Levitatud teabebaas: Põhitõed. Hajutatud teabebaas
Kas 1C 8.3 või 1C 8.2? Hajutatud teabebaasi seadistamine. Samm-sammuline juhendamine.
Infobaasi jaotust kasutatakse siis, kui on vaja säilitada ühiskirjeid andmebaasides, millel ei ole erinevatel põhjustel füüsilist ühendust. Näiteks võib tuua ettevõtte raamatupidamisarvestuse, millel on suurlinnas või väikelinnas üksus, millel puudub Interneti-ühenduse võimalus. Või mõnel erijuhul perioodilise vajaduse korral töötada ühe andmebaasiga korraga nii kontoris kui ka väljaspool kontorit, näiteks kodus. Sellistel ja sarnastel juhtudel on hajutatud teabebaasi (DIB) kasutamine põhjendatud ja vajalik.
Selles artiklis vaatleme ühe teabebaasi levitamise korraldamist 1C Accounting for Russia versiooni 8.3 konfiguratsioonis kohaliku või võrgukataloogi kaudu. Versioonis 8.2 1C on see juhend kasulik ka, kuna kirjeldab sisuliselt ühte protsessi, millel on oluliselt väikesed erinevused.
==== Põhibaasi seadistamine ====
Pärast 1C 8.3 avamist režiimis "Ettevõte" minge jaotisse "Haldamine". Versioonis 1C 8.2 peate alustamiseks minema peamenüüsse "Teenus" - "Hajutatud teabebaas (DIB)" - "RIB-sõlmede konfigureerimine".

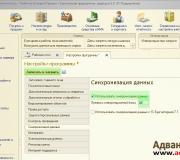
Järgmisena käsitleme protsessi infoturbe versiooni 8.3 kontekstis. Niisiis, minnes jaotisse "Haldus", valige "Programmi sätted". Seadetes minge jaotisse "Andmete sünkroonimine". Siin märgime ruudu "Kasuta andmete sünkroonimist" ja määrame andmebaasi prefiksi. Tähistagem "CB", mis viitab kesksele baasile.
Pärast seda kuvatakse parempoolses menüüs üksus "Andmete sünkroonimine". Valime ta. Avanevas alamaknas klõpsake nuppu "Seadista andmete sünkroonimine". Rippmenüüst saate valida seaded erinevate sünkroonimise kasutusjuhtude jaoks. Valime “Hajutatud teabebaas...”.

Üldise arenduse jaoks tutvuge järgmise akna sisuga ja klõpsake nuppu "Järgmine".

Järgmises aknas täitke kataloog, mille kaudu . Üleslaadimise mahu vähendamiseks määrame andmete tihendamise ja andmetega saate kohe määrata arhiivi parooli. Oluline on teda mitte unustada. Kinnitage täitmine nupuga "Järgmine".

Järgmised kaks akent on mõeldud FTP-serveri ja e-posti teel vahetamise juhtumite sätete määramiseks. Nagu varem öeldud, kaalume vahetusmeetodit kataloogi kaudu, seega jätame FTP ja e-posti seaded vahele.


Järgmine aken on mõeldud vahetusparameetrite määramiseks välisseadmete andmebaasi osas. Märgime selle nime ja eesliide. Järgmine on nupp "Järgmine".

Kontrollime loodud vahetusparameetreid ja kinnitame nende õigsust traditsioonilise nupuga “Järgmine”.

Vahetamiseks vajalik seadete komplekt luuakse automaatselt. See võtab natuke aega.

Tähtis! Orisõlme algkujutise loomine võtab palju aega. Selle olulisuse suurus sõltub arvutiressurssidest ja raamatupidamise mahust põhiandmebaasis.
Oletame, et otsustame luua pildi. Pärast eelmises aknas nupu "Lõpeta" klõpsamist sisestame seaded, et luua pilt alaminfoturbest. Vaatleme kohalike toimingute jaoks lihtsaimat juhtumit. Selleks märkige avanevas aknas vajalikud andmed. Pöörame erilist tähelepanu parameetrile "Failibaasi täisnimi". See peab olema määratud täielikus UNC-vormingus, mis nõuab kohaliku tee moodustamist "võrgu" vormingus. Näiteks - "\\Server1C\Databases\RIB". Määratud teele lisame andmebaasi faili nime - 1Cv8.1CD.
Pärast nupu "Loo esialgne pilt" klõpsamist algab alamandmebaasi pildi genereerimise protsess.

