Примеры SQL запросов к базе данных MySQL. Специальные инструкции и предложения
Как узнать количество моделей ПК, выпускаемых тем или иным поставщиком? Как определить среднее значение цены на компьютеры, имеющие одинаковые технические характеристики? На эти и многие другие вопросы, связанные с некоторой статистической информацией, можно получить ответы при помощи итоговых (агрегатных) функций . Стандартом предусмотрены следующие агрегатные функции:
Все эти функции возвращают единственное значение. При этом функции COUNT, MIN и MAX применимы к любым типам данных, в то время как SUM и AVG используются только для числовых полей. Разница между функцией COUNT(*) и COUNT(<имя поля>) состоит в том, что вторая при подсчете не учитывает NULL-значения.
Пример. Найти минимальную и максимальную цену на персональные компьютеры:
Пример. Найти имеющееся в наличии количество компьютеров, выпущенных производителем А:
Пример. Если же нас интересует количество различных моделей, выпускаемых производителем А, то запрос можно сформулировать следующим образом (пользуясь тем фактом, что в таблице Product каждая модель записывается один раз):
Пример. Найти количество имеющихся различных моделей, выпускаемых производителем А. Запрос похож на предыдущий, в котором требовалось определить общее число моделей, выпускаемых производителем А. Здесь же требуется найти число различных моделей в таблице PC (т.е. имеющихся в продаже).
Для того, чтобы при получении статистических показателей использовались только уникальные значения, при аргументе агрегатных функций можно использовать параметр DISTINCT . Другой параметр ALL используется по умолчанию и предполагает подсчет всех возвращаемых значений в столбце. Оператор,
Если же нам требуется получить количество моделей ПК, производимых каждым производителем, то потребуется использовать предложение GROUP BY , синтаксически следующего после предложения WHERE .
Предложение GROUP BY
Предложение GROUP BY используется для определения групп выходных строк, к которым могут применяться агрегатные функции (COUNT, MIN, MAX, AVG и SUM) . Если это предложение отсутствует, и используются агрегатные функции, то все столбцы с именами, упомянутыми в SELECT , должны быть включены в агрегатные функции , и эти функции будут применяться ко всему набору строк, которые удовлетворяют предикату запроса. В противном случае все столбцы списка SELECT, не вошедшие в агрегатные функции, должны быть указаны в предложении GROUP BY . В результате чего все выходные строки запроса разбиваются на группы, характеризуемые одинаковыми комбинациями значений в этих столбцах. После этого к каждой группе будут применены агрегатные функции. Следует иметь в виду, что для GROUP BY все значения NULL трактуются как равные, т.е. при группировке по полю, содержащему NULL-значения, все такие строки попадут в одну группу.Если при наличии предложения GROUP BY , в предложении SELECT отсутствуют агрегатные функции , то запрос просто вернет по одной строке из каждой группы. Эту возможность, наряду с ключевым словом DISTINCT, можно использовать для исключения дубликатов строк в результирующем наборе.
Рассмотрим простой пример:
| SELECT model, COUNT(model) AS Qty_model, AVG(price) AS Avg_price FROM PC GROUP BY model; |
В этом запросе для каждой модели ПК определяется их количество и средняя стоимость. Все строки с одинаковыми значениями model (номер модели) образуют группу, и на выходе SELECT вычисляются количество значений и средние значения цены для каждой группы. Результатом выполнения запроса будет следующая таблица:
| model | Qty_model | Avg_price |
| 1121 | 3 | 850.0 |
| 1232 | 4 | 425.0 |
| 1233 | 3 | 843.33333333333337 |
| 1260 | 1 | 350.0 |
Если бы в SELECT присутствовал столбец с датой, то можно было бы вычислять эти показатели для каждой конкретной даты. Для этого нужно добавить дату в качестве группирующего столбца, и тогда агрегатные функции вычислялись бы для каждой комбинации значений (модель−дата).
Существует несколько определенных правил выполнения агрегатных функций :
- Если в результате выполнения запроса не получено ни одной строки (или не одной строки для данной группы), то исходные данные для вычисления любой из агрегатных функций отсутствуют. В этом случае результатом выполнения функций COUNT будет нуль, а результатом всех других функций - NULL.
- Аргумент агрегатной функции не может сам содержать агрегатные функции (функция от функции). Т.е. в одном запросе нельзя, скажем, получить максимум средних значений.
- Результат выполнения функции COUNT есть целое число (INTEGER). Другие агрегатные функции наследуют типы данных обрабатываемых значений.
- Если при выполнении функции SUM был получен результат, превышающий максимальное значение используемого типа данных, возникает ошибка .
Итак, если запрос не содержит предложения GROUP BY , то агрегатные функции , включенные в предложение SELECT , исполняются над всеми результирующими строками запроса. Если запрос содержит предложение GROUP BY , каждый набор строк, который имеет одинаковые значения столбца или группы столбцов, заданных в предложении GROUP BY , составляет группу, и агрегатные функции выполняются для каждой группы отдельно.
Предложение HAVING
Если предложение WHERE определяет предикат для фильтрации строк, то предложение HAVING применяется после группировки для определения аналогичного предиката, фильтрующего группы по значениям агрегатных функций . Это предложение необходимо для проверки значений, которые получены с помощью агрегатной функции не из отдельных строк источника записей, определенного в предложении FROM , а из групп таких строк . Поэтому такая проверка не может содержаться в предложении WHERE .
Каждый веб-разработчик должен знать SQL, чтобы писать запросы к базам данных. И, хотя, phpMyAdmin никто не отменял, зачастую необходимо испачкать руки, чтобы написать низкоуровневый SQL.
Именно поэтому мы подготовили краткий экскурс по основам SQL. Начнем же!
1. Создание таблицы
Для создания таблиц предназначена инструкция CREATE TABLE . В качестве аргументов должно быть задано название столбцов, а также их типы данных.
Создадим простую таблицу по имени month . Она состоит из 3 колонок:
- id – Номер месяца в календарном году (целое число).
- name – Название месяца (строка, максимум 10 символов).
