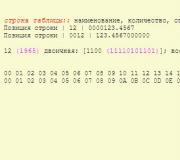
Semantic core for an advertising company. How to prepare a semantic core for contextual advertising? Distribution of requests across pages
In each topic there are dozens of basic queries, for example, “bulldozer”, “tractor” and so on. Your advertising campaign will consist of phrases with basic queries (“buy a bulldozer”, “sell a tractor”).
How to collect basic queries
- Go to at least 30 competitors’ websites: write down all the words and phrases from your topic.
- Research the needs of potential clients. Think about what your customers typically search for online. And why not show your ad based on their popular queries?
- Collect synonyms for basic queries. For example, a down jacket is warm winter clothing.
- Collect jargon and slang expressions. To do this, study the specialized forums where your audience communicates.
- Collect translits. For example, together with “buy a Bosch washing machine” they search for “buy a Bosch washing machine”.
- Collect queries similar to yours from the right column of Wordstat (https://wordstat.yandex.ru/).
- Collect tips from Yandex and Google. When you enter a query into the search bar, you will see suggestions or similar queries.
- Collect queries for which your competitors advertise using the special advse.ru service.
How to collect advertising requests
- Manually using Wordstat.
- In automatic mode using special programs, for example, KeyCollector, SlovoYob or Magadan.
How to generate advertising requests
Let's take the topic of airline tickets. Let’s say you have 5 basic queries (“charter”, “vacation”, “air tickets”, “tour”, “fly away”) and a hundred cities in which you want to advertise, that is, you need to multiply 5 queries by 100 cities. For multiplication, it is most convenient to use a special service for generating such queries - py7.ru/tools/text/.
How to clean the semantic core
To avoid wasting money on non-targeted queries, collect a list of negative keywords or junk queries for which your ads will not appear in Yandex.Direct. You can easily set negative keywords, for example, in the special KeyCollector program, thereby increasing CTR.
It’s been a long time since we talked about the specialized events we attend. So, let’s correct ourselves and share information from the last two Internet conferences in St. Petersburg - CPA Life and “Find Your Traffic”.
Ideally the process works like this:
2) Collect semantics from marker queries from anywhere: from Wordstat to search tips.
It doesn't matter what you use when collecting. All services have different quality, but the principle is the same: at the input you enter a marker request, and the program produces extensions that contain the phrase.
The task that has to be solved manually is to determine those very markers (bases). Each one reflects its own demand, keywords, extensions and reach. To do this, you need at least minimal familiarity with the assortment.
When it comes to brand semantics, it’s clear how to look for markers. The brand, as a rule, has Russian or English spelling, series and model names. It is important to take into account all erroneous and synonymous spellings. Other cases with examples will be discussed later in the article.
3) You receive tens or hundreds of thousands of requests, clean them of “garbage” and get two groups: the necessary requests and negative keywords.
Let's consider brand semantics using the example of the online store of tourist equipment and goods “My Planet”.
The store has about 70-80 brands, one of them is Stanley. These include tools, furniture, dishes, and much more. There is no point in collecting all extensions from the word stanley, otherwise there will be a lot of “garbage”. Therefore, we leave requests of 2-3 words:

Most often, it is better to take three-word or two-word ones; in some specific cases, one-word ones are acceptable.
Thermoses are the most popular product, they have 3 spellings of the brand name - stanley, stanley, stanley - and there are markers for the series: stanley mountain, stanley classic.
The more bases, the wider the coverage. We have 70 types of goods, each with 20-50 bases. The total volume of the “tail” is several hundred thousand advanced queries. They can intersect, but partially: as a rule, the percentage of intersection is low.
As a result, you get 100% coverage, but spend a lot of time processing the data. To speed up the process, they often use the method of multiplying queries in a multiplying script.
For a branded semantic core, this method speeds up the work. But what do you do when you offer services in a highly competitive market?
Semantics for complex services
In this situation, there are more unobvious queries that can only be identified through in-depth analysis.
An example is a “diesel” car service, a client of the MOAB agency.
Initial data: the previous contractor multiplied standard service names by transactional words such as “prices”, “buy” and others. As a result, the basics were “injector repair”, “injection pump repair” and others like them.
This approach gives the most banal formulations. An exact copy of the key, rearrangement of words, different cases and word forms are not an option for creativity. Everyone - both contractors and clients - thinks alike, uses the same type of wording and transactional words. Requests “from the lantern” quickly overheat.
The result is a loss of coverage and, as a result, insufficient load on the service, since there are no impressions for non-obvious queries. They cannot be obtained by simple multiplication.
The paradox of the situation is that there is little traffic (up to 10 visitors per day), but the auction is terrible (up to 40 rubles per click). Even a service with a huge material base, low cost and a large flow of clients is almost impossible to recoup the rates for a specific key.
Based on the results of the analysis, we found additional bases (frequency in Moscow is indicated):

