoogd. Dit hele proces loopt totdat de thread eindigt. Aan het einde van de uitvoering van de thread wordt het adres van de volgende uit te voeren instructie in de programmateller ingevoerd. Threads kunnen elkaar onderbreken, en de processor slaat de waarde van de programmateller op de stapel op en laadt de teller met een nieuwe waarde. Maar er is nog steeds een beperking in dit proces: er kan slechts één thread per tijdseenheid worden uitgevoerd.
Er is een bekende manier om dit probleem op te lossen. Het bestaat uit het gebruik van twee processors - als één processor één thread tegelijk kan uitvoeren, dan kunnen twee processors al twee threads in dezelfde tijdseenheid uitvoeren. Houd er rekening mee dat deze methode niet ideaal is. Het gaat gepaard met veel andere problemen. Sommige ken je waarschijnlijk al. Ten eerste zijn meerdere processors altijd duurder dan één. Ten tweede is het beheren van twee processors ook niet zo eenvoudig. Vergeet bovendien de verdeling van bronnen tussen processors niet. Vóór de introductie van de AMD 760MP-chipset deelden alle x86-platforms met ondersteuning voor multiprocessing bijvoorbeeld alle systeembusbandbreedte onder alle beschikbare processors. Maar het belangrijkste nadeel is anders: voor dergelijk werk moeten zowel de applicatie als het besturingssysteem zelf multiprocessing ondersteunen. De mogelijkheid om de uitvoering van meerdere threads over computerbronnen te verdelen, wordt vaak multithreading genoemd. Tegelijkertijd moet het besturingssysteem multithreading ondersteunen. Toepassingen moeten ook multithreading ondersteunen om de bronnen van uw computer optimaal te kunnen benutten. Houd dit in gedachten terwijl we kijken naar een andere benadering om het multithreading-probleem op te lossen: Intels nieuwe Hyper-Threading-technologie.
Productiviteit is nooit genoeg
Er wordt altijd veel gesproken over efficiëntie. En niet alleen in een zakelijke omgeving, in enkele serieuze projecten, maar ook in het dagelijks leven. Ze zeggen dat homo sapiens de mogelijkheden van hun hersenen slechts gedeeltelijk gebruiken. Hetzelfde geldt voor de processors van moderne computers.
Neem bijvoorbeeld de Pentium 4. De processor heeft in totaal zeven uitvoeringseenheden, waarvan er twee kunnen werken met de dubbele snelheid van twee bewerkingen (micro-ops) per klokcyclus. Maar in ieder geval zul je geen programma vinden dat al deze apparaten met instructies kan vullen. Conventionele programma's doen het met eenvoudige berekeningen van gehele getallen en een paar bewerkingen voor het laden en opslaan van gegevens, terwijl bewerkingen met drijvende komma buiten beschouwing worden gelaten. Andere programma's (bijvoorbeeld Maya) laden voornamelijk drijvende-komma-apparaten met werk.
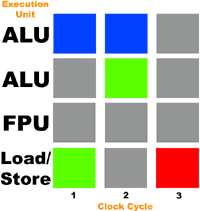
Om de situatie te illustreren, stellen we ons een processor voor met drie uitvoeringseenheden: een rekenkundige logische eenheid (integer ALU), een drijvende-komma-eenheid (FPU) en een laad-/opslageenheid (voor het schrijven en lezen van gegevens uit het geheugen). Laten we bovendien aannemen dat onze processor elke bewerking in één klokcyclus kan uitvoeren en bewerkingen tegelijkertijd over alle drie de apparaten kan verdelen. Laten we ons voorstellen dat een thread met de volgende instructies ter uitvoering naar deze processor wordt gestuurd:
De onderstaande afbeelding illustreert het belastingsniveau van actuatoren (grijs geeft een inactief apparaat aan, blauw geeft een werkend apparaat aan):
Je ziet dus dat in elke klokcyclus slechts 33% van alle actuatoren wordt gebruikt. Deze keer blijft de FPU volledig ongebruikt. Volgens Intel gebruiken de meeste IA-32 x86-programma's niet meer dan 35% van de uitvoeringseenheden van de Pentium 4-processor.
Laten we ons een andere thread voorstellen en deze ter uitvoering naar de processor sturen. Deze keer zal het bestaan uit de bewerkingen van het laden van gegevens, het toevoegen en opslaan van gegevens. Ze worden in de volgende volgorde uitgevoerd:

En nogmaals, de belasting op de actuatoren bedraagt slechts 33%.
Een goede uitweg uit deze situatie zou Instruction Level Parallelism (ILP) zijn. In dit geval worden meerdere instructies tegelijkertijd uitgevoerd, aangezien de processor in staat is meerdere parallelle uitvoeringseenheden tegelijk te vullen. Helaas zijn de meeste x86-programma's niet voldoende aangepast aan ILP. Daarom moeten we andere manieren vinden om de productiviteit te verhogen. Als het systeem bijvoorbeeld twee processors tegelijk zou gebruiken, zouden er twee threads tegelijkertijd kunnen worden uitgevoerd. Deze oplossing wordt thread-level parallellisme (TLP) genoemd. Overigens is deze oplossing vrij duur.
Welke andere manieren zijn er om de uitvoerende kracht van moderne x86-processors te vergroten?
Hyperthreading
Het probleem van onderbenutting van actuatoren heeft verschillende redenen. Als de processor de gegevens niet op de gewenste snelheid kan ontvangen (dit gebeurt als gevolg van onvoldoende systeembus- en geheugenbusbandbreedte), zullen de actuatoren over het algemeen niet zo efficiënt worden gebruikt. Bovendien is er nog een reden: het gebrek aan parallellisme op instructieniveau in de meeste opdrachtthreads.