- days – Количество дней в этом месяце (целое число).
Вот как будет выглядеть соответствующий SQL запрос:
CREATE TABLE months (id int, name varchar(10), days int);
Также при создании таблиц целесообразно добавить первичный ключ для одной из колонок. Это позволит держать записи уникальными и ускорит запросы на выборку. Пусть в нашем случае уникальным будет название месяца (столбец name )
CREATE TABLE months (id int, name varchar(10), days int, PRIMARY KEY (name));
| Тип данных | Описание |
|---|---|
| DATE | Значения даты |
| DATETIME | Значения даты и времени с точностью до минты |
| TIME | Значения времени |
2. Вставка строк
Теперь давайте заполнять нашу таблицу months полезной информацией. Добавление записей в таблицу производится через инструкцию INSERT . Есть два способа записи этой инструкции.
Первый способ не указать имена столбцов, куда будут вставлены данные, а указать только значения.
Этот способ записи прост, но небезопасен, поскольку нет гарантии, что по мере расширения проекта и редактировании таблицы, столбцы будут располагаться в том же порядке, что и ранее. Безопасный (и в тоже время более громоздкий) способ записи инструкции INSERT требует указания как значений, так и порядка следования столбцов:
Здесь первое значение в списке VALUES соответствует первому указанному имени столбца и т.д.
3. Извлечение данных из таблиц
Инструкция SELECT - наш лучший друг, когда мы хотим получить данные из базы данных. Она используется очень часто, так что отнеситесь к этому разделу очень внимательно.
Самый простое использование инструкции SELECT - запрос, который возвращает все столбцы и строки из таблицы (например, таблицы по имени characters ):
SELECT * FROM "characters"
Символ звездочка (*) означает, что мы хотим получить данные из всех столбцов. Так базы данных SQL обычно состоят из более чем одной таблицы, то требуется обязательно указывать ключевое слово FROM , следом за которым через пробел должно следовать название таблицы.
Иногда мы не хотим получить данные не из всех столбцов в таблице. Для этого, вместо звездочки (*) мы должны через запятую записать имена желаемых столбцов.
SELECT id, name FROM month
Кроме того, во многих случаях мы хотим, чтобы полученные результаты были отсортированы в определенном порядке. В SQL мы делаем это с помощью ORDER BY . Он может принимать опциональный модификатор – ASC (по-умолчанию) сортирующий по возрастанию или DESC , сортирующий по убыванию:
SELECT id, name FROM month ORDER BY name DESC
При использовании ORDER BY убедитесь, что оно будет последним в инструкции SELECT . В противном случае будет выдано сообщение об ошибке.
4. Фильтрация данных
Вы узнали, как выбрать из базы данных с помощью SQL запроса строго определенные столбцы, но что если нам нужно получить еще и определенные строки? На помощь здесь приходит условие WHERE , позволяющее нам фильтровать данные в зависимости от условия.
В этом запросе мы выбираем только те месяцы из таблицы month , в которых больше 30 дней с помощью оператора больше (>).
SELECT id, name FROM month WHERE days > 30
5. Расширенная фильтрация данных. Операторы AND и OR
Ранее мы использовали фильтрацию данных с использованием одного критерия. Для более сложной фильтрации данных можно использовать операторы AND и OR и операторов сравнения (=,<,>,<=,>=,<>).
Здесь мы имеем таблицу, содержащую четыре самых продаваемых альбомов всех времен. Давайте выберем те из них, которые классифицируются как рок и у которых менее 50 миллионов проданных копий. Это можно легко сделать путем размещения оператора AND между этими двумя условиями.
 SELECT *
FROM albums
WHERE genre = "рок" AND sales_in_millions <= 50
ORDER BY released
SELECT *
FROM albums
WHERE genre = "рок" AND sales_in_millions <= 50
ORDER BY released
6. In/Between/Like
WHERE также поддерживает несколько специальных команд, позволяя быстро проверять наиболее часто используемые запросы. Вот они:
- IN – служит для указания диапазона условий, любое из которых может быть выполнено
- BETWEEN – проверяет, находится ли значение в указанном диапазоне
- LIKE – ищет по определенным паттернам
Например, если мы хотим выбрать альбомы с поп и соул музыкой, мы можем использовать IN("value1","value2") .
SELECT * FROM albums WHERE genre IN ("pop","soul");
Если мы хотим получить все альбомы, изданные между 1975 и 1985годами, мы должны записать:
SELECT * FROM albums WHERE released BETWEEN 1975 AND 1985;
7. Функции
SQL напичкан с функциями, которые делают разные полезные вещи. Вот некоторые из наиболее часто используемых:
- COUNT() – возвращает количество строк
- SUM() – возвращает общую сумму числового столбца
- AVG() – возвращает среднее значение из множества значений
- MIN() / MAX() – получает минимальное / максимальное значение из столбца
Чтобы получить самый последний год в нашей таблице мы должны записать такой SQL запрос:
SELECT MAX(released) FROM albums;
8. Подзапросы
В предыдущем пункте мы научились делать простые расчеты с данными. Если мы хотим использовать результат от этих расчетов, нам не обойтись без вложенных запросов. Допустим, мы хотим вывести artist , album и release year для старейшего альбома в таблице.
Мы знаем, как получить эти конкретные столбцы:
SELECT artist, album, released FROM albums;
Мы также знаем, как получить самый ранний год:
SELECT MIN(released) FROM album;
Все, что нужно сейчас, - это объединить два запроса с помощью WHERE:
SELECT artist,album,released FROM albums WHERE released = (SELECT MIN(released) FROM albums);
9. Объединение таблиц
В более сложных базах данных существует несколько таблиц, связанных друг с другом. Например, ниже представлены две таблицы о видеоиграх (video_games ) и разработчиков видеоигр (game_developers ).


В таблице video_games есть колонка разработчик (developer_id ), но в ней содержится целое число, а не имя разработчика. Это число представляет собой идентификатор (id ) соответствующего разработчика из таблицы разработчиков игр (game_developers ), связывая логически два списка, что позволяет нам использовать информацию, хранящуюся в них обоих одновременно.