Pärast protsessi lõppu luuakse määratud kataloogis andmebaasifail. See vastloodud andmebaas tuleb enne täielikku kasutamist konfigureerida.
==== Välise baasi seadistamine ====
Selleks peate selle ühendama 1C-ga. Kuidas seda teha, leiate meie artikli juhistest - Pärast ühenduse loomist peate käivitama uue andmebaasi konfiguraatori režiimis ja looma kasutajad. Järgmisena tuleb infoturve käivitada režiimis 1C “Enterprise”.
Kui kasutajate loomine tuleb mingil põhjusel hilisemale ajale lükata, saate pärast ühenduse loomist andmebaasi lihtsalt käivitada režiimis 1C “Enterprise”. Teil palutakse luua "Administraatori" kasutaja, nõustuda sellega ja esmane täitmine tehakse.

Seejärel peate jätkama põhialusega sidumise seadistamist. See säte on sarnane ülalpool põhiandmebaasi puhul käsitletule.




Luuakse põhibaasiga suhtlemise seadistus.

============================================
Niisiis, nüüd oleme loonud peamised ja perifeersed baasid. Kõigis nendes andmebaasides on loodud ka sünkroonimisseaded. Nüüd saate liikuda nende sätete muutmise ja sobivasse vormi viimise juurde. Saate luua automaatseid vahetusreegleid või teostada vahetust käsitsi.
Teeme seda põhiandmebaasis. Välisseade on konfigureeritud samal viisil.
Redigeerimist saab rakendada andmete sünkroonimise reeglitele ja ajakavadele.

Klõpsates jaotises "Andmete sünkroonimise ajakava" nuppu "Seadista", peate skripte redigeerima, et valitud andmebaasi andmete üles-/laadimistööd automaatselt ajastada. Te ei pea seda muutma, vaid nõustuge vaikevalikutega.

Parameetrite muutmiseks klõpsake lihtsalt automaatsete ajakava andmetega linki. Ja siis muudame ülesannete käivitamise ajutisi parameetreid. Järjehoidjaid läbides saate muuta nii käivitamise kellaaega kui ka kuupäevi ja nädalapäevi.

Klõpsates skripti põhiaknas nuppu "Käivita ülesanne", saate ülesande käsitsi käivitada.
Klõpsates jaotises "Andmete sünkroonimise reeglid" nuppu "Seadista", saate teha toiminguid ülesannete käivitamise skriptide muutmiseks ning vaadata üles- ja allalaadimiste logi. Viimane on üsna oluline juurdepääsu administreerimiseks ja vahetuste regulaarsuse jälgimiseks.