Momenteel verbeteren de meeste fabrikanten de snelheid van processors door de kloksnelheid en de cachegrootte te verhogen. Op deze manier kun je natuurlijk de prestaties verbeteren, maar toch wordt het potentieel van de processor niet volledig benut. Als we meerdere threads tegelijk zouden kunnen uitvoeren, zouden we de processor veel efficiënter kunnen gebruiken. Dit is precies de essentie van Hyper-Threading-technologie.
Hyper-Threading is de naam van een technologie die voorheen bestond buiten de x86-wereld, Simultaneous Multi-Threading (SMT). Het idee achter deze technologie is eenvoudig. Eén fysieke processor lijkt voor het besturingssysteem twee logische processors, en het besturingssysteem ziet geen verschil tussen één SMT-processor of twee reguliere processors. In beide gevallen routeert het besturingssysteem threads alsof het een systeem met twee processors is. Verder worden alle problemen op hardwareniveau opgelost.
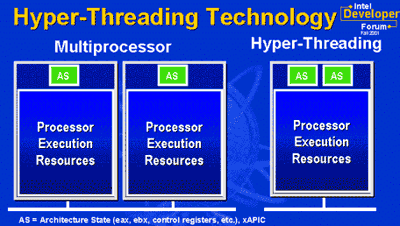
In een processor met Hyper-Threading heeft elke logische processor zijn eigen set registers (inclusief een afzonderlijke programmateller), en om de technologie eenvoudig te houden, implementeert deze geen gelijktijdige uitvoering van ophaal-/decoderingsinstructies in twee threads. Dat wil zeggen dat dergelijke instructies één voor één worden uitgevoerd. Alleen gewone opdrachten worden parallel uitgevoerd.
De technologie werd afgelopen najaar officieel aangekondigd op het Intel Developer Forum. De technologie werd gedemonstreerd op een Xeon-processor, waarbij de rendering werd uitgevoerd met behulp van Maya. In deze test presteerde de Xeon met Hyper-Threading 30% beter dan de standaard Xeon. Een mooie prestatieverbetering, maar het meest interessante is dat de technologie al aanwezig is in de Pentium 4- en Xeon-cores, alleen is deze uitgeschakeld.
De technologie is nog niet vrijgegeven, maar degenen onder jullie die de 0,13 micron Xeon hebben gekocht en deze processor op borden met een bijgewerkt BIOS hebben geïnstalleerd, waren waarschijnlijk verrast toen ze in het BIOS een optie zagen om Hyper-Threading in of uit te schakelen.
In de tussentijd laat Intel de Hyper-Threading-optie standaard uitgeschakeld. Om dit in te schakelen, hoeft u echter alleen maar het BIOS bij te werken. Dit alles geldt voor werkstations en servers; voor de personal computermarkt heeft het bedrijf geen plannen met betrekking tot deze technologie in de nabije toekomst. Hoewel het mogelijk is, zullen moederbordfabrikanten de mogelijkheid bieden om Hyper-Threading in te schakelen met behulp van een speciaal BIOS.
De zeer interessante vraag blijft: waarom wil Intel deze optie uitgeschakeld laten?
Dieper de technologie ingaan
Herinner je je die twee threads uit de vorige voorbeelden nog? Laten we er deze keer van uitgaan dat onze processor is uitgerust met Hyper-Threading. Laten we eens kijken wat er gebeurt als we deze twee threads tegelijkertijd proberen uit te voeren:

Net als voorheen geven blauwe rechthoeken de uitvoering van de instructie van de eerste thread aan, en geven groene rechthoeken de uitvoering van de instructie van de tweede thread aan. Grijze rechthoeken tonen ongebruikte uitvoeringsapparaten, en rode duiden op een conflict wanneer twee verschillende instructies van verschillende threads op hetzelfde apparaat zijn aangekomen.
Dus wat zien we? Parallellisme op threadniveau mislukte - uitvoeringsapparaten werden nog minder efficiënt gebruikt. In plaats van threads parallel uit te voeren, voert de processor ze langzamer uit dan wanneer hij ze zonder Hyper-Threading zou uitvoeren. De reden is vrij eenvoudig. We hebben geprobeerd twee zeer vergelijkbare threads tegelijkertijd uit te voeren. Ze bestaan immers allebei uit laad-/opslagoperaties en opteloperaties. Als we een toepassing met een geheel getal en een toepassing met drijvende komma parallel zouden uitvoeren, zouden we ons in een veel betere situatie bevinden. Zoals u kunt zien, hangt de effectiviteit van Hyper-Threading sterk af van het type belasting van de pc.
Momenteel gebruiken de meeste pc-gebruikers hun computer ongeveer zoals beschreven in ons voorbeeld. De processor voert veel zeer vergelijkbare bewerkingen uit. Helaas doen zich bij soortgelijke operaties extra beheersproblemen voor. Er zijn situaties waarin er geen actuatoren van het vereiste type meer zijn, en, als het toeval wil, zijn er twee keer zoveel instructies als normaal. Als thuiscomputerprocessors Hyper-Threading-technologie zouden gebruiken, zouden de prestaties in de meeste gevallen niet toenemen, en misschien zelfs met 0-10% afnemen.
Op werkstations biedt Hyper-Threading meer mogelijkheden om de productiviteit te verhogen. Maar aan de andere kant hangt het allemaal af van het specifieke gebruik van de computer. Een werkstation kan een geavanceerde computer zijn voor het verwerken van 3D-afbeeldingen, of gewoon een zwaarbelaste computer.