Если мы хотим создать запрос, который возвращает все, что нужно знать об играх, мы можем использовать INNER JOIN для связи колонок из обеих таблиц.
SELECT video_games.name, video_games.genre, game_developers.name, game_developers.country FROM video_games INNER JOIN game_developers ON video_games.developer_id = game_developers.id;
Это самый простой и наиболее распространенный тип JOIN . Есть несколько других вариантов, но они применимы к менее частым случаям.
10. Алиасы
Если вы посмотрите на предыдущий пример, то вы заметите, что существуют две колонки называемые name . Это сбивает с толку, так что давайте установим псевдоним одного из повторяющихся столбцов, например, name из таблицы game_developers будет называться developer .
Мы также можем сократить запрос задав псевдонимы имен таблиц: video_games назовем games , game_developers - devs :
SELECT games.name, games.genre, devs.name AS developer, devs.country FROM video_games AS games INNER JOIN game_developers AS devs ON games.developer_id = devs.id;
11. Обновление данных
Часто мы должны изменить данные в некоторых строках. В SQL это делается с помощью инструкции UPDATE . Инструкция UPDATE состоит из:
- Таблицы, в которой находится значение для замены;
- Имен столбцов и их новых значений;
- Выбранные с помощью WHERE строки, которые мы хотим обновить. Если этого не сделать, то изменятся все строки в таблице.
Ниже приведена таблица tv_series с сериалами с их рейтингом. Однако, в таблицу закралась маленькая ошибка: хотя сериал Игра престолов и описывается как комедия, он на самом деле ей не является. Давайте исправим это!
 Данные таблицы tv_series
UPDATE tv_series SET genre = "драма" WHERE id = 2;
Данные таблицы tv_series
UPDATE tv_series SET genre = "драма" WHERE id = 2;
12. Удаление данных
Удаление строки таблицы с помощью SQL - это очень простой процесс. Все, что вам нужно, - это выбрать таблицу и строку, которую нужно удалить. Давайте удалим из предыдущего примера последнюю строку в таблице tv_series . Делается это с помощью инструкции >DELETE
DELETE FROM tv_series WHERE id = 4
Будьте осторожными при написании инструкции DELETE и убедитесь, что условие WHERE присутствует, иначе все строки таблицы будут удалены!
13. Удаление таблицы
Если мы хотим, чтобы удалить все строки, но оставить саму таблицу, то воспользуйтесь командой TRUNCATE:
TRUNCATE TABLE table_name;
В случае, когда мы на самом деле хотим, чтобы удалить и данные, и саму таблицу, то нам пригодится команда DROP:
DROP TABLE table_name;
Будьте очень осторожны с этими командами. Их нельзя отменить!/p>
На этом мы завершаем наш учебник по SQL! Мы многое о чем не рассказали, но то, что вы уже знаете, должно быть достаточно, чтобы дать вам несколько практических навыков в вашей веб-карьере.
Запросы написаны без экранирующих кавычек, так как у MySQL , MS SQL и PostGree они разные.
SQL запрос: получение указанных (нужных) полей из таблицы
SELECT id, country_title, count_people FROM table_nameПолучаем список записей: ВСЕ страны и их население. Название нужных полей указываются через запятую.
SELECT * FROM table_name
* обозначает все поля. То есть, будут показы АБСОЛЮТНО ВСЕ поля данных.
SQL запрос: вывод записей из таблицы исключая дубликаты
SELECT DISTINCT country_title FROM table_nameПолучаем список записей: страны, где находятся наши пользователи. Пользователей может быть много из одной страны. В этом случае это ваш запрос.
SQL запрос: вывод записей из таблицы по заданному условию
SELECT id, country_title, city_title FROM table_name WHERE count_people>100000000Получаем список записей: страны, где количество людей больше 100 000 000.
SQL запрос: вывод записей из таблицы с упорядочиванием
SELECT id, city_title FROM table_name ORDER BY city_titleПолучаем список записей: города в алфавитном порядке. В начале А, в конце Я.
SELECT id, city_title FROM table_name ORDER BY city_title DESC
Получаем список записей: города в обратном (DESC ) порядке. В начале Я, в конце А.
SQL запрос: подсчет количества записей
SELECT COUNT(*) FROM table_nameПолучаем число (количество) записей в таблице. В данном случае НЕТ списка записей.
SQL запрос: вывод нужного диапазона записей
SELECT * FROM table_name LIMIT 2, 3Получаем 2 (вторую) и 3 (третью) запись из таблицы. Запрос полезен при создании навигации на WEB страницах.
SQL запросы с условиями
Вывод записей из таблицы по заданному условию с использованием логических операторов.
SQL запрос: конструкция AND (И)
SELECT id, city_title FROM table_name WHERE country="Россия" AND oil=1Получаем список записей: города из России И имеют доступ к нефти. Когда используется оператор AND , то должны совпадать оба условия.
SQL запрос: конструкция OR (ИЛИ)
SELECT id, city_title FROM table_name WHERE country="Россия" OR country="США"Получаем список записей: все города из России ИЛИ США. Когда используется оператор OR , то должно совпадать ХОТЯ БЫ одно условие.
SQL запрос: конструкция AND NOT (И НЕ)
SELECT id, user_login FROM table_name WHERE country="Россия" AND NOT count_comments<7Получаем список записей: все пользователи из России И сделавших НЕ МЕНЬШЕ 7 комментариев.
SQL запрос: конструкция IN (В)
SELECT id, user_login FROM table_name WHERE country IN ("Россия", "Болгария", "Китай")Получаем список записей: все пользователи, которые проживают в (IN ) (России, или Болгарии, или Китая)
SQL запрос: конструкция NOT IN (НЕ В)
SELECT id, user_login FROM table_name WHERE country NOT IN ("Россия","Китай")Получаем список записей: все пользователи, которые проживают не в (NOT IN ) (России или Китае).