Kui olete lõpetanud hajutatud andmebaasivahetuse automaatse käivitamise skriptide loomise ja redigeerimise, saate jätkata andmete üleslaadimist ja seejärel laadimist.
Sel hetkel on kesk- ja perifeerse sõlme hajutatud supelmajade andmebaasi konfigureerimine põhimõtteliselt lõpule viidud.
Laadige alla illustreeritud juhised
Hajutatud teabebaas. Samm-sammuline juhendamine
Hajutatud teabebaas (RIB) 1C: Enterprise
Hajutatud teabebaasi loomine ja seadistamine
kuidas ribi seadistada ühe sekundiga 8.2
Kuidas luua 1C-s hajutatud teabebaasi
Kuidas seadistada 1C-s
Kuidas seadistada 1C-s
Hajutatud teabebaasi (RIB) seadistamine 1C-s
Näide RIB-i seadistamisest 1C:Accounting 8 jaoks
Hajutatud teabebaasi ja konfiguratsiooni loomine
See on minu esimene artikkel, konstruktiivne kriitika on teretulnud.
Sihtrühmaks on need, kes puutuvad RBD-ga esimest korda kokku.
RDB ülesanded
Esimene asi, millest peate alustama, on vastamine küsimusele "Miks me vajame RDB-d?" Võimalikke vastuseid on palju, eelkõige:
- Meie filiaalid töötavad lahti ühendatud andmebaasides. Nüüd tahame, et nendevaheline teave oleks sünkroonitud;
- Meil on filiaalid, kuid andmebaasi koormus on liiga suur (see tähendab tehingute blokeerimist, mitte andmebaasi mahtu) ja veebipõhine asjakohasus (mitte segi ajada asjakohasusega mõne minuti pärast, online on see, kui pärast iga tehingut on andmed teise sõlme üle kantud) harude kohta pole vaja andmeid;
- Meil on filiaale, kus toimub ainult andmete sisestamine (näiteks jaekauplused), seega saame oluliselt vähendada keskandmebaasi koormust;
- Turvakaalutlustel soovime, et filiaalidel ei oleks isegi teoreetiliselt (administraatori parooliga) juurdepääsu olulistele andmetele, näiteks ettevõtte bilansile.
Ühel juhul olid minu jaoks olulised küsimused 2 ja 4, teisel juhul 2 ja 3. Esimene punkt on liiga ulatuslik ja seda ei käsitleta käesoleva artikli raames.
Samuti on parem kohe kaaluda vahetusfailide transportimise probleemi, sest mõnel juhul võib see andmevahetuse rakendamisele seada olulisi piiranguid. Esiteks peate kindlaks määrama, millistes harudes RDB sõlmed täpselt ilmuvad (tavaliselt on need piirkondlikud filiaalid). Järgmisena kaalume, kuhu veel tahame RDB-sõlmi installida ja kas need vajavad veebipõhist asjakohasust. Näiteks jaekaupluste jaoks ei ole alati võimalik isegi modemit paigaldada ja traadita ühenduse paigaldamine läheb liiga kulukaks. Siin peate tegema otsuse - võib-olla saab see pood töötada võrguühenduseta ja perioodiliselt keskusega vahetada (üks kord päevas / kord nädalas), kasutades füüsilist andmekandjat, näiteks mälupulka.
Mõnel juhul pole füüsilise andmekandja kaudu vahetamine võimalik, näiteks on tegemist väga kauge haruga, kus on olulisi probleeme kiire side seadistamisega. Siin tasub umbkaudselt välja arvutada vahetatava teabe hulk. Sageli, kui see on asjakohane kord tunnis või mitu korda päevas, piisab 32k modemist. Siiski tasub meeles pidada, et koos andmevärskendustega tuleb mõnikord saata ka konfiguratsiooni enda või väliste failide uuendusi (trükitud vormid, kaubafotod), nii et aeg-ajalt tekib olukord, kus vahetusfail suureneb märkimisväärselt. sellistele uuendustele.
Topoloogia
Kokku saime järgmised vastust vajavad küsimused:
- Millistes osakondades on meil garanteeritud RDB sõlmede paigaldamine ja kas sinna on võimalik paigaldada kiire kanal;
- Millistes osakondades ei nõuta RBD seadme paigaldamist?