De grootste prestatieverbetering door het gebruik van Hyper-Threading wordt waargenomen bij servertoepassingen. Dit komt voornamelijk door de grote verscheidenheid aan bewerkingen die naar de processor worden verzonden. Een databaseserver die transacties gebruikt, kan 20-30% sneller draaien als de Hyper-Threading-optie is ingeschakeld. Iets kleinere prestatiewinsten worden waargenomen op webservers en op andere gebieden.
Maximale efficiëntie door Hyper-Threading
Denkt u dat Intel Hyper-Threading alleen voor zijn reeks serverprocessors heeft ontwikkeld? Natuurlijk niet. Als dat het geval zou zijn, zouden ze de chipruimte van hun andere processors niet verspillen. In feite is de NetBurst-architectuur die in de Pentium 4 en Xeon wordt gebruikt perfect geschikt voor een kernel die gelijktijdige multithreading ondersteunt. Laten we ons de processor opnieuw voorstellen. Deze keer zal het nog een actuator hebben: een tweede integer-apparaat. Laten we eens kijken wat er gebeurt als threads door beide apparaten worden uitgevoerd:
Bij gebruik van het tweede integer-apparaat vond het enige conflict plaats bij de laatste bewerking. Onze theoretische processor lijkt enigszins op de Pentium 4. Hij heeft maar liefst drie integer-apparaten (twee ALU's en één langzaam integer-apparaat voor roterende diensten). Belangrijker nog is dat beide Pentium 4 integer-apparaten op dubbele snelheid kunnen werken: ze voeren twee micro-ops per klokcyclus uit. Dit betekent op zijn beurt dat elk van deze twee Pentium 4/Xeon integer-apparaten deze twee optelbewerkingen vanuit verschillende threads in één klokcyclus zou kunnen uitvoeren.
Maar dit lost ons probleem niet op. Het zou weinig zin hebben om eenvoudigweg extra uitvoeringseenheden aan de processor toe te voegen om de prestaties van Hyper-Threading te verbeteren. In termen van siliciumruimte zou dit extreem duur zijn. In plaats daarvan stelde Intel voor dat ontwikkelaars programma's zouden optimaliseren voor Hyper-Threading.
Met behulp van de HALT-instructie kunt u een van de logische processors onderbreken, waardoor de prestaties worden verhoogd van toepassingen die niet profiteren van Hyper-Threading. De applicatie zal dus niet langzamer werken, maar een van de logische processors zal worden gestopt en het systeem zal op één logische processor draaien - de prestaties zullen hetzelfde zijn als op computers met één processor. Wanneer de toepassing vervolgens besluit dat deze qua prestaties zal profiteren van Hyper-Threading, zal de tweede logische processor eenvoudigweg zijn werk hervatten.
Op de website van Intel staat een presentatie waarin precies wordt beschreven hoe je moet programmeren om het maximale uit Hyper-Threading te halen.
Conclusies
Hoewel we allemaal enorm opgewonden waren toen we geruchten hoorden over Hyper-Threading in de kernen van alle moderne Pentium 4/Xeons, zal het nog steeds niet voor alle gelegenheden gratis zijn. De redenen zijn duidelijk, en de technologie heeft nog een lange weg te gaan voordat we Hyper-Threading op alle platforms zien draaien, inclusief thuiscomputers. En met de steun van ontwikkelaars kan de technologie zeker een goede bondgenoot zijn voor Pentium 4, Xeon en toekomstige generatie processors van Intel.
Gezien de huidige beperkingen en beschikbare verpakkingstechnologie lijkt Hyper-Threading een slimmere keuze voor de consumentenmarkt dan bijvoorbeeld AMD's SledgeHammer-aanpak - deze processors gebruiken maar liefst twee cores. En totdat verpakkingstechnologieën zoals Bumless Build-Up Layer volwassen zijn, kunnen de kosten voor het ontwikkelen van multi-core processors onbetaalbaar zijn.
Het is interessant om op te merken hoe verschillend AMD en Intel de afgelopen jaren zijn geworden. AMD heeft tenslotte ooit Intel-processors praktisch gekopieerd. Nu hebben bedrijven fundamenteel verschillende benaderingen ontwikkeld voor toekomstige processors voor servers en werkstations. AMD heeft eigenlijk een hele lange weg afgelegd. En als Sledge Hammer-processors daadwerkelijk twee kernen gebruiken, zal een dergelijke oplossing efficiënter presteren dan Hyper-Threading. In dit geval worden, naast de verdubbeling van het aantal actuatoren, inderdaad de problemen die we hierboven beschreven geëlimineerd.
Hyper-Threading zal voorlopig nog niet op de reguliere pc-markt terechtkomen, maar met goede ondersteuning van ontwikkelaars zou het de volgende technologie kunnen zijn die zijn weg vindt van het serverniveau naar reguliere pc's.
20 januari 2015 om 19:43 uurNogmaals over hyperthreading
- Testen van IT-systemen,
- Programmering
Er was een tijd dat het nodig was om de geheugenprestaties te evalueren in de context van Hyper-threading-technologie. Wij zijn tot de conclusie gekomen dat de invloed ervan niet altijd positief is. Toen er een hoeveelheid vrije tijd verscheen, was er een verlangen om het onderzoek voort te zetten en de lopende processen te beschouwen met een nauwkeurigheid van machineklokcycli en bits, met behulp van software van ons eigen ontwerp.