SQL запрос: конструкция IS NULL (пустые или НЕ пустые значения)
SELECT id, user_login FROM table_name WHERE status IS NULLПолучаем список записей: все пользователи, где status не определен. NULL это отдельная тема и поэтому она проверяется отдельно.
SELECT id, user_login FROM table_name WHERE state IS NOT NULL
Получаем список записей: все пользователи, где status определен (НЕ НОЛЬ).
SQL запрос: конструкция LIKE
SELECT id, user_login FROM table_name WHERE surname LIKE "Иван%"Получаем список записей: пользователи, у которых фамилия начинается с комбинации «Иван». Знак % означает ЛЮБОЕ количество ЛЮБЫХ символов. Чтобы найти знак % требуется использовать экранирование «Иван\%».
SQL запрос: конструкция BETWEEN
SELECT id, user_login FROM table_name WHERE salary BETWEEN 25000 AND 50000Получаем список записей: пользователи, которые получает зарплату от 25000 до 50000 включительно.
Логических операторов ОЧЕНЬ много, поэтому детально изучите документацию по SQL серверу.
Сложные SQL запросы
SQL запрос: объединение нескольких запросов
(SELECT id, user_login FROM table_name1) UNION (SELECT id, user_login FROM table_name2)Получаем список записей: пользователи, которые зарегистрированы в системе, а также те пользователи, которые зарегистрированы на форуме отдельно. Оператором UNION можно объединить несколько запросов. UNION действует как SELECT DISTINCT, то есть отбрасывает повторяющиеся значения. Чтобы получить абсолютно все записи, нужно использовать оператор UNION ALL.
SQL запрос: подсчеты значений поля MAX, MIN, SUM, AVG, COUNT
Вывод одного, максимального значения счетчика в таблице:
SELECT MAX(counter) FROM table_nameВывод одного, минимальный значения счетчика в таблице:
SELECT MIN(counter) FROM table_nameВывод суммы всех значений счетчиков в таблице:
SELECT SUM(counter) FROM table_nameВывод среднего значения счетчика в таблице:
SELECT AVG(counter) FROM table_nameВывод количества счетчиков в таблице:
SELECT COUNT(counter) FROM table_nameВывод количества счетчиков в цехе №1, в таблице:
SELECT COUNT(counter) FROM table_name WHERE office="Цех №1"Это самые популярные команды. Рекомендуется, где это возможно, использовать для подсчета именно SQL запросы такого рода, так как ни одна среда программирования не сравнится в скорости обработки данных, чем сам SQL сервер при обработке своих же данных.
SQL запрос: группировка записей
SELECT continent, SUM(country_area) FROM country GROUP BY continentПолучаем список записей: с названием континента и с суммой площадей всех их стран. То есть, если есть справочник стран, где у каждой страны записана ее площадь, то с помощью конструкции GROUP BY можно узнать размер каждого континента (на основе группировки по континентам).
SQL запрос: использование нескольких таблиц через алиас (alias)
SELECT o.order_no, o.amount_paid, c.company FROM orders AS o, customer AS с WHERE o.custno=c.custno AND c.city="Тюмень"Получаем список записей: заказы от покупателей, которые проживают только в Тюмени.
На самом деле, при правильном запроектированной базе данных данного вида запрос является самым частым, поэтому в MySQL был введен специальный оператор, который работает в разы быстрее, чем выше написанный код.
SELECT o.order_no, o.amount_paid, z.company FROM orders AS o LEFT JOIN customer AS z ON (z.custno=o.custno)
Вложенные подзапросы
SELECT * FROM table_name WHERE salary=(SELECT MAX(salary) FROM employee)Получаем одну запись: информацию о пользователе с максимальным окладом.
Внимание! Вложенные подзапросы являются одним из самых узких мест в SQL серверах. Совместно со своей гибкостью и мощностью, они также существенно увеличивают нагрузку на сервер. Что приводит к катастрофическому замедлению работы других пользователей. Очень часты случаи рекурсивных вызовов при вложенных запросах. Поэтому настоятельно рекомендую НЕ использовать вложенные запросы, а разбивать их на более мелкие. Либо использовать вышеописанную комбинацию LEFT JOIN. Помимо этого данного вида запросы являются повышенным очагом нарушения безопасности. Если решили использовать вложенные подзапросы, то проектировать их нужно очень внимательно и первоначальные запуски сделать на копиях баз (тестовые базы).
SQL запросы изменяющие данные
SQL запрос: INSERT
Инструкция INSERT позволяют вставлять записи в таблицу. Простыми словами, создать строчку с данными в таблице.
Вариант №1. Часто используется инструкция:
INSERT INTO table_name (id, user_login) VALUES (1, "ivanov"), (2, "petrov")В таблицу «table_name » будет вставлено 2 (два) пользователя сразу.
Вариант №2. Удобнее использовать стиль:
INSERT table_name SET id=1, user_login="ivanov"; INSERT table_name SET id=2, user_login="petrov";В этом есть свои преимущества и недостатки.
Основные недостатки:
- Множество мелких SQL запросов выполняются чуть медленнее, чем один большой SQL запрос, но при этом другие запросы будут стоять в очереди на обслуживание. То есть, если большой SQL запрос будет выполняться 30 минут, то в все это время остальные запросы будут курить бамбук и ждать своей очереди.
- Запрос получается массивнее, чем предыдущий вариант.
Основные преимущества:
- Во время мелких SQL запросов, другие SQL запросы не блокируются.
- Удобство в чтении.
- Гибкость. В этом варианте, можно не соблюдать структуру, а добавлять только необходимые данные.
- При формировании подобным образом архивов, можно легко скопировать одну строчку и запустить ее через командную строку (консоль), тем самым не восстанавливая АРХИВ целиком.
- Стиль записи схож с инструкцией UPDATE, что легче запоминается.
SQL запрос: UPDATE
UPDATE table_name SET user_login="ivanov", user_surname="Иванов" WHERE id=1В таблице «table_name » в записи с номером id=1, будет изменены значения полей user_login и user_surname на указанные значения.
