Hoe maak je een exponentiële grafiek in Excel Een lineaire trend bouwen
Een trend is een patroon dat de stijging of daling van een indicator in de loop van de tijd beschrijft. Als u een dynamische reeks (statistische gegevens, een lijst met vaste waarden van een variabele indicator in de loop van de tijd) in een grafiek weergeeft, wordt vaak een bepaalde hoek gemarkeerd - de curve gaat geleidelijk omhoog of omlaag, in dergelijke gevallen is gebruikelijk om te zeggen dat de reeks dynamieken neigt (respectievelijk stijgend of dalend).
Trend als model
Als we een model bouwen dat dit fenomeen beschrijft, krijgen we een vrij eenvoudig en zeer handig hulpmiddel voor prognoses dat geen complexe berekeningen of tijdskosten vereist om de significantie of toereikendheid van beïnvloedende factoren te controleren.
Dus, wat is een trend als model? Dit is een reeks berekende coëfficiënten van de vergelijking die de regressieafhankelijkheid van de indicator (Y) van de verandering in tijd (t) uitdrukken. Dat wil zeggen, dit is precies dezelfde regressie als die we eerder beschouwden, alleen de tijdsindicator is hier de beïnvloedende factor.
Belangrijk!
In berekeningen betekent t meestal niet het jaar, het nummer van de maand of de week, maar het volgnummer van de periode in de statistische populatie die wordt bestudeerd - de tijdreeks. Als de tijdreeks bijvoorbeeld meerdere jaren wordt bestudeerd en de gegevens maandelijks zijn vastgelegd, is het fundamenteel verkeerd om de opnieuw instelbare nummering van maanden, van 1 tot 12 en opnieuw vanaf het begin, te gebruiken. Het is ook onjuist als de studie van de reeks begint, bijvoorbeeld vanaf maart, gebruik 3 (de derde maand van het jaar) als de waarde van t, als dit de eerste waarde is in de bestudeerde populatie, dan zou het ordinale getal moeten wees 1.
Lineair trendmodel
Net als elke andere regressie kan de trend lineair zijn (de graad van de beïnvloedende factor t is 1) of niet-lineair (de graad is groter of kleiner dan één). Aangezien lineaire regressie de eenvoudigste, maar niet altijd de meest nauwkeurige is, zullen we dit type trend in meer detail bekijken.
Algemeen beeld van de lineaire trendvergelijking: Y(t) = een 0 + een 1 *t + Ɛ
Waar a 0 de nul-regressiecoëfficiënt is, dat wil zeggen, wat zal Y zijn als de beïnvloedende factor nul is, a 1 is de regressiecoëfficiënt, die de mate van afhankelijkheid van de bestudeerde indicator Y van de beïnvloedende factor t uitdrukt, Ɛ is een willekeurige component of standaard de fout is in feite het verschil tussen de werkelijke waarden van Y en de berekende. t is de enige beïnvloedende factor - tijd.
Hoe meer uitgesproken de trend van de groei van de indicator of zijn daling, hoe groter de coëfficiënt a 1 zal zijn. Dienovereenkomstig wordt aangenomen dat de constante a 0 samen met de willekeurige component Ɛ de rest van de regressie-invloeden weerspiegelt, naast de tijd, dat wil zeggen alle andere mogelijke beïnvloedende factoren.
De coëfficiënten van het model kunnen worden berekend met behulp van de standaardmethode van de kleinste kwadraten (LSM). Microsoft Excel verwerkt al deze berekeningen met een knaller en om een lineair trendmodel of een kant-en-klare voorspelling te krijgen, zijn er maar liefst vijf manieren, die we hieronder afzonderlijk zullen analyseren.
Grafische manier om een lineaire trend te krijgen
In dit en in alle andere voorbeelden zullen we dezelfde tijdreeks gebruiken - het niveau van het BBP, dat jaarlijks wordt berekend en geregistreerd, in ons geval zal het onderzoek plaatsvinden over de periode van 2004 tot 2012.

Laten we nog een kolom toevoegen aan de initiële gegevens, die we t zullen noemen en met getallen in oplopende volgorde de serienummers van alle geregistreerde BBP-waarden voor de gespecificeerde periode van 2004 tot 2012 markeren. – 9 jaar of 9 periodes.