- Millised osakonnad saavad mitme tunni jooksul asjakohaselt töötada;
- Millised osakonnad saavad töötada võrguühenduseta (andmevahetus vähem kui 3-4 korda päevas).
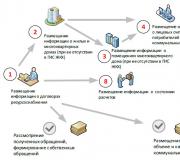
Pärast nendele küsimustele vastamist saame oma RDB ligikaudse diagrammi. Suurte ettevõtete puhul selgub tavaliselt midagi sellist:
Joonis 1. Suurettevõtte RDB tüüpiline diagramm
Kui "Branch" sõlmedega on kõik suhteliselt selge - need on suured keskused, mis nõuavad automatiseerimist, siis "Store" sõlmed tähendavad andmete sisestamisel andmebaasi tõsiselt koormavat sõlme, mis tuleks koormuse vähendamiseks eraldada. Näiteks kauplus, kus on 50 kassaaparaati ja mille päevakäive on üle 10 000 ühiku.
- Kauplused – sisesta andmed enda käibe ja rahavoo kohta. Analüütika on pealiskaudne, ainult teie enda poe jaoks.
- Filiaalid - automatiseerimata punktide andmesisestus, raamatupidamine, palgad ja personal, tootmine jne. Analüütika teie enda filiaalis.
- Keskus - automatiseerimata filiaalide andmete sisestamine. Ettevõtte kui terviku analüüs.
Oluline on mõista, millistel eesmärkidel andmebaasi igas sõlmes kasutatakse. Eesmärkidest ehitatakse üles elluviimiseks vajalikud ülesanded, näiteks:
- Filiaalid näevad vastastikuste arvelduste ajalugu üksteise vastaspooltega;
- Kauplused näevad kogu ettevõttes (või selle osas) ülejääke;
- Tulude/kulude, eelarve täitmise jms analüüs on nähtav ainult Sinu enda osakonna hierarhias;
- Raamatupidamine, palgaarvestus ja personal on nähtavad ainult teie enda osakonna hierarhias;
- Nomenklatuur, kõik selle omadused ja omadused on nähtavad kõigis RDB sõlmedes;
- Seoses osakondade hierarhiaga liiguvad kõik andmed ülespoole, kuid filtreeritakse allapoole;
- Keskus sisaldab absoluutselt kogu teavet ettevõtte kohta.
Selliseid küsimusi endale esitades saate vastata kõige keerulisemale küsimusele - milline teave, kuhu ja kuidas peaks RDB sõlmede vahel liikuma? Miks on see kõige raskem? Teades, millised andmekomplektid sõlmede vahel ringlevad, saate selgelt aru, kuidas praegust andmebaasi "lõika" nii, et andmed jääksid loogiliselt järjepidevaks. Näiteks ei saa kaupade bilansi andmeid eraldada jooksvate reservide andmetest.
Nüüd, sõltuvalt teabevoogudest, joonistame RDB diagrammi ümber:
Mida me näeme joonisel 2? Vastavalt ettevõtte allüksuste hierarhiale ehitati üles andmebaasisõlmede vahelise infovoo topoloogia. Lisatud on ka sõlm “Center 2”, miks? Star topoloogia rakendamisel on tsentri koormus alati suurem kui perifeersete sõlmede koormus ja sageli on sõlme enda tekitatud koormus juba suur. Näited sõlmede "Center 1" ja "Center 2" kasutamise kohta:
- "Center 1" on mõeldud ainult andmete konsolideerimiseks teistest RDB sõlmedest. Ainult administraatoril on sellele juurdepääs. "Keskus 2" teenindab peakontori tööd;
- “Center 1” teenindab peakontori tööd. Kuid sõlmes "Center 2" tehakse raskeid analüütilisi ja testimistoiminguid, mis tekitavad andmebaasile tohutu koormuse; näiteks järjestuse taastamine, suletud perioodide ajastamine, kogu ettevõtte koondaruannete koostamine pika aja jooksul, analüütika genereerimine, mis toob kaasa muudatusi andmetes;
- “Center 1” teenindab peakontori tööd. “Center 2” on varukoopia ettenägematute olukordade korral kogu RDB kiireks taastamiseks.
Vahetuse rakendamine
RDB tööks on 2 võimalust:
- Automaatne – toimub ilma kasutaja sekkumiseta. Juhtimine hädaolukordade üle määratakse kas andmebaasi administraatorile või edasijõudnud kasutajale;