Most of them were a revelation for the customer himself: he did not suspect that potential clients could formulate a search THIS way, although he had been working in this field for a long time.
These requests are far from obvious to competitors, and therefore not overheated. The forecast daily traffic is about 400-500 users, in total for all systems. The average price for them is much lower than for phrases like “injector repair.”
How to systematize if the markers are not tied to the brand and contain vague demand? What the target audience is looking for cannot be invented spontaneously or heard from the customer.
One problem generates an unknown large array of requests: diesel smokes black, gray, white, does not work, knocks, rattles, etc. Your task is to divide this array into clusters in order to differentiate between a finite number of needs.
Demand Variables
In the case of a brand, the “anchor” of demand is the name itself. Stanley products cannot be called anything else; in any case, it is something with the word “Stanley”.
For a complex service, demand is broken down into several components (variables). It is impossible to formulate the problem without one of them:
- There is a problem with the unit - the user knows or assumes what is broken (injectors, injection pump, plunger). And then the flight of fantasies begins - “the injector is knocking,” “the injector is rattling,” “the injector is smoking,” etc.
- The problem with the car is that he doesn’t know what’s broken and doesn’t want to find out, he just writes the name of the brand of his car (Scania, Kamaz, Man). In our case, gasoline cars are not our profile; we select only those that run on diesel;
- Through fuel - a person does not indicate a car or unit, but indicates the type of fuel - “diesel engine”, “diesel”, “diesel car repair”;
- Through the manifestation of the problem (“smoke”, “does not run”). For example, black smoke is a typical diesel problem; there is no need to specify whether it is gasoline or diesel;
- Through the error code on the auto scanner (“error 1235”, “error 0489”).
With a high probability, a person whose diesel engine has broken down will use at least one of the values of these variables in the query. This is the “anchor” around which demand for an issue revolves.
Recommendation: To break down queries into variables and select their values, you need to imagine how your potential audience talks about problems. To do this, it is useful to study competitors’ websites, thematic forums, communities, etc.
How is this different from multiplication?
Imagine there is a mountain, inside of which there are gold bars that you need to get. The standard way is to dig a mine in this mountain and collect the gold that comes along the exploration path.
Another option is that you tear down the mountain with an excavator and take it to the mining and processing plant. It is more labor-intensive and requires more competencies, but from the entire mass of rocks you will collect all the gold.
By analogy with this, we take all the demand for the query “diesel”, “diesel” and work through all the expansions in depth in Wordstat. Then we collect search tips for each. Based on the resulting array, we break down the frequency, remove duplicates and get the total volume of requests.
Let's say we get 100 thousand. What to do next with them? We select the necessary phrases.
To do this, we drive each array into “Group Analysis” in Key Collector. We use a frequency dictionary of queries. In it you need to group by phrases and fill in the keywords in the tab.
What we get:

These are requests that the client will not tell you about. Almost no one does this, so competition for such semantics is minimal.
At this stage, there is no need to clear the array of negative keywords, etc. You just need to look through the frequency dictionary and identify two-word words that clearly indicate auto repair.
What are the advantages? Frequently used groups of requests are tied to the most popular problems. The program sorts groups by the number of words they contain. You look through all the results and identify groups that fit your problem.
You get everything that can be collected in this topic. At the same time, it’s normal if you initially have 100 thousand queries with the word “diesel” and only 10 thousand after analysis.
You do similar work with all variable values.
Semantics for exact demand
For the YapiMotors auto repair center, the MOAB agency compiled one of the largest semantic plans in its history. Client specifics: he needs to provide accurate traffic.
The customer clearly outlined the initial conditions: there is an exact list of works (300 pieces) that he performs, and a list of brands (70 pieces) with which he works.