Excel zal een leeg veld toevoegen - markup voor de toekomstige grafiek, selecteer deze grafiek en activeer het tabblad dat in de menubalk verschijnt - Constructeur, op zoek naar een knop Selecteer gegevens, druk in het geopende venster op de knop Toevoegen. Een pop-upvenster zal u vragen om gegevens te selecteren voor het plotten van een grafiek. Als veldwaarde Rijnaam selecteer de cel met de tekst die het meest overeenkomt met de naam van de grafiek. In veld X-waarden geef het celinterval van de kolom t aan - de beïnvloedende factor. In veld Y-waarden geef het interval van cellen in de kolom aan met bekende waarden van het BBP (Y) - de indicator die wordt bestudeerd.

Na het invullen van de gespecificeerde velden, drukt u meerdere keren op de OK-knop en krijgt u de voltooide dynamische grafiek. Klik nu met de rechtermuisknop op de grafieklijn zelf en selecteer het item in het contextmenu dat verschijnt. Trendlijn toevoegen

Er wordt een venster geopend voor het instellen van de parameters voor het construeren van een trendlijn, waarbij we een van de soorten modellen selecteren: Lineair, zet een vinkje voor de items P een vergelijking in een diagram weergeven en Zet op het diagram de waarde van de benaderingsbetrouwbaarheid R2, dit is voldoende om de reeds geconstrueerde trendlijn op de grafiek weer te geven, evenals de wiskundige versie van de modelweergave in de vorm van een kant-en-klare vergelijking en de modelkwaliteitsindicator R2. Als u geïnteresseerd bent in het weergeven van de prognose op de grafiek, om de kloof tussen de bestudeerde indicator visueel te beoordelen, geeft u in het veld aan Voorspelling voor het aantal renteperiodes.

Eigenlijk is dit alles wat deze methode betreft, je kunt er natuurlijk aan toevoegen dat de weergegeven lineaire trendvergelijking het model zelf is, dat kan worden gebruikt als een formule om de berekende waarden voor het model te krijgen en, dienovereenkomstig, de exacte voorspellingswaarden (de voorspelling die in de grafiek wordt weergegeven, kan alleen bij benadering worden geschat), wat we hebben gedaan in het voorbeeld dat bij het artikel is gevoegd.
Een lineaire trend bouwen met behulp van de LIJNSCH-formule

De essentie van deze methode is om de lineaire trendcoëfficiënten te vinden met behulp van de functie LIJNSCH, dan krijgen we door deze beïnvloedende coëfficiënten in de vergelijking te substitueren, een voorspellend model.
We moeten twee aangrenzende cellen selecteren (in de schermafbeelding zijn dit cellen A38 en B38), dan in de formulebalk bovenaan (rood gemarkeerd in de schermafbeelding hierboven) roepen we de functie aan door "= LIJNSCH" te schrijven, waarna Excel geeft hints weer van wat nodig is voor deze functies, namelijk:
- selecteer een bereik met bekende waarden van de beschreven indicator Y (in ons geval GDP, in de screenshot is het bereik blauw gemarkeerd) en plaats een puntkomma
- geef het bereik van beïnvloedende factoren X aan (in ons geval is dit de t-indicator, het serienummer van punten, groen gemarkeerd in de schermafbeelding) en plaats een puntkomma
- de volgende vereiste parameter voor de functie is om te bepalen of het nodig is om de constante te berekenen, aangezien we in eerste instantie een model overwegen met een constante (coëfficiënt een 0 ), dan plaatsen we ofwel "TRUE" of "1" en een puntkomma
- dan moet u specificeren of de berekening van statistische parameters vereist is (als we deze optie zouden overwegen, zouden we in eerste instantie het bereik "onder de formule" een paar regels lager moeten selecteren). Geef de noodzaak aan om statistische parameters te berekenen, namelijk: standaardfout voor coëfficiënten, determinismecoëfficiënt, standaardfout voor Y, Fisher's criterium, vrijheidsgraden, enz., het heeft alleen zin als u begrijpt wat ze betekenen, in dit geval plaatsen we "TRUE" of "1". In het geval van vereenvoudigde modellering, die we proberen te leren, plaatsen we in dit stadium van het schrijven van de formule "FALSE" of "0" en voegen we een sluithaakje ")" toe na
- om de formule te "doen herleven", dat wil zeggen, om het te laten werken nadat alle noodzakelijke parameters zijn voorgeschreven, volstaat het niet om op de knop Enter te drukken, u moet drie toetsen achter elkaar ingedrukt houden: Ctrl, Shift, Enter