SQL запрос: DELETE
DELETE FROM table_name WHERE id=3В таблице table_name будет удалена запись с id номером 3.
- Все названия полей рекомендуются писать маленькими буквами и если надо, разделять их через принудительный пробел «_» для совместимости с разными языками программирования, таких как Delphi, Perl, Python и Ruby.
- SQL команды писать БОЛЬШИМИ буквами для удобочитаемости. Помните всегда, что после вас могут читать код и другие люди, а скорее всего вы сами через N количество времени.
- Называть поля с начала существительное, а потом действие. Например: city_status, user_login, user_name.
- Стараться избегать слов резервных в разных языках которые могут вызывать проблемы в языках SQL, PHP или Perl, типа (name, count, link). Например: link можно использовать в MS SQL, но в MySQL зарезервировано.
Данный материал является короткой справкой для повседневной работы и не претендует на супер мега авторитетный источник, коим является первоисточник SQL запросов той или иной базы данных.
- Перевод
- Tutorial
Надо “ SELECT * WHERE a=b FROM c ” или “ SELECT WHERE a=b FROM c ON * ” ?
Если вы похожи на меня, то согласитесь: SQL - это одна из тех штук, которые на первый взгляд кажутся легкими (читается как будто по-английски!), но почему-то приходится гуглить каждый простой запрос, чтобы найти правильный синтаксис.
А потом начинаются джойны, агрегирование, подзапросы, и получается совсем белиберда. Вроде такой:
SELECT members.firstname || " " || members.lastname AS "Full Name" FROM borrowings INNER JOIN members ON members.memberid=borrowings.memberid INNER JOIN books ON books.bookid=borrowings.bookid WHERE borrowings.bookid IN (SELECT bookid FROM books WHERE stock>(SELECT avg(stock) FROM books)) GROUP BY members.firstname, members.lastname;
Буэ! Такое спугнет любого новичка, или даже разработчика среднего уровня, если он видит SQL впервые. Но не все так плохо.
Легко запомнить то, что интуитивно понятно, и с помощью этого руководства я надеюсь снизить порог входа в SQL для новичков, а уже опытным предложить по-новому взглянуть на SQL.
Не смотря на то, что синтаксис SQL почти не отличается в разных базах данных, в этой статье для запросов используется PostgreSQL. Некоторые примеры будут работать в MySQL и других базах.
1. Три волшебных слова
В SQL много ключевых слов, но SELECT , FROM и WHERE присутствуют практически в каждом запросе. Чуть позже вы поймете, что эти три слова представляют собой самые фундаментальные аспекты построения запросов к базе, а другие, более сложные запросы, являются всего лишь надстройками над ними.
2. Наша база
Давайте взглянем на базу данных, которую мы будем использовать в качестве примера в этой статье:


У нас есть книжная библиотека и люди. Также есть специальная таблица для учета выданных книг.
- В таблице "books" хранится информация о заголовке, авторе, дате публикации и наличии книги. Все просто.
- В таблице “members” - имена и фамилии всех записавшихся в библиотеку людей.
- В таблице “borrowings” хранится информация о взятых из библиотеки книгах. Колонка bookid относится к идентификатору взятой книги в таблице “books”, а колонка memberid относится к соответствующему человеку из таблицы “members”. У нас также есть дата выдачи и дата, когда книгу нужно вернуть.
3. Простой запрос
Давайте начнем с простого запроса: нам нужны имена и идентификаторы (id) всех книг, написанных автором “Dan Brown”
Запрос будет таким:
SELECT bookid AS "id", title FROM books WHERE author="Dan Brown";
А результат таким:
| id | title |
|---|---|
| 2 | The Lost Symbol |
| 4 | Inferno |
Довольно просто. Давайте разберем запрос чтобы понять, что происходит.
3.1 FROM - откуда берем данные
Сейчас это может показаться очевидным, но FROM будет очень важен позже, когда мы перейдем к соединениям и подзапросам.
FROM указывает на таблицу, по которой нужно делать запрос. Это может быть уже существующая таблица (как в примере выше), или таблица, создаваемая на лету через соединения или подзапросы.
3.2 WHERE - какие данные показываем
WHERE просто-напросто ведет себя как фильтр строк , которые мы хотим вывести. В нашем случае мы хотим видеть только те строки, где значение в колонке author - это “Dan Brown”.
3.3 SELECT - как показываем данные
Теперь, когда у нас есть все нужные нам колонки из нужной нам таблицы, нужно решить, как именно показывать эти данные. В нашем случае нужны только названия и идентификаторы книг, так что именно это мы и выберем с помощью SELECT . Заодно можно переименовать колонку используя AS .
Весь запрос можно визуализировать с помощью простой диаграммы:

4. Соединения (джойны)
Теперь мы хотим увидеть названия (не обязательно уникальные) всех книг Дэна Брауна, которые были взяты из библиотеки, и когда эти книги нужно вернуть:
SELECT books.title AS "Title", borrowings.returndate AS "Return Date" FROM borrowings JOIN books ON borrowings.bookid=books.bookid WHERE books.author="Dan Brown";
Результат:
| Title | Return Date |
|---|---|
| The Lost Symbol | 2016-03-23 00:00:00 |
| Inferno | 2016-04-13 00:00:00 |
| The Lost Symbol | 2016-04-19 00:00:00 |
По большей части запрос похож на предыдущий за исключением секции FROM . Это означает, что мы запрашиваем данные из другой таблицы . Мы не обращаемся ни к таблице “books”, ни к таблице “borrowings”. Вместо этого мы обращаемся к новой таблице , которая создалась соединением этих двух таблиц.
borrowings JOIN books ON borrowings.bookid=books.bookid - это, считай, новая таблица, которая была сформирована комбинированием всех записей из таблиц "books" и "borrowings", в которых значения bookid совпадают. Результатом такого слияния будет:

А потом мы делаем запрос к этой таблице так же, как в примере выше. Это значит, что при соединении таблиц нужно заботиться только о том, как провести это соединение. А потом запрос становится таким же понятным, как в случае с «простым запросом» из пункта 3.