At the first stage, we looked for all kinds of titles from the list of works:
- Brake repair - repair of the brake system, replacement of the brake system, brakes do not work, etc.
- Engine repair - internal combustion engine repair, internal combustion engine replacement, engine repair, etc.
Japanese names are complex and often misspelled. As a result, 70 given brands/models turned into 270 lines of different spellings in Latin and Cyrillic.
The market is large, so the company did not lay claim to the whole market. It’s logical: one car service cannot serve the whole of Moscow. His goal is a small part of this demand, but as hot as possible, and for minimal money. Therefore, we have identified requests that already have an urgent need.
If a user writes “black smoke diesel” in a search, he can drive a smoking car for another week before it completely stops. And the “repair running price” can be converted right now.
We multiply 450 works by 270 models and get a list of markers from which we take the frequency.
About 5 thousand bases showed a non-zero frequency and a “tail” of extensions of 50 thousand. Unlike the diesel core, which contains a lot of “garbage,” this contains a minimal number of negative keywords, and almost all queries are targeted.
Semantics for feeds
Why collect it?
Semantics for feeds ensures a reliable negative file and clean traffic.
A standard list of negative keywords is not enough. At best, they close 30-40% of real negative keywords. Each topic also has queries that contain characteristic words and make the query itself untargeted and irrelevant to you. Therefore, you need to collect negative keywords for feeds based on real queries.
An example is requests for Bosch auto parts. This is an array of several hundred thousand. From it we identified those that contain numbers - these are product requests, there were 20-30 thousand of them. We compiled a frequency dictionary from them to find groups with irrelevant demand. It is important to take real phrases for a specific brand.
This gives you a more accurate negative keyword file, based on which you can block untargeted impressions. As a result, in Russia the average price per click was 7-10 rubles, and the price of an application was 60-70 rubles. We achieved high conversions because we only attracted traffic that was close to a purchase.
Pitfalls of feed advertising
These are “fake” articles and product names.
Let's say you have 10 thousand auto parts. During the process, it is important to check whether there are double meanings among the articles. It can mean both a product and GOST, instructions that are not related to your topic. Or a product from a completely different area.
How can I check this? Take a list of articles and break down the frequency of them. You also manually identify articles with double meanings. Using them, you clarify the semantics - add the brand name or clarifying words to exclude impressions based on non-target coverage.
Is it enough to add an article number to the ad or is it necessary« %item + %buy (or other transaction word)»
The second option does not provide additional traffic, but you can directly control the position of the ad not only for the item request, but also for the “%item + %buy” request through the bidder connection.
This was the case until recently. On very large product feeds, there weren't enough points to load many keywords, so I had to give it up.
Conclusion: there is no point in propagating semantics across feeds. It is enough to add one broadest article name or product index.
What to do with the “low impressions” status
First of all, look not at what happened and how, but whether the traffic has changed. If not, there is no need to worry. This means that these ads did not generate traffic.
If it has decreased noticeably - not plus or minus 10% error, but more - then you need to figure it out: most likely, errors in clustering by campaign, selection of semantics. Although, in relation to feeds, this is unlikely.
SEO or context - which is better?
How to plan marketing
In modern conditions, you need to pay off on any channels. There should be no fundamental ideological difference between them.
What does this look like during normal planning? First, we decide on a niche, create an HTML layout for the site, an engine, and then begin to create semantics. At the same time, it is important that the structure depends not on the catalog or on your vision of the sections, but on semantics. Place what people search for most often in prominent places.
After we have collected the semantics and decided on the structure, we create and fill the site with content.
Recommendation: context first, SEO second. You can clean and group the semantics and launch the context so that the business makes money. Maybe not very large sums (200-400 thousand rubles), but quickly. In 2-4 months you can build a sales chain to reinvest this money for SEO.
What is the synergy between the processes? The results obtained from clustering in context can be used for clustering in SEO. Not everything will be the same, but a lot can be taken from the context for SEO.
Conclusion: SEO and context will soon become almost indistinguishable, and the savings from their synergy are growing.
Resume
1) At the initial stage, it is not the collection itself that is more important (everything is automated), but the search for bases;
2) The bases can be simple and clean (hoverboard) or trashy and dirty (diesel);
3) Check whether you have collected all the synonyms and reformulations: Wordstat and the “similar queries” block in SERP can help;
By collecting a complete semantic core, you will always gain a competitive advantage due to greater audience coverage and, consequently, more orders, purchases, and leads.
In this publication, I tried to outline the entire process of initial collection of key phrases - services, programs, principles of searching and working with the received data. We also describe a method for compiling a basic list of negative words (based on the collected semantic core), which will exclude 95% of all non-targeted impressions!
The collection method is universal and is suitable not only for an advertising campaign in Yandex Direct, but also for the formation of full-fledged semantics for search engine optimization (SEO). The only difference is that when collecting the semantic core for contextual advertising, they usually do not go so deep into low-frequency phrases. And the methods of filtering and compiling a list of negative words are the same.
1st step. Collection of marker words for parsing in Yandex WordStat
I am writing an article based on one of my latest works - ski equipment, skiing techniques, etc.
To search for marker words we use:
- The site itself, its sections with goods or services;
- Competitors' websites. We analyze externally by sections and services, and with the help of services - megaindex, key.so and the like;
- Synonym services;
- Right and left columns in Yandex WordStat, the block “they are searching for this phrase” under the search results.
Marker words/phrases - these are just directions for further study, “digging” deeper, so to speak. If the phrase “selection of skis” has already been added to the list, then there is no need to add the nested “selection of alpine skis”. All nested phrases will be found after parsing in Key Collector.
The main task is to collect a maximum of marker words (directions), check synonyms, slang words and form a general list from which we will “dig” further.
It is convenient to form in a visual form, for example in and it looks like this:
In the screenshot, only one branch is open so that the image is of a reasonable size.
A huge benefit from such visualization, for me personally, is that if you open all directions, you immediately understand that multitasking needs to be turned off and work with only one section, and not with all of them at once. Otherwise, problems sometimes arise with the sequence of actions.
Important: To quickly process and save keywords in Wordstat, try the free browser extension - Yandex Wordstat Assistant. Using it, you can quickly transfer the necessary key phrases to the semantic core.