- Käsitsi - vahetus toimub ainult kasutaja soovil.
Oma kogemuse põhjal olen alati kõik juurutused juhtinud automaatsele versioonile. Kui vahetusfailide transportimisega oli probleeme (võrgu olemasolu sõlmes ei ole konstantne), siis maksimaalne, mida kasutaja sai teha, oli klõpsata nupul „Vaheta kohe”. Olukordades, kus lisaks andmete uuendamisele toimub ka konfiguratsiooniuuendus, on soovitatav seda teha ka täisautomaatselt (näiteks kasutades kolmanda osapoole tarkvara).
Värskenduspakettide genereerimine
Kuna on ühemõtteline otsus selle kohta, millistele RDB sõlmedele millised funktsioonid määratakse, on võimalik genereerida ainult see andmepakett, mida see sõlm vajab. Ühest küljest on vaja täpsustada, millist tüüpi objekte sõlmede vahel sünkroonitakse. Näiteks ei tohiks sõlme “Pood 1” raamatupidamisregistreid üldse sünkroonida, sest Andmed sisestatakse ainult harusõlme tasemel. Teisest küljest tuleb seda tüüpi andmeid, mida vahetatakse, filtreerida osakonna alusel. Näiteks sõlmest “Kauplus 1 filiaal 2” raha laekumise andmed võivad asuda ainult sõlmedes “Keskus 2”, “Keskus 1” ja “Keskus 2”.
Siiski on ka vastupidine probleem: kui vahetusandmeid liiga palju filtreerida, kaotab andmepakett oma loogilise terviklikkuse. Näiteks kaupade saldosid võetakse arvesse ladude kontekstis ja reserve arvestatakse ettevõtte kui terviku kontekstis, siis kui filtreerida kaupade jäägid ladude kaupa ja reserve ei filtreeri, siis andmed on valed.
Samuti peaksite otsustama, millises eluetapis tuleks objekt välja vahetada. Näiteks saab vahetada ainult konteeritud arveid, aga mitte lihtsalt salvestatud arveid. Kas poe arveid ei laadita kunagi Centeri sõlmest maha, isegi pärast nende korrigeerimist, kuid tuleb arvestada vastupidise efektiga - andmed võivad olla sünkroonist väljas või mõned muudatused üle kirjutatud.
Oluline on mõista, et sõlmede vahel vahetades on prioriteet ühel neist. Mõelge olukorrale:
- Sõlmes “Pood 1” loodi dokument;
- Vahetuse käigus sattus ta sõlme “Branch 1”;
- Dokumenti parandatakse samaaegselt mõlemas sõlmes.
Millist dokumenti peetakse tõeseks? 1C 8.x-s on mehhanismi “Vahetusplaanid” kasutamisel vaikeprioriteediks põhisõlm, st. sel juhul lähevad sõlmes “Pood 1” tehtud muudatused kaotsi ja need asendatakse sõlme “Branch 1” andmetega.
On veel üks, keerulisem olukord, kui kahte ühendatud objekti reguleeritakse samaaegselt. Näiteks arvet ja selle PQR-i korrigeeritakse erinevates sõlmedes, hindade, maksesummade, vastaspoolte jms muutmisel on võimalik terviklikkuse kaotus.
Samuti on oluline kontrollida objektide kustutamist, vastasel juhul võib see kaasa tuua selle, et näiteks arvet ei ole enam olemas, kuid raamatupidamislikud liikumised jäävad alles.
Vahetusmehhanismid punktis 1C 8.x
Rakendamiseks on kaks lähenemisviisi:
- Vahetusplaanide mehhanism;
- Objekti registreerimise enda teostus.
Mõelgem mõlemale võimalusele.
Vahetusplaanide mehhanism võimaldab ilma igasuguse konfiguratsioonita mõne minutiga luua täieliku andmevahetusega andmebaasi. Kui seate lipukese “Distributed infobase”, siis värskenduspaketi loomisel laaditakse alla ka konfiguratsioonivärskendused. Vaid mõne minutiga saate seadistada reeglid erinevat tüüpi andmete vahetamise lubamiseks/keelamiseks, avades vahetusplaani koosseisu. Kui seate lipu "Automaatne registreerimine" asendisse "Keela", ei vahetata seda tüüpi objekte kunagi ilma täiendava pingutuseta.