Platform in studie
Het doel van de experimenten is een ASUS N750JK-laptop met een Intel Core i7-4700HQ-processor. Klokfrequentie 2,4 GHz, verhoogd in Intel Turbo Boost-modus tot 3,4 GHz. 16 gigabyte DDR3-1600 RAM (PC3-12800) geïnstalleerd, werkend in dual-channel modus. Besturingssysteem – Microsoft Windows 8.1 64 bit.Fig.1 Configuratie van het onderzochte platform.
De processor van het onderzochte platform bevat 4 kernen, die, wanneer Hyper-Threading-technologie is ingeschakeld, hardware-ondersteuning bieden voor 8 threads of logische processors. De platformfirmware verzendt deze informatie naar het besturingssysteem via de ACPI-tabel MADT (Multiple APIC Description Table). Omdat het platform slechts één RAM-controller bevat, is er geen SRAT-tabel (System Resource Affinity Table), waarin de nabijheid van processorkernen tot geheugencontrollers wordt aangegeven. Het is duidelijk dat de onderzochte laptop geen NUMA-platform is, maar het besturingssysteem beschouwt het, met het oog op unificatie, als een NUMA-systeem met één domein, zoals aangegeven door de lijn NUMA Nodes = 1. Een feit dat fundamenteel is voor onze experimenten is dat de datacache op het eerste niveau een grootte van 32 kilobytes heeft voor elk van de vier kernen. Twee logische processors die één kern delen, delen de L1- en L2-caches.
Operatie wordt bestudeerd
We zullen de afhankelijkheid van de leessnelheid van een datablok van zijn grootte bestuderen. Om dit te doen, zullen we de meest productieve methode kiezen, namelijk het lezen van 256-bit operanden met behulp van de AVX-instructie VMOVAPD. In de grafieken toont de X-as de blokgrootte en de Y-as de leessnelheid. Rond punt X, dat overeenkomt met de grootte van de L1-cache, verwachten we een omslagpunt te zien, aangezien de prestaties zouden moeten afnemen nadat het verwerkte blok de cachelimieten heeft verlaten. In onze test werkt, in het geval van multi-threaded verwerking, elk van de 16 geïnitieerde threads met een afzonderlijk bereik aan adressen. Om de Hyper-Threading-technologie binnen de applicatie te controleren, gebruikt elke thread de SetThreadAffinityMask API-functie, die een masker instelt waarin één bit overeenkomt met elke logische processor. Met een enkele bitwaarde kan de opgegeven processor door een bepaalde thread worden gebruikt, een nulwaarde verbiedt dit. Voor 8 logische processors van het onderzochte platform staat masker 11111111b het gebruik van alle processors toe (Hyper-Threading is ingeschakeld), masker 01010101b staat het gebruik van één logische processor in elke kern toe (Hyper-Threading is uitgeschakeld).In de grafieken worden de volgende afkortingen gebruikt:
MBPS (megabytes per seconde) – blokleessnelheid in megabytes per seconde;
CPI (klokken per instructie) – aantal klokcycli per instructie;
TSC (Tijdstempelteller) – CPU-klokteller.
Opmerking: De kloksnelheid van het TSC-register komt mogelijk niet overeen met de kloksnelheid van de processor wanneer deze in de Turbo Boost-modus wordt uitgevoerd. Bij de interpretatie van de resultaten moet hiermee rekening gehouden worden.
Aan de rechterkant van de grafieken wordt een hexadecimale dump gevisualiseerd van de instructies die de lus vormen van de doelbewerking die wordt uitgevoerd in elk van de programmathreads, of de eerste 128 bytes van deze code.
Ervaring nr. 1. Eén draad

Afb.2 Eén draad lezen
De maximale snelheid is 213563 megabytes per seconde. Het buigpunt treedt op bij een blokgrootte van ongeveer 32 kilobytes.
Ervaring nr. 2. 16 threads op 4 processors, Hyper-Threading uitgeschakeld

Afb.3 Lezen in zestien draadjes. Het aantal gebruikte logische processors is vier
Hyperthreading is uitgeschakeld. De maximale snelheid is 797598 megabytes per seconde. Het buigpunt treedt op bij een blokgrootte van ongeveer 32 kilobytes. Zoals verwacht nam de snelheid, vergeleken met lezen met één thread, ongeveer vier keer toe, gebaseerd op het aantal werkende kernen.
Ervaring nr. 3. 16 threads op 8 processors, Hyper-Threading ingeschakeld

Afb.4 Lezen in zestien draadjes. Het aantal gebruikte logische processors is acht
Hyperthreading is ingeschakeld. De maximale snelheid bedraagt 800.722 megabytes per seconde; dankzij het inschakelen van Hyper-Threading is deze vrijwel niet toegenomen. Het grote minpunt is dat het buigpunt optreedt bij een blokgrootte van ongeveer 16 kilobytes. Door Hyper-Threading in te schakelen werd de maximale snelheid enigszins verhoogd, maar de snelheidsdaling treedt nu op bij de helft van de blokgrootte - ongeveer 16 kilobytes, dus de gemiddelde snelheid is aanzienlijk gedaald. Dit is niet verrassend, elke core heeft zijn eigen L1-cache, terwijl de logische processors van dezelfde core deze delen.
Conclusies
De bestudeerde operatie schaalt vrij goed op een multi-coreprocessor. Redenen: Elke core bevat zijn eigen L1- en L2-cache, de doelblokgrootte is vergelijkbaar met de cachegrootte en elke thread werkt met zijn eigen adresbereik. Voor academische doeleinden hebben we deze voorwaarden gecreëerd in een synthetische test, waarbij we onderkennen dat toepassingen in de echte wereld meestal verre van ideale optimalisatie zijn. Maar het inschakelen van Hyper-Threading had, zelfs onder deze omstandigheden, een negatief effect; met een lichte toename van de pieksnelheid is er een aanzienlijk verlies in de verwerkingssnelheid van blokken waarvan de grootte varieert van 16 tot 32 kilobytes.Hyperthreading genoemd.