Zoals je kunt zien in de bovenstaande schermafbeelding, waren de cellen die we voor de formule selecteerden gevuld met de berekende waarden van de regressiecoëfficiënten voor de lineaire trend, in de cel B38 coëfficiënt is gevonden een 0 , en in de cel A38- afhankelijkheidscoëfficiënt van de parameter t (of x ), d.w.z een 1 . We vervangen de verkregen waarden in de vergelijking van een lineaire functie en krijgen het voltooide model in een wiskundige uitdrukking - y = 169572.2+138454.3*t
Om berekende waarden te krijgen ja volgens het model en dienovereenkomstig, om een prognose te krijgen, hoeft u alleen maar de formule in de Excel-cel te vervangen, en in plaats van t specificeer een link naar de cel met het vereiste periodenummer (zie de cel in de schermafbeelding) D25).
Om het resulterende model met echte gegevens te vergelijken, kunt u twee grafieken maken, waarbij u als X het serienummer van de periode aangeeft, en als Y in het ene geval - het reële BBP, en in het andere geval - de berekende (in de schermafbeelding , het diagram aan de rechterkant).
Een lineaire trend bouwen met behulp van de regressietool in het analysetoolpack
In het artikel wordt deze methode in feite volledig beschreven, het enige verschil is dat er in onze initiële gegevens slechts één beïnvloedende factor is X (periode nummer - t ).

Zoals te zien is in de bovenstaande afbeelding, gegevensbereik met bekende BBP-waarden gemarkeerd als invoerinterval Y, en de daarbij behorende bereik met periodenummers t - als invoerinterval X. De resultaten van berekeningen door het analysepakket worden op een apart blad geplaatst en zien eruit als een set tabellen (zie onderstaande figuur) waarop we geïnteresseerd zijn in de cellen die door mij in geel en groen zijn overschilderd. Naar analogie met de volgorde beschreven in het bovenstaande artikel, wordt een lineair trendmodel samengesteld uit de verkregen coëfficiënten y=169572.2+138454.3*t, op basis waarvan voorspellingen worden gedaan.

Prognose met een lineaire trend via de TREND-functie
Deze methode verschilt van de vorige doordat het de eerder noodzakelijke stappen voor het berekenen van de modelparameters overslaat en de verkregen coëfficiënten handmatig vervangt als een formule in een cel om een prognose te krijgen. Deze functie produceert alleen een kant-en-klare berekende voorspellende waarde op basis van bekende begingegevens.

In de doelcel (de cel waar we het resultaat willen zien) plaatsen we het teken gelijk aan en roep de magische functie op door te schrijven " TREND(”, dan moet je selecteren, dat wil zeggen, nadat we een puntkomma hebben geplaatst en we selecteren een bereik met bekende waarden van X, dat wil zeggen met het aantal perioden t, die overeenkomen met de kolom met bekende BBP-waarden, plaats opnieuw een puntkomma en selecteer de cel met het nummer van de periode waarvoor we een prognose maken (in ons geval kan het periodenummer echter niet worden aangegeven door te verwijzen naar de cel, maar gewoon door een getal direct in de formule), plaats dan nog een puntkomma en geef aan WAAR of 1 , als bevestiging voor het berekenen van de coëfficiënt een 0 eindelijk gezet haakje sluiten en druk op de toets Binnenkomen.
Het nadeel van deze methode is dat ze noch de modelvergelijking noch haar coëfficiënten laat zien, daarom kan niet worden gezegd dat we op basis van dat en dat model die en die voorspelling hebben ontvangen, en er is ook geen weerspiegeling van de kwaliteitsparameters van het model. , dezelfde determinatiecoëfficiënt, volgens welke het mogelijk zou zijn om te zeggen of het zinvol is om rekening te houden met de ontvangen voorspelling of niet.
Prognose met een lineaire trend via de FORECAST-functie
De essentie van deze functie is volledig identiek aan de vorige, het enige verschil is in de volgorde van het voorschrijven van de initiële gegevens in de formule en dat er geen instelling is voor de aan- of afwezigheid van een coëfficiënt een 0 (dat wil zeggen, de functie impliceert dat deze coëfficiënt toch bestaat)