Miks on vaja registreerimist, miks mitte kõike korraga üles laadida? Igal juhul on ainult andmebaasi oleku muudatusi sisaldav fail väiksem kui andmebaasi enda täielik hetktõmmis. Seetõttu ei võeta arvesse täieliku mahalaadimise võimalust.
Kuidas seadistada andmete filtreerimist osakonna kuuluvuse järgi? Siin peate juba programmeerima. Minu teostuses paigaldati mis tahes objekti salvestusele sündmuse “Kirjutades” tellimus, kus atribuuti “Andmevahetus. Saajad” kasutades saab määrata selle objekti adressaatide nimekirja. Need. Kui laadite maha standardsete vahenditega sõlme jaoks, mida loendis ei ole, objekti maha ei laadita. On ka teine lahendus - vahetusplaani mooduli protseduurides “Andmete saatmisel alluvale” ja “Andmete saatmisel peremehele” saab valida, kas objekt maha laadida objekti mahalaadimisel otse.
Mõlemal variandil on õigus eksisteerida. Siiski valisin parimaks esimese variandi, kuna objekti kirjutamisel toimub koheselt eellaaditavuse atribuudi arvutamine, mis suurendab objekti salvestamise kestust 3-5% (saab optimeerida, mõnel juhul võib vähendada 0,01%-ni, s.o. keskmiselt 0,1-0,3 sekundit ja objekti mahalaaditavuse arvutamisel vahetult andmete saatmisel, mis juba tekitab andmebaasile märkimisväärse koormuse, on see aeg kuni mitu minutit.
Vahetusplaanide mehhanismi toimimise täielikuks mõistmiseks soovitan lugeda raamatu "Professionaalne areng 1C:Enterprise 8 süsteemis" 15. peatükki, Gabets A.P., Goncharov D.I.
Igasugune enda rakendamine minu arvates kas kordab mehhanismi "Vahetusplaanid" või laadib objekti muutmisel kohe maha või laadib maha rohkem kui "Vahetusplaanide" mehhanism (näiteks laadige maha kõik tänaseks tehtud muudatused). Rakenduskogemuse puudumise tõttu ma seda probleemi ei käsitle.
Transport
Failide ülemseadmest alamsõlme transportimise ülesanne on vähendatud maksimaalse veataluvuseni. Pole haruldane, et faile krüpteeritakse või edastatakse turvalise kanali kaudu. Failide edastamiseks on soovitatav kasutada mitut erinevat teenust või valmistada ette mitu erinevat ühendusvõimalust. Näiteks on peamine edastusmeetod VPN-tunneli kaudu ühendatud FTP-serveri kasutamine; Varuserver on TLS-ühendusega meiliserver. Miks vajate mõne muu teenusega varukanalit? Nagu praktika näitab, on 2 erineva FTP-serveri kasutamine vähem usaldusväärne kui FTP-server ja e-post.
Soovitan uuenduspaketi loomise teenuse eraldada transporditeenusest, see tõstab kogu andmevahetuskompleksi tõrketaluvust. Kui failiedastusteenus ei tööta, jätkab värskenduspakettide loomise teenus tavapäraselt tööd ning teatud tingimustel taaskäivitab transporditeenuse ja vastupidi.
Minu RDB rakendamine
Rakendamine on täiesti autonoomne, nii et maksimaalne veataluvus toimis alamülesandena. Selle tulemuseks oli 2 teenust – uuenduste transporditeenus ja andmete impordi/ekspordi teenus. Mõlemad teenused töötavad üksteisest sõltumatult.
Pärast iga edukat andmete impordi-ekspordi tsüklit salvestati selle sõlmega viimase vahetuse aeg. Kui vahetust väga pikka aega ei toimunud, hakkas transporditeenus faile üles laadima kõikidesse talle saadaolevatesse sidekanalitesse, eeldades, et teine sõlm saab siiski värskendusi ja laadib oma failid üles. Erakorraliste olukordade korral saadab süsteem ise administraatorile teate vea üksikasjaliku kirjeldusega.
Liikluse vähendamiseks pakiti xml-failid zip-arhiividesse. Süsteem toetab kahte tüüpi transporti – FTP ja e-post.