Terminologie
Terminologie in de technologiewereld kan verwarrend en gemakkelijk te begrijpen zijn
is vergeten, dus laten we beginnen met het verduidelijken van de betekenis van de termen,
die ik hier zal gebruiken. Er wordt een multi-coreprocessor genoemd
een processor met meer dan één kern op één geïntegreerd circuit.
Multi-chip betekent meerdere chips samen gecombineerd.
Multiprocessor betekent dat meerdere afzonderlijke processors samenwerken
werken in hetzelfde systeem. En natuurlijk betekent CPU centraal
een processor met een of meer kernen, die elk een kern hebben
uitvoeringsapparaat (waarvan alle wiskunde wordt uitgevoerd).
Hyperthreading
Dus wat is hyperthreading-technologie? De term hyperthreading
gebruikt door Intel om hun technologie te definiëren, die
Hiermee kan het besturingssysteem één CPU-kern als twee kernen behandelen.
Het besturingssysteem werkt dus met zo'n kernel op dezelfde manier als met
elke multi-core chip, die er meerdere verzendt
processen. Hoewel deze technologie wordt gebruikt, is het mogelijk het systeem te forceren
één kern waarnemen als drie of meer kernen, architectonische complexiteit
heeft Intel beperkt tot het vrijgeven van hyper-threaded cores die dat wel kunnen
gezien worden als slechts twee kernen.
Er is hier geen truc. Intel heeft een architectuur ontwikkeld
chip voor het verwerken van processen op dezelfde manier als multi-core-processen
verwerkers. In wezen werd Intel zwaar gebruikt
gebieden van de CPU-kern en zorgde ervoor dat deze secties door meerdere werden gebruikt
processen tegelijkertijd. Omdat deze kernregio's gescheiden zijn
(ze bevinden zich op dezelfde chip maar gebruiken verschillende gebieden
dit kristal), interfereren deze processen niet met elkaar. Zo een
hyper-threading-compatibele kernels zijn niet helemaal hetzelfde
het allerbelangrijkste: multi-coreprocessors; niet elk proces kan tegelijkertijd
met een ander proces wordt uitgevoerd, moet het een afzonderlijk onderdeel gebruiken
kernels voor hun activiteiten.
Hyperthreading is een voorbeeld van gelijktijdig
multithreading (Gelijktijdige Multi-Threading - SMT). SMT is één
van twee soorten multithreading. Het andere type wordt tijdelijk genoemd
multithreading (Temporele Multi-Threading - TMT). Met TMT-kern
processor voert instructies eerst uit vanuit één thread, en vervolgens vanuit
een andere, en dan weer vanaf de eerste, en daarom lijkt het voor de gebruiker dat
er lopen twee draden tegelijk, terwijl de draden zich in feite eenvoudigweg verdelen
CPU-tijd tussen elkaar. Met SMT kunnen instructies van elke thread worden verzonden
gelijktijdig worden uitgevoerd. Deze technologieën kunnen hiervoor worden gebruikt
productiviteit verhogen.
Gebruikers moeten zich er ook van bewust zijn dat niet alle besturingssystemen dit ondersteunen
hyperthreading-technologie. Volgens Intel komen de volgende besturingssystemen uit
Microsoft is volledig geoptimaliseerd om technologie te ondersteunen
hyperthreading:
Microsoft Windows XP Professional-editie
Microsoft Windows XP Home-editie
Microsoft Windows Vista Home Basic
Microsoft Windows Vista Home Premium
Microsoft Windows Vista Home Ultimate
Microsoft Windows Vista Thuisbedrijf
En zoals Intel zegt, de volgende besturingssystemen zijn dat niet helemaal
geoptimaliseerd voor hyper-threading-technologie, en daarom dit
technologie moet worden uitgeschakeld in de BIOS-instellingen:
Microsoft Windows 2000 (alle versies)
Microsoft Windows NT 4.0
Microsoft Windows ME
MicrosoftWindows98
Microsoft Windows 98 SE
Soms toepassingen zoals FireFox
Er zijn problemen met hyperthreading. De beste manier om dit op te lossen
Het probleem is dat de toepassing wordt uitgevoerd in de Windows 98-compatibiliteitsmodus.
Om dit te doen, klikt u met de rechtermuisknop op het applicatiepictogram,
ga naar eigenschappen, selecteer compatibiliteit en vink het vakje aan
"Voer dit programma uit
compatibiliteitsmodus)", waarbij u Windows 98 selecteert. Hierdoor wordt de technologie uitgeschakeld
hyper-threading voor deze toepassing, aangezien Windows 98 dat niet doet
ondersteunt hyperthreading.
Voordelen van hyperthreading
Er zijn veel voordelen van hyperthreading. Intel-bedrijf
stelt dat het dupliceren van bepaalde delen van de CPU-kern toeneemt
kerngrootte met ongeveer 5 procent, maar zorgt nog steeds voor een toename
prestatie met 30 procent vergeleken met andere identieke
processorkernen zonder hyperthreading.