Zoals je kunt zien in de bovenstaande afbeelding, schrijven we in de doelcel " = VOORSPELLING(” en specificeer vervolgens cel met periodenummer, waarvoor het nodig is om de waarde te berekenen volgens een lineaire trend, dat wil zeggen de voorspelling, plaats dan een puntkomma en selecteer vervolgens bereik van bekende Y-waarden, d.w.z kolom met bekende BBP-waarden, plaats dan een puntkomma en markeer bereik met bekende X-waarden, d.w.z met periodenummers t, die overeenkomen met de kolom met bekende BBP-waarden en tenslotte set haakje sluiten en druk op de toets Binnenkomen.
De verkregen resultaten, zoals in de bovenstaande methode, zijn slechts het uiteindelijke resultaat van het berekenen van de prognosewaarde met behulp van een lineair trendmodel; het geeft geen fouten of het model zelf in wiskundige termen.
Samenvattend het artikel
We kunnen zeggen dat elk van de methoden onder andere de meest acceptabele is, afhankelijk van het huidige doel dat we onszelf stellen. De eerste drie methoden kruisen elkaar zowel in betekenis als in resultaat, en zijn geschikt voor elk meer of minder serieus werk waarbij een beschrijving van het model en de kwaliteit ervan noodzakelijk is. De laatste twee methoden zijn op hun beurt weer identiek aan elkaar en geven u zo snel mogelijk antwoord op bijvoorbeeld de vraag: “Wat is de verkoopprognose voor het komende jaar?”.
Als we kijken naar elke set gegevens die in de tijd is verdeeld (tijdreeksen), kunnen we de ups en downs van de indicatoren die erin zitten visueel identificeren. Het patroon van ups en downs wordt een trend genoemd, die kan aangeven of onze gegevens toenemen of afnemen.
Misschien zal ik de serie artikelen over prognoses beginnen met het eenvoudigste: het bouwen van een trendfunctie. Laten we bijvoorbeeld verkoopgegevens nemen en een model bouwen dat de afhankelijkheid van verkoop op tijd beschrijft.
Basisconcepten
Ik denk dat iedereen sinds school bekend is met de lineaire functie, het ligt gewoon ten grondslag aan de trend:
Y(t) = a0 + a1*t + E
Y is het verkoopvolume, de variabele die we zullen verklaren door tijd en waarvan het afhangt, dat wil zeggen Y (t);
t is het nummer van de periode (serienummer van de maand), wat het verkoopplan Y verklaart;
a0 is de nul-regressiecoëfficiënt, die de waarde van Y(t) weergeeft, bij afwezigheid van de invloed van de verklarende factor (t=0);
a1 is de regressiecoëfficiënt, die aangeeft in hoeverre de onderzochte verkoopindicator Y afhangt van de beïnvloedende factor t;
E zijn willekeurige verstoringen die de invloed weerspiegelen van andere factoren waarmee in het model geen rekening is gehouden, behalve voor tijd t.
Model gebouw
We kennen dus het verkoopvolume van de afgelopen 9 maanden. Zo ziet ons bord eruit:
Het volgende dat we moeten doen, is de coëfficiënten bepalen a0 en a1 om het verkoopvolume voor de 10e maand te voorspellen.
Bepaling van modelcoëfficiënten
We bouwen een grafiek. Horizontaal zien we de lopende maanden, verticaal het verkoopvolume:
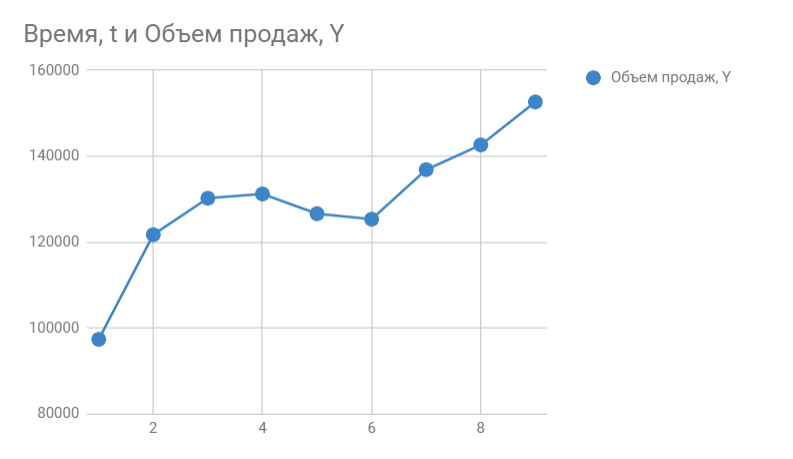
Kies in Google Spreadsheets Diagrameditor -> Aanvullend en vink het vakje aan naast trendlijnen. Kies in de instellingen Label — De vergelijking en Toon R^2.
Als je alles in MS Excel doet, klik dan met de rechtermuisknop op de grafiek en selecteer "Trendlijn toevoegen" in het vervolgkeuzemenu.
Standaard wordt er een lineaire functie gebouwd. Selecteer aan de rechterkant "Toon vergelijking in het diagram" en "R^2e".
Dit is wat er is gebeurd:

Op de grafiek zien we de vergelijking van de functie:
y = 4856*x + 105104
Het beschrijft het verkoopvolume afhankelijk van het nummer van de maand waarvoor we deze verkopen willen voorspellen. In de buurt zien we de determinatiecoëfficiënt R^2, die de kwaliteit van het model aangeeft en hoe goed het onze verkoop beschrijft (Y). Hoe dichter bij 1 hoe beter.
Ik heb R ^ 2 = 0,75. Dit is een gemiddelde indicator, het zegt dat het model geen rekening houdt met andere belangrijke factoren dan de tijd t, het kan bijvoorbeeld seizoensinvloeden zijn.
wij voorspellen
y = 4856*10 + 105104
We krijgen 153664 verkopen in de komende maand. Als we een nieuw punt aan de grafiek toevoegen, zien we meteen dat R^2 is verbeterd.

U kunt de gegevens dus enkele maanden van tevoren voorspellen, maar zonder rekening te houden met andere factoren, zal uw prognose op de trendlijn liggen en niet zo informatief zijn als u zou willen. Bovendien zal een langetermijnprognose die op deze manier wordt gemaakt, zeer benaderend zijn.
U kunt de nauwkeurigheid van het model vergroten door seizoensgebondenheid toe te voegen aan de trendfunctie, wat we in het volgende artikel zullen doen.
Grafieken en grafieken worden gebruikt om numerieke gegevens te analyseren, bijvoorbeeld om de relatie tussen twee soorten waarden te evalueren. Voor dit doel kunnen een trendlijn en de bijbehorende vergelijking worden toegevoegd aan de grafiek- of grafiekgegevens, prognosewaarden berekend voor meerdere perioden vooruit of achteruit.
trendlijn is een rechte of gebogen lijn die de oorspronkelijke gegevens benadert (benadert) op basis van een regressievergelijking of een voortschrijdend gemiddelde. De benadering wordt bepaald door de kleinste-kwadratenmethode. Afhankelijk van de aard van het gedrag van de initiële gegevens (afname, toename, enz.), wordt een interpolatiemethode gekozen die moet worden gebruikt om een trend op te bouwen.
Er zijn verschillende mogelijkheden om een trendlijn te vormen.
Lineaire functie: y=mx+b
waarbij m de tangens is van de helling van de rechte lijn, b de verplaatsing is.
Een rechte trendlijn (lineaire trend) is het beste voor hoeveelheden die met een constante snelheid veranderen. Gebruikt in gevallen waarin de gegevenspunten dicht bij een rechte lijn liggen.
Logaritmische functie: y=c*lnx+b
waarbij c en b constanten zijn.
Een logaritmische trendlijn komt overeen met een reeks gegevens die eerst snel stijgt of daalt en vervolgens geleidelijk stabiliseert. Kan worden gebruikt voor positieve en negatieve gegevens.
Polynoomfunctie (tot en met de 6e graad): y= b + c 1 *x + c 2 *x 2 + c 3 *x 3 + ...+ c 6* x 6
waarbij b, c 1 , c 2 , ... c 6 constanten zijn.
Een polynomiale trendlijn wordt gebruikt om afwisselend stijgende en dalende gegevens te beschrijven. De graad van de polynoom wordt zo gekozen dat deze één meer is dan het aantal extrema (maxima en minima) van de kromme.
Power functie: y=cxb
waarbij c en b constanten zijn.
De vermogenstrendlijn geeft goede resultaten voor positieve gegevens met constante versnelling. Voor reeksen met nul of negatieve waarden kan de opgegeven trendlijn niet worden getekend.
Exponentiële functie: y=cebx
waar c en b constanten zijn, is e de basis van de natuurlijke logaritme.
Een exponentiële trend wordt gebruikt in het geval van een continue toename van gegevensverandering. De constructie van de gespecificeerde trend is onmogelijk als de reeks waarden van de reeksleden nul of negatieve gegevens bevat.
Lineaire filtering gebruiken volgens de formule: F t = (A t +A (t-1) +⋯+A (t-n+1))/n
waarbij n het totale aantal leden van de reeks is, t het gegeven aantal punten (2 ≤ t< n).
Een trend met lineaire filtering stelt u in staat gegevensfluctuaties af te vlakken, waardoor de aard van afhankelijkheden duidelijk wordt aangetoond. Om de gespecificeerde trendlijn te bouwen, moet de gebruiker een nummer specificeren - de filterparameter. Als het getal 2 is, wordt het eerste punt van de trendlijn gedefinieerd als het gemiddelde van de eerste twee gegevensitems, het tweede punt is het gemiddelde van de tweede en derde gegevensitems, enzovoort.
Voor sommige soorten grafieken kan de trendlijn in principe niet worden gebouwd - gestapelde grafieken, volumegrafieken, bloembladgrafieken, cirkelgrafieken, oppervlaktegrafieken, ringgrafieken. Indien mogelijk kunnen meerdere regels met verschillende parameters aan het diagram worden toegevoegd. De overeenstemming van de trendlijn met de werkelijke waarden van de gegevensreeks wordt vastgesteld met behulp van der:
De trendlijn, evenals zijn parameters, worden toegevoegd aan de grafiekgegevens met de volgende opdrachten:

Indien nodig kunnen de parameters van de lijn worden gewijzigd door op de gegevensreeks van de grafiek of de trendlijn te klikken, het venster Trendlijn opmaken. U kunt een regressievergelijking, een btoevoegen (of verwijderen), de richting en voorspelling van een verandering in een gegevensreeks bepalen en ook de ontwerpelementen van een trendlijn corrigeren. De gemarkeerde trendlijn kan ook worden verwijderd.
De afbeelding toont een tabel met gegevens over veranderingen in de waarde van een effect. Op basis van deze voorwaardelijke gegevens werd een spreidingsdiagram gebouwd, een derde-orde polynoom trendlijn (gegeven door een stippellijn) en enkele andere parameters toegevoegd. De verkregen waarde van de benaderingsbetrouwbaarheidscoëfficiënt R2 in het diagram ligt dicht bij één, wat aangeeft dat de berekende trendlijn dicht bij de probleemgegevens ligt. De voorspelde waarde van de verandering in de waarde van het effect is gericht op groei.
plotten
Regressie analyse
regressievergelijking ja van X functionele afhankelijkheid genoemd y=f(x), en de plot is een regressielijn.
Met Excel kunt u grafieken en grafieken van redelijk acceptabele kwaliteit maken. Excel heeft een speciaal hulpmiddel - de Grafiekwizard, onder wiens begeleiding de gebruiker alle vier de fasen van het proces van het maken van een grafiek of grafiek doorloopt.
In de regel begint de constructie van een grafiek met de selectie van een bereik met de gegevens waarop deze moet worden gebouwd. Zo'n begin vereenvoudigt het verdere verloop van het plotten. Het bereik met de initiële gegevens kan echter ook worden verdeeld in de tweede fase van de dialoog met MASTER VAN DIAGRAM. In Excel 2003 MASTER VAN DIAGRAM is in het menu in de vorm van een knop of een diagram kan worden gemaakt door op het tabblad te klikken INSERT en zoek het item in de lijst die wordt geopend DIAGRAM. In Excel 2007 vinden we ook het tabblad INSERT(Afb. 31).