A table of questions is useful for large projects. I don’t know what to call it professionally, but through such questions, you can significantly expand the semantic core, find new intentions, the existence of which you didn’t even suspect at the beginning.
The collected phrases are multiplied and then checked for frequency in Wordstat. Frequent phrases are added for further study.
Intent- this is what the user enters a query into the search engine for. You can call it "pain". A set of key phrases can be combined by one intent, that is, caused by one motive, although the spelling and set of words may differ.
Do I need paid services and programs to collect the semantic core?
I use the Key Collector program and carry out all the actions described below in it. If it is not there, then it is unlikely that you will be able to assemble a complete kernel. You can, of course, manually “walk” through Wordstat, the Wordstat Assistant extension will greatly help with this, and take more phrases from free databases, like Bukvarix. But this will all be a small part of what can really be collected.
In some situations this is enough, although I am a supporter of creating the most complete semantics, especially if the subject of the site is small and there is little topical traffic. In such cases, it is advisable to collect everything to cover your niche as much as possible.
If you have one website, then it will be more profitable to order the service of collecting the semantic core outsourced. Pay 3-5 thousand rubles, but get a full core with a maximum of key phrases, without having to buy software, pay for services, and so on.
For Yandex Direct, I rarely collect key phrases in Key Collector, only when there are large advertising campaigns, many directions... For small and medium niches, Wordstat and working out synonyms are enough.
Most often, directists have little understanding of the object of advertising, and if you are advertising your product/service, then you will a priori select the right key phrases and the best ads that will touch the necessary chords of your target audience. You just need to understand some of the subtleties and sequences of work. This is what I will try to describe in detail in this series of articles.
2nd step. Collection of key phrases in Yandex WordStat
We pass the collected marker words through the left column of Wordstat in Key Collector.
To save time, large directions can be divided into a herringbone pattern like this:

WordStat does not show more than seven words, so in such queries there is only a seven-word template.
Wordstat allows you to view only 2000 nested phrases. It's 40 pages. If you scroll to page 40 for the phrase “skiing,” you will see that the list ends at a phrase with a frequency of 62 impressions. For a complete semantic core, this will not be enough, since further down there may still be several hundred low-frequency phrases that can bring additional traffic.
The herringbone method will reduce time and avoid repeated iterations of parsing the obtained key phrases after the first collection. Key Collector will take all phrases from Wordstat for a given marker word, up to a frequency of 1, not limited to the standard two thousand.
Collection of key phrases of competitors and database
We use the service megaindex, key.so or serpstat.com. It is advisable to work with 5-10 direct competitors. From free databases, I can recommend .
Observation: if marker words, synonyms, and slang expressions are initially well developed, then Wordstat gives 70-80% of search queries, and the rest comes from competitors and Bukvariks.
These phrases should not be mixed with everyone, but it is better to add them to a separate group in the key collector.
Please note that when adding, check the box “Do not add a phrase if it is in any other group”:

This restriction does not allow the addition of duplicate phrases to the common semantic core.
Bukvariks- a separate story. There are a lot of implicit duplicates; the queries differ only in the rearrangement of words. Finds a lot of phrases, but 70-80% of them will not suit us. I add it to a separate group, but I don’t clean it out or work with it, I just search for phrases that interest me by searching to see if I can add something to the basic semantics from it or not.
Collecting search tips
Once you have collected all the phrases in WordStat and competitors, you should combine them into multi-groups, sort them by base frequency (usually from 100, or from 50 if the niche is small) and select target phrases to collect search tips for them:
GIF 
Second iteration of collecting phrases for the semantic core
At this stage, almost everything has been collected :). For a full-fledged kernel, you need to look even deeper and look at the nested phrases for the phrases found during the steps described above.
For phrases collected using the herringbone method, there is no need to repeat the collection iteration, but for queries found from competitors, selected in ABC and search tips, it is worthwhile.
For repeated iteration, I sort the collected phrases by base frequency and select target ones (since we haven’t cleared the stop with words yet, there’s no point in selecting everything) up to a frequency value of 100 units. I re-launch batch collection for them from the left column of Yandex WordStat.
Important: do not mix all the repeated collections together, create separate groups for competitors, bukvariks, the main core assembled by marker words, parsing by the second iteration, and so on. The more detailed you are at the moment of collecting semantics, the easier it will be to clear it of non-target phrases. You will always have time to unite!
3rd step. Removing non-target phrases
At this stage, you need to delete obviously non-target requests. You can do this using universal stop words. I collect them in this file on Google Docs..
We divide all words into: target / non-target / doubt
This step is needed to create a general list of negative phrases, which can be used immediately for the entire advertising campaign and to clear all semantics from non-targeted search queries.
At the output we get a list of target and stop words with which we will clean and check the semantic core.
I am a supporter of the paranoid method :) which takes a lot of time, but is capable of eliminating 95% of all non-target key phrases.
From experience, I will say that the better the list of negative words and phrases is developed, the less non-targeted impressions and impressions by synonyms slip into Yandex Direct, which the search engine loves to add for campaigns of newbies who do not pay due attention to this process.
You will have the purest traffic, as we all unique words in semantics, they were checked manually and their affiliation was determined.
Algorithm of actions:
1. We upload the entire list of key phrases into notepad.
2. Turning phrases into a list of words. There will be a lot of them, if we take my example with semantics for skiing, then about 60 thousand.
An example of automatically replacing a space with a “line break” in notepad:
GIF 
Some people do this step in Word or some other software. I chose notepad for myself. The main advantage is a minimum of actions to obtain the desired result.
3. We copy all the words into Excel and delete duplicates:

After removing duplicates, about 15-20% of the total words remain.
List received all unique words in our semantics. Then I go through each word with a question: target / not target / I doubt it. For words that are clearly targeted, I put 1 in the next cell, for doubters 2, for negative words I don’t put anything, since there will be the most of them.