Nadelen van hyperthreading
advertentie
//
//]]-->

Hoewel hyper-threaded CPU-kernen niet de volledige capaciteit bieden
voordelen van multi-coreprocessors, ze hebben nog steeds aanzienlijk
voordelen ten opzichte van conventionele single-core processors. Zeker,
Het is altijd handig om te weten welke nadelen technologie heeft,
voordat u het gebruikt. Een nadeel van veel toepassingen is
hoog energieverbruik. Omdat alle delen van de kernel nodig zijn
in vermogen (zelfs in de stand-bymodus), totaal energieverbruik
hyper-threading kernen, evenals alle kernen met SMT-ondersteuning hierboven. Zonder
optimaal gebruik te maken van de aangeboden snelheidsverbeteringen
hyper-threaded kernel, het zal gewoon de kernel zijn die meer verbruikt
elektriciteit. Voor veel situaties, inclusief serverfarms en mobiel
computers is een dergelijk verhoogd energieverbruik ongewenst.
Bovendien, als we een CPU-kern met hyperthreading vergelijken met een CPU-kern zonder hyperthreading
kernel, zult u een aanzienlijke toename van de cache-overflow opmerken. ARM
stelt dat deze stijging kan oplopen tot 42%. Vergelijk dit
waarde met multi-coreprocessors, waarbij de cache-overflow wordt verminderd
37%, en dat gaat echt belangrijk worden.
Nu, na het lezen van de informatie over al deze nadelen,
Je zou kunnen besluiten dat deze kernels met hyperthreading nutteloos zijn. En je hebt gelijk, binnen
sommige situaties. Als het stroomverbruik bijvoorbeeld het belangrijkste is
aspect in uw situatie, dan kunnen hyper-threaded kernels (of andere kernels
met SMT-ondersteuning) zal ongewenst zijn. Maar zelfs als het verbruik
kracht staat hoog op uw lijst met vereisten, kernen met hyperthreading
kan een geschikte optie zijn. Laten we een serverfarm als voorbeeld nemen.
Meestal is het energieverbruik van serverparken (deze
rekeningen kunnen vele duizenden dollars per maand bedragen!). Echter, binnen
In de huidige serverfarms zijn veel servers virtueel.
Het kan dus goed zijn dat je meerdere virtuele servers hebt
op één fysieke server, met prestatie-eisen
Deze servers zijn niet boven het gemiddelde. Het is heel goed mogelijk dat dit type
configuratie zorgt voor voldoende CPU-gebruik
gebruik de maximale hoeveelheid prestaties van hyperthreaded cores,
Tegelijkertijd wordt het energieverbruik tot een minimum beperkt.
Zoals altijd is het belangrijk om vooraf duidelijk rekening te houden met alle bedrijfsomstandigheden
dan de beslissing om technologie te gebruiken. Technologieën zonder nadelen
gebeurt praktisch nooit. Over het algemeen nuttig of nutteloos
een bepaalde technologie met betrekking tot uw situatie wordt alleen onthuld
na een grondige beoordeling van al zijn voor- en nadelen.
Hyperthreading is slechts een technologie. Voor extra
Voor informatie over dit onderwerp raad ik aan mijn twee eerdere artikelen te lezen. Ten eerste een artikel over , waarin wordt uitgelegd hoe multi-coreprocessors toegang krijgen tot cachegeheugen. Ten tweede mijn artikel over processoraffiniteit.
waarin wordt gesproken over de interactie tussen applicaties en
meerdere kernen. Als u vragen heeft over mijn artikel,
stuur ze mij per e-mail en ik zal proberen ze zo snel mogelijk te beantwoorden.
Russel
Hitchcock (Russell Hitchcock) treedt op als adviseur en is verantwoordelijk voor
omvat netwerkhardware, controle
systemen en antennes. Russell schrijft ook technische artikelen over diverse
Hyper-Threading-technologie (HT, hyperthreading) verscheen voor het eerst 15 jaar geleden - in 2002, in Pentium 4- en Xeon-processors, en sindsdien is het verschenen in Intel-processors (in de Core i-lijn, sommige Atom, en recentelijk ook in Pentium) , en verdween toen (de ondersteuning was niet in de Core 2 Duo- en Quad-lijnen). En gedurende deze tijd heeft het mythische eigenschappen verworven: ze zeggen dat de aanwezigheid ervan de prestaties van de processor bijna verdubbelt, waardoor zwakke i3's in krachtige i5's veranderen. Tegelijkertijd zeggen anderen dat HT een veel voorkomende marketingtruc is en weinig nut heeft. De waarheid ligt, zoals gewoonlijk, in het midden: op sommige plaatsen is er enige zin, maar je moet zeker geen dubbele stijging verwachten.
Technische beschrijving van de technologie
Laten we beginnen met de definitie die op de Intel-website wordt gegeven:
Intel® Hyper-Threading Technologie (Intel® HT) maakt een efficiënter gebruik van processorbronnen mogelijk doordat meerdere threads op elke kern kunnen worden uitgevoerd. In termen van prestaties verhoogt deze technologie de doorvoer van processors, waardoor de algehele prestaties van multi-threaded applicaties worden verbeterd.
Over het algemeen is het duidelijk dat niets duidelijk is - alleen algemene zinnen, maar ze beschrijven de technologie kort - HT zorgt ervoor dat één fysieke kern tegelijkertijd meerdere (meestal twee) logische threads kan verwerken. Maar hoe? Processor die hyperthreading ondersteunt:
- kan informatie over meerdere lopende threads tegelijk opslaan;
- bevat één set registers (dat wil zeggen snelle geheugenblokken in de processor) en één interruptcontroller (dat wil zeggen een ingebouwde processoreenheid die verantwoordelijk is voor de mogelijkheid om opeenvolgend verzoeken te verwerken voor het optreden van een gebeurtenis die onmiddellijke aandacht van verschillende apparaten) voor elke logische CPU.