Давайте попробуем чуть более сложное соединение с двумя таблицами.
Теперь мы хотим получить имена и фамилии людей, которые взяли из библиотеки книги автора “Dan Brown”.
На этот раз давайте пойдем снизу вверх:
Шаг Step 1 - откуда берем данные? Чтобы получить нужный нам результат, нужно соединить таблицы “member” и “books” с таблицей “borrowings”. Секция JOIN будет выглядеть так:
borrowings JOIN books ON borrowings.bookid=books.bookid JOIN members ON members.memberid=borrowings.memberid
Результат соединения можно увидеть по ссылке .
Шаг 2 - какие данные показываем? Нас интересуют только те данные, где автор книги - “Dan Brown”
WHERE books.author="Dan Brown"
Шаг 3 - как показываем данные? Теперь, когда данные получены, нужно просто вывести имя и фамилию тех, кто взял книги:
SELECT members.firstname AS "First Name", members.lastname AS "Last Name"
Супер! Осталось лишь объединить три составные части и сделать нужный нам запрос:
SELECT members.firstname AS "First Name", members.lastname AS "Last Name" FROM borrowings JOIN books ON borrowings.bookid=books.bookid JOIN members ON members.memberid=borrowings.memberid WHERE books.author="Dan Brown";
Что даст нам:
| First Name | Last Name |
|---|---|
| Mike | Willis |
| Ellen | Horton |
| Ellen | Horton |
Отлично! Но имена повторяются (они не уникальны). Мы скоро это исправим.
5. Агрегирование
Грубо говоря, агрегирования нужны для конвертации нескольких строк в одну . При этом, во время агрегирования для разных колонок используется разная логика.
Давайте продолжим наш пример, в котором появляются повторяющиеся имена. Видно, что Ellen Horton взяла больше одной книги, но это не самый лучший способ показать эту информацию. Можно сделать другой запрос:
SELECT members.firstname AS "First Name", members.lastname AS "Last Name", count(*) AS "Number of books borrowed" FROM borrowings JOIN books ON borrowings.bookid=books.bookid JOIN members ON members.memberid=borrowings.memberid WHERE books.author="Dan Brown" GROUP BY members.firstname, members.lastname;
Что даст нам нужный результат:
| First Name | Last Name | Number of books borrowed |
|---|---|---|
| Mike | Willis | 1 |
| Ellen | Horton | 2 |
Почти все агрегации идут вместе с выражением GROUP BY . Эта штука превращает таблицу, которую можно было бы получить запросом, в группы таблиц. Каждая группа соответствует уникальному значению (или группе значений) колонки, которую мы указали в GROUP BY . В нашем примере мы конвертируем результат из прошлого упражнения в группу строк. Мы также проводим агрегирование с count , которая конвертирует несколько строк в целое значение (в нашем случае это количество строк). Потом это значение приписывается каждой группе.
Каждая строка в результате представляет собой результат агрегирования каждой группы.
Можно прийти к логическому выводу, что все поля в результате должны быть или указаны в GROUP BY , или по ним должно производиться агрегирование. Потому что все другие поля могут отличаться друг от друга в разных строках, и если выбирать их SELECT "ом, то непонятно, какие из возможных значений нужно брать.
В примере выше функция count обрабатывала все строки (так как мы считали количество строк). Другие функции вроде sum или max обрабатывают только указанные строки. Например, если мы хотим узнать количество книг, написанных каждым автором, то нужен такой запрос:
SELECT author, sum(stock) FROM books GROUP BY author;
Результат:
| author | sum |
|---|---|
| Robin Sharma | 4 |
| Dan Brown | 6 |
| John Green | 3 |
| Amish Tripathi | 2 |
Здесь функция sum обрабатывает только колонку stock и считает сумму всех значений в каждой группе.
6. Подзапросы

Подзапросы это обычные SQL-запросы, встроенные в более крупные запросы. Они делятся на три вида по типу возвращаемого результата.
6.1 Двумерная таблица
Есть запросы, которые возвращают несколько колонок. Хороший пример это запрос из прошлого упражнения по агрегированию. Будучи подзапросом, он просто вернет еще одну таблицу, по которой можно делать новые запросы. Продолжая предыдущее упражнение, если мы хотим узнать количество книг, написанных автором “Robin Sharma”, то один из возможных способов - использовать подзапросы:
SELECT * FROM (SELECT author, sum(stock) FROM books GROUP BY author) AS results WHERE author="Robin Sharma";
Результат:
Можно записать как: ["Robin Sharma", "Dan Brown"]
2. Теперь используем этот результат в новом запросе:
SELECT title, bookid FROM books WHERE author IN (SELECT author FROM (SELECT author, sum(stock) FROM books GROUP BY author) AS results WHERE sum > 3);
Результат:
| title | bookid |
|---|---|
| The Lost Symbol | 2 |
| Who Will Cry When You Die? | 3 |
| Inferno | 4 |
Это то же самое, что:
SELECT title, bookid FROM books WHERE author IN ("Robin Sharma", "Dan Brown");
6.3 Отдельные значения
Бывают запросы, результатом которых являются всего одна строка и одна колонка. К ним можно относиться как к константным значениям, и их можно использовать везде, где используются значения, например, в операторах сравнения. Их также можно использовать в качестве двумерных таблиц или массивов, состоящих из одного элемента.
Давайте, к примеру, получим информацию о всех книгах, количество которых в библиотеке превышает среднее значение в данный момент.
Среднее количество можно получить таким образом:
select avg(stock) from books;
Что дает нам:
7. Операции записи
Большинство операций записи в базе данных довольно просты, если сравнивать с более сложными операциями чтения.
7.1 Update
Синтаксис запроса UPDATE семантически совпадает с запросом на чтение. Единственное отличие в том, что вместо выбора колонок SELECT "ом, мы задаем знаения SET "ом.
Если все книги Дэна Брауна потерялись, то нужно обнулить значение количества. Запрос для этого будет таким:
UPDATE books SET stock=0 WHERE author="Dan Brown";
WHERE делает то же самое, что раньше: выбирает строки. Вместо SELECT , который использовался при чтении, мы теперь используем SET . Однако, теперь нужно указать не только имя колонки, но и новое значение для этой колонки в выбранных строках.