I check all doubtful words using specific search phrases in the semantic core (quick search of the key collector).
The output is a list of target words and negative keywords. After which, you can relax and try to comprehend the whole process and understand the sequence being described.
Let me summarize the article
I use the word iteration to make the actions being performed clear. But the word “collection” is general and easy to get confused, especially for a beginner.
Now I'm thinking about it. It’s probably in vain that I combined the description of the process of collecting semantics for SEO and Direct. By and large, the second step with an in-depth collection of absolutely all phrases is not needed for context. We only need high-frequency and mid-range phrases (frequency from 100 and above, but depends on the topic) and the most targeted low frequencies.
In any case, points numbered 1 and 3 are absolutely the same for both types of work.
In the following publications, we will begin to group and segment key phrases, as well as clear the semantics of non-target phrases, implicit duplicates and all that garbage, which is approximately 70-80% of what has been collected at this stage.
Subscribe to blog updates at
Today, any business represented on the Internet (and this is, in fact, any company or organization that does not want to lose its audience of customers “online”) pays considerable attention to search engine optimization. This is the right approach that can help significantly reduce promotion costs, reduce advertising costs and, when the desired effect occurs, create a new source of customers for the business. Among the tools with which promotion is carried out is the compilation of a semantic core. We will tell you what it is and how it works in this article.
What is “semantics”
So, we will start with a general idea of what the concept of “collecting semantics” is and means. On various Internet sites dedicated to search engine optimization and website promotion, it is described that the semantic core can be called a list of words and phrases that can fully describe its topic, scope of activity and focus. Depending on how large-scale a given project is, it may have a large (and not so large) semantic core.
It is believed that the task of collecting semantics is key if you want to start promoting your resource in search engines and want to receive “live” search traffic. Therefore, there is no doubt that this should be taken with complete seriousness and responsibility. Often, a correctly assembled semantic core is a significant contribution to the further optimization of your project, to improving its position in search engines and the growth of indicators such as popularity, traffic and others.
Semantics in advertising campaigns
In fact, compiling a list of keywords that best describe your project is important not only if you are engaged in search engine optimization. When working with systems such as Yandex.Direct and Google Adwords, it is equally important to carefully select those “keywords” that will make it possible to get the most interested customers in your niche.

For advertising, such thematic words (their selection) are also important for the reason that with their help you can find more accessible traffic from your category. For example, this is relevant if your competitors work only on expensive keywords, and you “bypass” these niches and promote where there is traffic that is secondary to your project, but is nevertheless interested in your project.
How to collect semantics automatically?
In fact, today there are developed services that allow you to create a semantic core for your project in a matter of minutes. This, in particular, is a project for automatic promotion of Rookee. The procedure for working with it is described in a nutshell: you need to go to the appropriate page of the system, where it is proposed to collect all the data about the keywords of your site. Next, you need to enter the address of the resource that interests you as an object for compiling the semantic core.
The service automatically analyzes the content of your project, determines its keywords, and receives the most definable phrases and words that the project contains. Due to this, a list of those words and phrases that can be called the “base” of your site is formed for you. And, in truth, it is easiest to assemble semantics this way; Anyone can do this. Moreover, the Rookee system, by analyzing suitable keywords, will also tell you the cost of promotion for a particular keyword, and will also make a forecast as to how much search traffic you can get if you promote these queries.
Manual compilation