Laten we zeggen dat de processor twee taken heeft. Als de processor één kern heeft, zal hij deze opeenvolgend uitvoeren, als er twee zijn, dan parallel op twee kernen, en de uitvoeringstijd van beide taken zal gelijk zijn aan de tijd die aan de zwaardere taak wordt besteed. Maar wat als de processor single-core is, maar hyperthreading ondersteunt? Zoals u in de afbeelding hierboven kunt zien, is de processor bij het uitvoeren van één taak niet 100% bezig - sommige processorblokken zijn eenvoudigweg niet nodig bij deze taak, ergens maakt de vertakkingsvoorspellingsmodule een fout (die nodig is om te voorspellen of een voorwaardelijke branch wordt uitgevoerd in het programma), ergens is er een cachetoegangsfout - over het algemeen is de processor bij het uitvoeren van een taak zelden meer dan 70% bezet. En de HT-technologie "schuift" gewoon een tweede taak in onbezette processorblokken, en het blijkt dat twee taken tegelijkertijd op één kern worden verwerkt. Het verdubbelen van de prestaties gebeurt echter niet om voor de hand liggende redenen - heel vaak blijkt dat twee taken dezelfde rekeneenheid in de processor nodig hebben, en dan zien we een simpele: terwijl de ene taak wordt verwerkt, wordt de uitvoering van de tweede eenvoudigweg uitgevoerd. stopt op dit moment (blauwe vierkanten - de eerste taak, groen - tweede, rood - taken die toegang hebben tot hetzelfde blok in de processor):

Als gevolg hiervan blijkt de tijd die een processor met HT aan twee taken besteedt meer te zijn dan de tijd die nodig is om de zwaarste taak te berekenen, maar minder dan de tijd die nodig is om beide taken opeenvolgend te evalueren.
Voor- en nadelen van technologie
Rekening houdend met het feit dat de processorchip met HT-ondersteuning fysiek gemiddeld 5% groter is dan de processorchip zonder HT (dit is hoeveel extra registerblokken en interruptcontrollers in beslag nemen), en met HT-ondersteuning kunt u de processor met 90-95%, en vergeleken met 70% zonder HT krijgen we dat de toename op zijn best 20-30% zal zijn - het cijfer is behoorlijk groot.
Niet alles is echter zo goed: het komt voor dat er helemaal geen prestatiewinst door HT is, en het komt zelfs voor dat HT de prestaties van de processor verslechtert. Dit gebeurt om vele redenen:
- Gebrek aan cachegeheugen. Moderne quad-core i5's hebben bijvoorbeeld 6 MB L3-cache - 1,5 MB per core. In quad-core i7's met HT is de cache al 8 MB, maar omdat er 8 logische cores zijn, krijgen we slechts 1 MB per core - tijdens berekeningen hebben sommige programma's mogelijk niet genoeg van dit volume, wat leidt tot een daling van de prestatie.
- Gebrek aan software-optimalisatie. Het meest fundamentele probleem is dat programma's logische kernen als fysiek beschouwen. Daarom treden er bij het parallel uitvoeren van taken op één kern vaak vertragingen op als gevolg van taken die toegang krijgen tot dezelfde rekeneenheid, waardoor de prestatiewinst van HT uiteindelijk tot niets wordt gereduceerd.
- Gegevensafhankelijkheid. Uit het vorige punt volgt: om de ene taak te voltooien, is het resultaat van een andere vereist, maar deze is nog niet voltooid. En opnieuw krijgen we downtime, een vermindering van de CPU-belasting en een kleine toename van HT.
Er zijn er veel, omdat dit voor HT-berekeningen manna uit de hemel is - de warmtedissipatie neemt praktisch niet toe, de processor wordt niet veel groter en met de juiste optimalisatie kun je een toename tot 30% behalen. Daarom werd de ondersteuning ervan snel geïmplementeerd in die programma's waar het gemakkelijk is om de belasting te parallelliseren - in archiveringsprogramma's (WinRar), programma's voor 2D/3D-modellering (3ds Max, Maya), programma's voor foto- en videoverwerking (Sony Vegas, Photoshop, Corel Draw).
Programma's die niet goed werken met hyperthreading
Traditioneel is dit het merendeel van de games - ze zijn meestal moeilijk om op competente wijze te parallelliseren, dus vaak zijn vier fysieke kernen op hoge frequenties (i5 K-serie) meer dan genoeg voor games, waarbij parallellisering onder 8 logische kernen in i7 blijkt te zijn een onmogelijke opgave. Het is echter de moeite waard om te overwegen dat er achtergrondprocessen zijn, en als de processor HT niet ondersteunt, valt hun verwerking op de fysieke kernen, wat het spel kan vertragen. Hier wint de i7 met HT - alle achtergrondtaken hebben traditioneel een lagere prioriteit, dus als je tegelijkertijd op één fysieke kern van het spel en een achtergrondtaak draait, krijgt het spel een hogere prioriteit en zal de achtergrondtaak de kernen niet "afleiden" bezig met de game - daarom kun je voor het streamen of opnemen van games beter een i7 met hyperthreading nemen.
Resultaten
Misschien rest hier nog maar één vraag: heeft het zin om processors met HT te nemen of niet? Als je graag vijf programma's tegelijkertijd open wilt houden en tegelijkertijd games wilt spelen, of bezig bent met fotoverwerking, video of modellering - ja, het is natuurlijk de moeite waard om te nemen. En als je gewend bent om alle andere af te sluiten voordat je een zwaar programma start, en je niet bezighoudt met verwerking of modellering, dan heb je geen zin aan een processor met HT.