Rijst. 31. MASTER VAN DIAGRAM in Excel 2007
De eenvoudigste manier om het brongegevensbereik te selecteren waarin deze gegevens zich in aangrenzende rijen (kolommen of rijen) bevinden, is door op de cel linksboven in het bereik te klikken en vervolgens de muisaanwijzer naar de cel rechtsonder in het bereik te slepen. Wanneer u gegevens in niet-aangrenzende rijen selecteert, sleept u de muisaanwijzer over de geselecteerde rijen terwijl u de Ctrl-toets ingedrukt houdt. Als een van de gegevensreeksen een cel met een titel heeft, moet de andere geselecteerde reeks ook een overeenkomstige cel hebben, ook als deze leeg is.
Voor regressieanalyse kunt u het beste een spreidingsdiagram gebruiken (Fig. 30). Bij het plotten behandelt Excel de eerste rij van het geselecteerde bereik van brongegevens als een reeks waarden voor het argument van de functies waarvan de grafieken moeten worden geplot (dezelfde set voor alle functies). De volgende rijen worden gezien als reeksen waarden van de functies zelf (elke rij bevat de waarden van een van de functies die overeenkomen met de gegeven argumentwaarden die zich in de eerste rij van het geselecteerde bereik bevinden).
In Excel 2007 worden astitels in het menutabblad geplaatst INDELING(Afb. 32).
Rijst. 32. De namen van de grafiekassen instellen in Excel 2007
Om een wiskundig model te verkrijgen, is het noodzakelijk om een trendlijn op de grafiek te tekenen. Klik in Excel 2003 en 2007 met de rechtermuisknop op de grafiekpunten. Dan verschijnt in Excel 2003 een tabblad met een lijst met items waaruit we selecteren TRENDLIJN TOEVOEGEN(Afb. 33).

Rijst. 33. TRENDLIJN TOEVOEGEN
Na het klikken op het item TRENDLIJN TOEVOEGEN er verschijnt een venster TRENDLIJN(Afb. 34). Op het tabblad TYPE kunt u de volgende soorten lijnen selecteren: lineair, logaritmisch, exponentieel, exponentieel, polynoom, lineair filteren.

Rijst. 34. Venster TRENDLIJN in Excel 2003
Op het tabblad OPTIES(Fig. 35) vink het vakje aan naast de items TOON VERGELIJKING OP DE DIAGRAM, dan zal een wiskundig model van deze afhankelijkheid op de grafiek verschijnen. We zetten ook een vinkje voor het item TOON OP HET DIAGRAM DE WAARDE VAN DE BETROUWBAARHEID VAN DE BENAMING (R^2). Hoe dichter de bbij 1 ligt, hoe dichter de geselecteerde curve de punten op de grafiek nadert. Klik vervolgens op de knop Oké. Er verschijnt een trendlijn op de grafiek, de bijbehorende vergelijking en de waarde van de benaderingsbetrouwbaarheid.

Rijst. 35. Tab OPTIES
Nadat we in Excel 2007 met de rechtermuisknop op de grafiekpunten hebben geklikt, verschijnt een lijst met menu-items, waaruit: KIES TRENDLIJN TOEVOEGEN(Afb. 36).

Rijst. 36. TRENDLIJN TOEVOEGEN

Rijst. 37. Tab TREND LIJN PARAMETERS
Stel de vereiste selectievakjes in en klik op de knop DICHTBIJ.
Er verschijnt een trendlijn op de grafiek, de bijbehorende vergelijking en de waarde van de benaderingsbetrouwbaarheid.
Meest voorkomend de trend wordt weergegeven door een lineaire relatie van de onderzochte hoeveelheid van het formulier
waarbij y de te bestuderen variabele is (bijvoorbeeld productiviteit) of de afhankelijke variabele;
x is een getal dat de positie (tweede, derde, etc.) van het jaar in de prognoseperiode bepaalt, of een onafhankelijke variabele.
Bij een lineaire benadering van de relatie tussen twee parameters wordt meestal de kleinste-kwadratenmethode gebruikt om de empirische coëfficiënten van een lineaire functie te vinden. De essentie van de methode is dat de lineaire functie van de "best fit" door de punten van de grafiek gaat die overeenkomen met het minimum van de som van de gekwadrateerde afwijkingen van de gemeten parameter. Een dergelijke toestand ziet er als volgt uit:

waarbij n het volume van de bestudeerde populatie is (het aantal waarnemingseenheden).