7.2 Delete
Запрос DELETE это просто запрос SELECT или UPDATE без названий колонок. Серьезно. Как и в случае с SELECT и UPDATE , блок WHERE остается таким же: он выбирает строки, которые нужно удалить. Операция удаления уничтожает всю строку, так что не имеет смысла указывать отдельные колонки. Так что, если мы решим не обнулять количество книг Дэна Брауна, а вообще удалить все записи, то можно сделать такой запрос:
DELETE FROM books WHERE author="Dan Brown";
7.3 Insert
Пожалуй, единственное, что отличается от других типов запросов, это INSERT . Формат такой:
INSERT INTO x (a,b,c) VALUES (x, y, z);
Где a , b , c это названия колонок, а x , y и z это значения, которые нужно вставить в эти колонки, в том же порядке. Вот, в принципе, и все.
Взглянем на конкретный пример. Вот запрос с INSERT , который заполняет всю таблицу "books":
INSERT INTO books (bookid,title,author,published,stock) VALUES (1,"Scion of Ikshvaku","Amish Tripathi","06-22-2015",2), (2,"The Lost Symbol","Dan Brown","07-22-2010",3), (3,"Who Will Cry When You Die?","Robin Sharma","06-15-2006",4), (4,"Inferno","Dan Brown","05-05-2014",3), (5,"The Fault in our Stars","John Green","01-03-2015",3);
8. Проверка
Мы подошли к концу, предлагаю небольшой тест. Посмотрите на тот запрос в самом начале статьи. Можете разобраться в нем? Попробуйте разбить его на секции SELECT , FROM , WHERE , GROUP BY , и рассмотреть отдельные компоненты подзапросов.
Вот он в более удобном для чтения виде:
SELECT members.firstname || " " || members.lastname AS "Full Name" FROM borrowings INNER JOIN members ON members.memberid=borrowings.memberid INNER JOIN books ON books.bookid=borrowings.bookid WHERE borrowings.bookid IN (SELECT bookid FROM books WHERE stock> (SELECT avg(stock) FROM books)) GROUP BY members.firstname, members.lastname;
Этот запрос выводит список людей, которые взяли из библиотеки книгу, у которой общее количество выше среднего значения.
Результат:
| Full Name |
|---|
| Lida Tyler |
Надеюсь, вам удалось разобраться без проблем. Но если нет, то буду рад вашим комментариям и отзывам, чтобы я мог улучшить этот пост.
Теги: Добавить метки
Табличными выражениями называются подзапросы, которые используются там, где ожидается наличие таблицы. Существует два типа табличных выражений:
производные таблицы;
обобщенные табличные выражения.
Эти две формы табличных выражений рассматриваются в следующих подразделах.
Производные таблицы
Производная таблица (derived table) - это табличное выражение, входящее в предложение FROM запроса. Производные таблицы можно применять в тех случаях, когда использование псевдонимов столбцов не представляется возможным, поскольку транслятор SQL обрабатывает другое предложение до того, как псевдоним станет известным. В примере ниже показана попытка использовать псевдоним столбца в ситуации, когда другое предложение обрабатывается до того, как станет известным псевдоним:
USE SampleDb; SELECT MONTH(EnterDate) as enter_month FROM Works_on GROUP BY enter_month;
Попытка выполнить этот запрос выдаст следующее сообщение об ошибке:
Msg 207, Level 16, State 1, Line 5 Invalid column name "enter_month". (Сообщение 207: уровень 16, состояние 1, строка 5 Недопустимое имя столбца enter_month)
Причиной ошибки является то обстоятельство, что предложение GROUP BY обрабатывается до обработки соответствующего списка инструкции SELECT, и при обработке этой группы псевдоним столбца enter_month неизвестен.
Эту проблему можно решить, используя производную таблицу, содержащую предшествующий запрос (без предложения GROUP BY), поскольку предложение FROM исполняется перед предложением GROUP BY:
USE SampleDb; SELECT enter_month FROM (SELECT MONTH(EnterDate) as enter_month FROM Works_on) AS m GROUP BY enter_month;
Результат выполнения этого запроса будет таким:
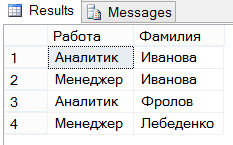
Обычно табличное выражение можно разместить в любом месте инструкции SELECT, где может появиться имя таблицы. (Результатом табличного выражения всегда является таблица или, в особых случаях, выражение.) В примере ниже показывается использование табличного выражения в списке выбора инструкции SELECT:
Результат выполнения этого запроса:
Обобщенные табличные выражения
Обобщенным табличным выражением (OTB) (Common Table Expression - сокращенно CTE) называется именованное табличное выражение, поддерживаемое языком Transact-SQL. Обобщенные табличные выражения используются в следующих двух типах запросов:
нерекурсивных;
рекурсивных.
Эти два типа запросов рассматриваются в следующих далее разделах.
OTB и нерекурсивные запросы
Нерекурсивную форму OTB можно использовать в качестве альтернативы производным таблицам и представлениям. Обычно OTB определяется посредством предложения WITH и дополнительного запроса, который ссылается на имя, используемое в предложении WITH. В языке Transact-SQL значение ключевого слова WITH неоднозначно. Чтобы избежать неопределенности, инструкцию, предшествующую оператору WITH, следует завершать точкой с запятой.