Er was een tijd dat het nodig was om de geheugenprestaties te evalueren in de context van Hyper-threading-technologie. Wij zijn tot de conclusie gekomen dat de invloed ervan niet altijd positief is. Toen er een hoeveelheid vrije tijd verscheen, was er een verlangen om het onderzoek voort te zetten en de lopende processen te beschouwen met een nauwkeurigheid van machineklokcycli en bits, met behulp van software van ons eigen ontwerp.
Platform in studie
Het doel van de experimenten is een ASUS N750JK-laptop met een Intel Core i7-4700HQ-processor. Klokfrequentie 2,4 GHz, verhoogd in Intel Turbo Boost-modus tot 3,4 GHz. 16 gigabyte DDR3-1600 RAM (PC3-12800) geïnstalleerd, werkend in dual-channel modus. Besturingssysteem – Microsoft Windows 8.1 64 bit.Fig.1 Configuratie van het onderzochte platform.
De processor van het onderzochte platform bevat 4 kernen, die, wanneer Hyper-Threading-technologie is ingeschakeld, hardware-ondersteuning bieden voor 8 threads of logische processors. De platformfirmware verzendt deze informatie naar het besturingssysteem via de ACPI-tabel MADT (Multiple APIC Description Table). Omdat het platform slechts één RAM-controller bevat, is er geen SRAT-tabel (System Resource Affinity Table), waarin de nabijheid van processorkernen tot geheugencontrollers wordt aangegeven. Het is duidelijk dat de onderzochte laptop geen NUMA-platform is, maar het besturingssysteem beschouwt het, met het oog op unificatie, als een NUMA-systeem met één domein, zoals aangegeven door de lijn NUMA Nodes = 1. Een feit dat fundamenteel is voor onze experimenten is dat de datacache op het eerste niveau een grootte van 32 kilobytes heeft voor elk van de vier kernen. Twee logische processors die één kern delen, delen de L1- en L2-caches.
Operatie wordt bestudeerd
We zullen de afhankelijkheid van de leessnelheid van een datablok van zijn grootte bestuderen. Om dit te doen, zullen we de meest productieve methode kiezen, namelijk het lezen van 256-bit operanden met behulp van de AVX-instructie VMOVAPD. In de grafieken toont de X-as de blokgrootte en de Y-as de leessnelheid. Rond punt X, dat overeenkomt met de grootte van de L1-cache, verwachten we een omslagpunt te zien, aangezien de prestaties zouden moeten afnemen nadat het verwerkte blok de cachelimieten heeft verlaten. In onze test werkt, in het geval van multi-threaded verwerking, elk van de 16 geïnitieerde threads met een afzonderlijk bereik aan adressen. Om de Hyper-Threading-technologie binnen de applicatie te controleren, gebruikt elke thread de SetThreadAffinityMask API-functie, die een masker instelt waarin één bit overeenkomt met elke logische processor. Met een enkele bitwaarde kan de opgegeven processor door een bepaalde thread worden gebruikt, een nulwaarde verbiedt dit. Voor 8 logische processors van het onderzochte platform staat masker 11111111b het gebruik van alle processors toe (Hyper-Threading is ingeschakeld), masker 01010101b staat het gebruik van één logische processor in elke kern toe (Hyper-Threading is uitgeschakeld).In de grafieken worden de volgende afkortingen gebruikt:
MBPS (megabytes per seconde) – blokleessnelheid in megabytes per seconde;
CPI (klokken per instructie) – aantal klokcycli per instructie;
TSC (Tijdstempelteller) – CPU-klokteller.
Opmerking: De kloksnelheid van het TSC-register komt mogelijk niet overeen met de kloksnelheid van de processor wanneer deze in de Turbo Boost-modus wordt uitgevoerd. Bij de interpretatie van de resultaten moet hiermee rekening gehouden worden.
Aan de rechterkant van de grafieken wordt een hexadecimale dump gevisualiseerd van de instructies die de lus vormen van de doelbewerking die wordt uitgevoerd in elk van de programmathreads, of de eerste 128 bytes van deze code.
Ervaring nr. 1. Eén draad
Afb.2 Eén draad lezen
De maximale snelheid is 213563 megabytes per seconde. Het buigpunt treedt op bij een blokgrootte van ongeveer 32 kilobytes.
Ervaring nr. 2. 16 threads op 4 processors, Hyper-Threading uitgeschakeld
Afb.3 Lezen in zestien draadjes. Het aantal gebruikte logische processors is vier
Hyperthreading is uitgeschakeld. De maximale snelheid is 797598 megabytes per seconde. Het buigpunt treedt op bij een blokgrootte van ongeveer 32 kilobytes. Zoals verwacht nam de snelheid, vergeleken met lezen met één thread, ongeveer vier keer toe, gebaseerd op het aantal werkende kernen.
Ervaring nr. 3. 16 threads op 8 processors, Hyper-Threading ingeschakeld
Afb.4 Lezen in zestien draadjes. Het aantal gebruikte logische processors is acht
Hyperthreading is ingeschakeld. De maximale snelheid bedraagt 800.722 megabytes per seconde; dankzij het inschakelen van Hyper-Threading is deze vrijwel niet toegenomen. Het grote minpunt is dat het buigpunt optreedt bij een blokgrootte van ongeveer 16 kilobytes. Door Hyper-Threading in te schakelen werd de maximale snelheid enigszins verhoogd, maar de snelheidsdaling treedt nu op bij de helft van de blokgrootte - ongeveer 16 kilobytes, dus de gemiddelde snelheid is aanzienlijk gedaald. Dit is niet verrassend, elke core heeft zijn eigen L1-cache, terwijl de logische processors van dezelfde core deze delen.