If we talk about selecting keywords automatically, there’s really nothing to talk about here for a long time: you simply use the developments of a ready-made service that suggests keywords to you based on the content of your site. In fact, not in all cases the result of this approach will suit you 100%. Therefore, we recommend also turning to the manual option. We will also talk about how to collect semantics for a page with your own hands in this article. However, before that you need to leave a couple of notes. In particular, you should understand that manually collecting keywords will take you longer than working with an automatic service; but at the same time, you will be able to identify higher priority requests for yourself, based not on the cost or effectiveness of their promotion, but focusing primarily on the specifics of your company’s work, its vector and the features of the services provided.
Defining the topic
First of all, when talking about how to collect semantics for a page manually, you need to pay attention to the topic of the company, its field of activity. Let's give a simple example: if your site represents a company selling spare parts, then the basis of its semantics will, of course, be queries that have the highest frequency of use (something like “auto parts for Ford”).
As search engine optimization experts note, you shouldn’t be afraid to use high-frequency queries at this stage. Many optimizers mistakenly believe that there is a lot of competition in the fight for these frequently used, and therefore more promising, queries. In reality, this is not always the case, since the return from a visitor who comes with a specific request like “buy a battery for a Ford in Moscow” will often be much higher than from a person looking for some general information about batteries.
It is also important to pay attention to some specific points related to the operation of your business. For example, if your company is represented in the field of wholesale sales, the semantic core should display keywords such as “wholesale”, “buy in bulk” and so on. After all, a user who wants to purchase your product or service in a retail version will simply be uninteresting to you.
We focus on the visitor

The next stage of our work is to focus on what the user is looking for. If you want to know how to build semantics for a page based on what a visitor is searching for, you need to look at the key queries they're making. For this, there are services such as “Yandex.Wordstat” and Google Keyword External Tool. These projects serve as a guide for webmasters to search for Internet traffic and provide an opportunity to identify interesting niches for their projects.
They work very simply: you need to “drive” a search query into the appropriate form, on the basis of which you will search for relevant, more specific ones. Thus, here you will need those high-frequency keywords that were installed in the previous step.
Filtration
If you want to collect semantics for SEO, the most effective approach for you will be to further filter out “extra” queries that turn out to be inappropriate for your project. These, in particular, include some keywords that are relevant to your semantic core from the point of view of morphology, but differ in their essence. This should also include keywords that will not properly characterize your project or will do it incorrectly.

Therefore, before collecting the semantics of keywords, it will be necessary to get rid of inappropriate ones. This is done very simply: from the entire list of keywords compiled for your project, you need to select those that are unnecessary or inappropriate for the site and simply delete them. In the process of such filtering, you will establish the most suitable queries that you will focus on in the future.
In addition to the semantic analysis of the presented keywords, due attention should also be paid to filtering them by the number of requests.
This can be done using the same Google Keyword Tool and Yandex.Wordstat. By typing a request into the search form, you will not only receive additional keywords, but also find out how many times a particular request is made during the month. This way you will see the approximate amount of search traffic that can be obtained through promotion for these keys. Most of all at this stage we are interested in abandoning little-used, unpopular and simply low-frequency requests, promotion of which will be an extra expense for us.
Distribution of requests across pages
Once you have received a list of the most suitable keywords for your project, you need to start comparing these queries with the pages of your site that will be promoted on them. The most important thing here is to determine which page is most relevant to a particular request. Moreover, adjustments should be made to the link weight inherent in a particular page. Let's say the ratio is approximately this: the more competitive the request, the more cited the page should be selected for it. This means that when working with the most competitive ones, we should use the main one, and for those with less competition, pages of the third nesting level are quite suitable, and so on.