USE AdventureWorks2012; SELECT SalesOrderID FROM Sales.SalesOrderHeader WHERE TotalDue > (SELECT AVG(TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR(OrderDate) = "2005") AND Freight > (SELECT AVG(TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR(OrderDate) = "2005")/2.5;
Запрос в этом примере выбирает заказы, чьи общие суммы налогов (TotalDue) большие, чем среднее значение по всем налогам, и плата за перевозку (Freight) которых больше чем 40% среднего значения налогов. Основным свойством этого запроса является его объемистость, поскольку вложенный запрос требуется писать дважды. Одним из возможных способов уменьшить объем конструкции запроса будет создать представление, содержащее вложенный запрос. Но это решение несколько сложно, поскольку требует создания представления, а потом его удаления после окончания выполнения запроса. Лучшим подходом будет создать OTB. В примере ниже показывается использование нерекурсивного OTB, которое сокращает определение запроса, приведенного выше:
USE AdventureWorks2012; WITH price_calc(year_2005) AS (SELECT AVG(TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR(OrderDate) = "2005") SELECT SalesOrderID FROM Sales.SalesOrderHeader WHERE TotalDue > (SELECT year_2005 FROM price_calc) AND Freight > (SELECT year_2005 FROM price_calc)/2.5;
Синтаксис предложения WITH в нерекурсивных запросах имеет следующий вид:
Параметр cte_name представляет имя OTB, которое определяет результирующую таблицу, а параметр column_list - список столбцов табличного выражения. (В примере выше OTB называется price_calc и имеет один столбец - year_2005.) Параметр inner_query представляет инструкцию SELECT, которая определяет результирующий набор соответствующего табличного выражения. После этого определенное табличное выражение можно использовать во внешнем запросе outer_query. (Внешний запрос в примере выше использует OTB price_calc и ее столбец year_2005, чтобы упростить употребляющийся дважды вложенный запрос.)
OTB и рекурсивные запросы
В этом разделе представляется материал повышенной сложности. Поэтому при первом его чтении рекомендуется его пропустить и вернуться к нему позже. Посредством OTB можно реализовывать рекурсии, поскольку OTB могут содержать ссылки на самих себя. Основной синтаксис OTB для рекурсивного запроса выглядит таким образом:
Параметры cte_name и column_list имеют такое же значение, как и в OTB для нерекурсивных запросов. Тело предложения WITH состоит из двух запросов, объединенных оператором UNION ALL . Первый запрос вызывается только один раз, и он начинает накапливать результат рекурсии. Первый операнд оператора UNION ALL не ссылается на OTB. Этот запрос называется опорным запросом или источником.
Второй запрос содержит ссылку на OTB и представляет ее рекурсивную часть. Вследствие этого он называется рекурсивным членом. В первом вызове рекурсивной части ссылка на OTB представляет результат опорного запроса. Рекурсивный член использует результат первого вызова запроса. После этого система снова вызывает рекурсивную часть. Вызов рекурсивного члена прекращается, когда предыдущий его вызов возвращает пустой результирующий набор.
Оператор UNION ALL соединяет накопившиеся на данный момент строки, а также дополнительные строки, добавленные текущим вызовом рекурсивного члена. (Наличие оператора UNION ALL означает, что повторяющиеся строки не будут удалены из результата.)
Наконец, параметр outer_query определяет внешний запрос, который использует OTB для получения всех вызовов объединения обеих членов.
Для демонстрации рекурсивной формы OTB мы используем таблицу Airplane, определенную и заполненную кодом, показанным в примере ниже:
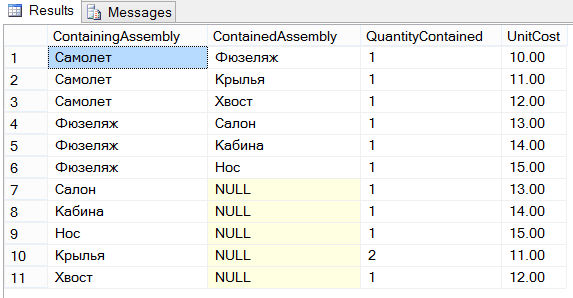
USE SampleDb; CREATE TABLE Airplane (ContainingAssembly VARCHAR(10), ContainedAssembly VARCHAR(10), QuantityContained INT, UnitCost DECIMAL (6,2)); INSERT INTO Airplane VALUES ("Самолет", "Фюзеляж",1, 10); INSERT INTO Airplane VALUES ("Самолет", "Крылья", 1, 11); INSERT INTO Airplane VALUES ("Самолет", "Хвост",1, 12); INSERT INTO Airplane VALUES ("Фюзеляж", "Салон", 1, 13); INSERT INTO Airplane VALUES ("Фюзеляж", "Кабина", 1, 14); INSERT INTO Airplane VALUES ("Фюзеляж", "Нос",1, 15); INSERT INTO Airplane VALUES ("Салон", NULL, 1,13); INSERT INTO Airplane VALUES ("Кабина", NULL, 1, 14); INSERT INTO Airplane VALUES ("Нос", NULL, 1, 15); INSERT INTO Airplane VALUES ("Крылья", NULL,2, 11); INSERT INTO Airplane VALUES ("Хвост", NULL, 1, 12);
Таблица Airplane состоит из четырех столбцов. Столбец ContainingAssembly определяет сборку, а столбец ContainedAssembly - части (одна за другой), которые составляют соответствующую сборку. На рисунке ниже приведена графическая иллюстрация возможного вида самолета и его составляющих частей:

Таблица Airplane состоит из следующих 11 строк:
В примере ниже показано применение предложения WITH для определения запроса, который вычисляет общую стоимость каждой сборки:
USE SampleDb; WITH list_of_parts(assembly1, quantity, cost) AS (SELECT ContainingAssembly, QuantityContained, UnitCost FROM Airplane WHERE ContainedAssembly IS NULL UNION ALL SELECT a.ContainingAssembly, a.QuantityContained, CAST(l.quantity * l.cost AS DECIMAL(6,2)) FROM list_of_parts l, Airplane a WHERE l.assembly1 = a.ContainedAssembly) SELECT assembly1 "Деталь", quantity "Кол-во", cost "Цена" FROM list_of_parts;
Предложение WITH определяет список OTB с именем list_of_parts, состоящий из трех столбцов: assembly1, quantity и cost. Первая инструкция SELECT в примере вызывается только один раз, чтобы сохранить результаты первого шага процесса рекурсии. Инструкция SELECT в последней строке примера отображает следующий результат.