Rijst. 5.3. Een trend bouwen met de kleinste-kwadratenmethode
De waarden van de constanten b en a of de coëfficiënt van de variabele X en de vrije term van de vergelijking worden bepaald door de formule:

In tafel. 5.1 toont een voorbeeld van het berekenen van een lineaire trend op basis van gegevens.
Tabel 5.1. Lineaire trendberekening

Methoden voor het afvlakken van trillingen.
Met sterke discrepanties tussen aangrenzende waarden, is de trend die wordt verkregen door de regressiemethode moeilijk te analyseren. Bij prognoses, wanneer een reeks gegevens bevat met een grote spreiding van fluctuaties in aangrenzende waarden, moeten deze worden afgevlakt volgens bepaalde regels en vervolgens naar betekenis in de prognose zoeken. Naar de methode om trillingen te verzachten
omvatten: voortschrijdend gemiddelde methode (een n-punts gemiddelde wordt berekend), exponentiële afvlakkingsmethode. Laten we ze eens bekijken.
De methode van " voortschrijdende gemiddelden " (MSA).
Met MCC kunt u een reeks waarden gladstrijken om een trend te markeren. Deze methode neemt het gemiddelde (meestal het rekenkundig gemiddelde) van een vast aantal waarden. Bijvoorbeeld een voortschrijdend gemiddelde van drie punten. Het eerste drietal waarden wordt genomen, bestaande uit gegevens voor januari, februari en maart (10 + 12 + 13), en het gemiddelde wordt bepaald, gelijk aan 35: 3 = 11,67.
De resulterende waarde van 11,67 wordt in het midden van het bereik geplaatst, d.w.z. op de februarilijn. Dan "schuiven we met een maand" en nemen de tweede drie getallen, beginnend van februari tot april (12 + 13 + 16), en berekenen het gemiddelde gelijk aan 41: 3 = 13,67, en op deze manier verwerken we de gegevens voor de hele serie. De resulterende gemiddelden vertegenwoordigen een nieuwe gegevensreeks voor het bouwen van een trend en de benadering ervan. Hoe meer punten er worden genomen om het voortschrijdend gemiddelde te berekenen, hoe sterker de fluctuaties worden afgevlakt. Een voorbeeld van de MVA van het bouwen van een trend wordt gegeven in Tabel. 5.2 en in afb. 5.4.
Tabel 5.2 Berekening van de trend met de driepunts voortschrijdend gemiddelde methode

De aard van de fluctuaties van de initiële gegevens en gegevens verkregen door de voortschrijdend gemiddelde methode wordt geïllustreerd in Fig. 5.4. Uit een vergelijking van de grafieken van de reeks beginwaarden (rij 3) en voortschrijdende driepuntsgemiddelden (rij 4) blijkt dat fluctuaties kunnen worden afgevlakt. Hoe groter het aantal punten in het bereik van de berekening van het voortschrijdend gemiddelde, hoe duidelijker de trend zal verschijnen (rij 1). Maar de procedure voor het vergroten van het bereik leidt tot een vermindering van het aantal eindwaarden, en dit vermindert de nauwkeurigheid van de voorspelling.
Prognoses moeten worden gemaakt op basis van schattingen van de regressielijn, samengesteld uit de waarden van de oorspronkelijke gegevens of voortschrijdende gemiddelden.

Rijst. 5.4. De aard van de verandering in verkoop per maand van het jaar:
initiële gegevens (rij 3); voortschrijdende gemiddelden (rij 4); exponentiële afvlakking (rij 2); regressietrend (rij 1)
Exponentiële afvlakkingsmethode.
Een alternatieve benadering om de spreiding van reekswaarden te verminderen, is om de exponentiële afvlakkingsmethode te gebruiken. De methode wordt "exponentiële afvlakking" genoemd vanwege het feit dat elke waarde van perioden die in het verleden gaan, met een factor (1 - α) wordt verminderd.
Elke afgevlakte waarde wordt berekend met een formule zoals:
St =aYt +(1−α)St−1,
waarbij St de huidige afgevlakte waarde is;
Yt is de huidige waarde van de tijdreeks; St - 1 - vorige afgevlakte waarde; α is een afvlakkingsconstante, 0 ≤ α ≤ 1.
Hoe kleiner de waarde van de constante α , hoe minder gevoelig deze is voor trendveranderingen in een bepaalde tijdreeks.