Competitor analysis
Don’t forget that you can always “peek” at how websites that are in the “top” positions of search engines for your key queries are being promoted. However, before collecting the semantics of competitors, it is necessary to decide which sites we can include in this list. It will not always include resources belonging to your business competitors.
Perhaps, from the point of view of search engines, these companies are engaged in promotion for other queries, so we recommend paying attention to such a component as morphology. Just enter queries from your semantic core into the search form - and you will see your competitors in the search results. Next, you just need to analyze them: look at the parameters of the domain names of these sites, collect semantics. What kind of procedure this is, and how easy it is to implement it using automated systems, we have already described above.
In addition to everything that has already been described above, I would also like to present some general tips that experienced optimizers give. The first is the need to deal with a combination of high- and low-frequency queries. If you only target one category of these, your promotion campaign may end up being a failure. If you choose only “high-frequency” ones, they will not give you the targeted visitors who are looking for something specific. On the other hand, low-frequency queries will not give you the required amount of traffic.
You already know how to collect semantics. Wordstat and Google Keyword Tool will help you determine which words are being searched for along with your keywords. However, do not forget about associative words and typos. These categories of queries can be very profitable if you use them in your promotion. Both the first and the second we can get a certain amount of traffic; and if the request is low-competitive, but targeted for us, such traffic will also be as accessible as possible.
Some users often have a question: how to collect semantics for Google/Yandex? This means that optimizers focus on a specific search engine when promoting their project. In fact, this approach is quite justified, but there are no significant differences in it. Yes, each search engine works with its own algorithms for filtering and searching for content, but it is quite difficult to guess where a site will rank higher. You can only find some general recommendations on what should be used if you are working with a particular software, but there are no universal rules for this (especially in a proven and publicly available form).
Compiling semantics for an advertising campaign
You may have a question about how to collect semantics for Direct? We answer: in general, the procedure corresponds to that described above. You need to decide: what queries are relevant to your site, which pages will interest the user most (and for which key queries), promotion by which keys will be the most profitable for you, and so on.

The specificity of how to collect semantics for Direct (or any other advertising aggregator) is that you need to categorically refuse non-topical traffic, since the cost of a click is much higher than in the case of search engine optimization. For this purpose, “stop words” (or “negative words”) are used. To understand how to assemble a semantic core with negative keywords, you need more in-depth knowledge. In this case, we are talking about words that can bring traffic that is not of interest to your site. Often these words can be “free”, for example, when we are talking about an online store, in which a priori nothing can be free.
Try to create a semantic core for your website yourself, and you will see that there is nothing complicated here.
Clients ask me: “Alexey, how many keywords will there be in your campaigns?”
The answer is - all in which there is a desire to buy or order a service. I'll explain now.
Great semantics for Direct.
Competitors boast that they can assemble a very large semantic core, 50-100 thousand, sometimes more... You can get such a giant:
- using artificial semantics - by multiplying words. This method gave 1.5 clicks per year to a rare keyword, but now does not work due to the status of “low impressions”
- Also, a large core can be made from informational and cold requests.
There is no need to do either one or the other, the reasons are as follows:
With artificial semantics, 95% of ads will be idle. If you combine them into common groups, this will not greatly affect the statistics, because The main traffic comes from high and mid frequencies.
As for the keys, you only need hot ones - with the desire to buy or order. In work campaigns, I see that there is a difference even for queries with the prefixes “buy” and “price”. In the first case, the audience is live, in the second, they are often simply interested (listening to calls). If we take information systems, this is a total waste of the budget.
The most important thing is that it is impossible to test this mountain of requests. There will be no statistics (at least 100 clicks for each), and the test will cost a pretty penny.
For example, there are 100,000 ads, let each one receive a click in a year. With a click price of 15 rubles. we get a budget for the test - 1.5 million:
 are you ready to give that amount?
are you ready to give that amount? How to assemble a kernel.
Once again about how to approach collecting the semantic core for Yandex.Direct. Only - keywords with purchasing needs:
- organization of events in St. Petersburg
- auto glass replacement Moscow
- order loader services
When you have collected statistics and understand that you need to remove half of the normal keys (no applications, calls), while reducing costs for the client by 30-50%- you feel like a superman:

Conclusions.
I use as many keywords as possible, but taking into account the points that I made in this lesson. There are no tariffs - only full setup of Yandex Direct.
Initially, collect a competent semantic core and analyze the statistics obtained:
- for applications, you need goals on the site and metrics
- for calls - call tracking.
If you need help -