Andmefiltri sätetena on kaks tabelit. Üks (vahetusplaanide tabeliosa) salvestab tingimused üldiste üksikasjade jaoks (iga objekti kohta püüab süsteem seda detaili leida), teine sisaldab konkreetse metaandmeobjekti sätteid. Iga objekti salvestamisel otsitakse esmalt tingimusi üldiste detailide järgi (näiteks Division), misjärel proovib süsteem kõiki selle detaile kasutades kindlaks teha, kas seda tüüpi objektile on olemas isiklik reegel. Ma ei soovita loendeid filtreerida - eksimise võimalus on suur, näiteks kaob arve tabeliosast mitu rida ning jääk liigub ja vastupidi.
Oluline on mõista, millise süsteemi kasutaja all teenused töötavad, sest Teil ei pruugi olla piisavalt õigusi failide loomiseks isegi 1C ajutises kaustas. Silumiseks soovitan iga edukalt sooritatud toiming kirjutada registreerimislogi või txt-faili. 1C 8.1 puhul ei saa serveri koodi täitmist siluda.
Silumise ja juurutuse seadistamise hõlbustamiseks lisan töötluse "Muudatuste registreerimine", mille kirjeldus on töötlemisel endal.
Andmevahetuskompleksi üldine tööskeem on näidatud joonisel 3.
Andmete filtreerimine toimub iga objekti sündmuse "BeforeRecording" tellimuse korral. Ärge unustage, et esialgse sõlmepildi loomisel tuleb andmeid ka filtreerida. Esialgse pildi loomise protseduur on üsna pikk, seega soovitan selle koodi maksimaalselt optimeerida (näiteks filtreerimisseadete vahemällu salvestamine).
Järelsõna
Peamine ülesanne on vastata järgmistele küsimustele:
- Miks me vajame RDB-d?
- Mis ei meeldi RDP kliendi kaudu töötades?
- Kuhu ja miks me tahame RDB sõlmed installida?
- Kuidas värskendusi edastatakse?
- Millist tõrketaluvust rakendatakse?
"Muudatuste registreerimise" töötlemine
Töötlemine võimaldab sundida registreeritavatesse objektidesse muudatusi. Muudatuste logimiseks on mitu võimalust:
- Kui mingid metaandmed on märgitud ja ühtegi objekti pole valitud ning lipp "Laadi kõigi väärtuste järgi" EI ole seatud, siis ON REGISTREERITUD AINULT VALITUD TABEL;
- Kui on seatud lipp "Laadi üles kõigi väärtuste jaoks", laaditakse valitud metaandmed maha kõigi tsükli objektide kohta;
- Kui lüliti on seatud režiimile "Laadi üles ainult valitud objektid", laaditakse maha ainult valitud objektid (näiteks: metaandmetele lipu seadmine ilma objekte valimata võrdub lipu "Laadi üles kõigi väärtuste järgi" ja lüliti sisselülitamisega asendis "Ainult valitud objektide mahalaadimine";
- Kui lüliti on seatud režiimile "Tühjenda valitud ja otseselt seotud objektid", siis laaditakse maha valitud objektid ja need objektid, mille olemasolu sõltub valitud objekti olemasolust (näiteks: kataloogide puhul - alluvad kataloogid);
- Kui lüliti on seatud režiimile "Laadi üles kasutades kõiki linke", laaditakse maha KÕIK objektid, mis sisaldavad linki valitud objektile.
Saadaval on lisafunktsioonid:
- Silumiseks on sageli vaja registreeritud objektide ümberregistreerimist;
- Silumiseks on sageli vaja registreeritud eemaldada;
- Muudatuste printimine – muudetuks märgitud objektide täieliku loendi printimine;
- Konfiguratsioonipuu printimine on mõeldud ainult kogu konfiguratsiooni vaatamise hõlbustamiseks.
Juhised hajutatud andmebaaside loomiseks ja konfigureerimiseks URDB (URIB) komponendi abil
URDB (Distributed Database Management) komponenti kasutatakse teabe vahetamiseks kahe identse 1C andmebaasi vahel. Kui konfiguratsioonid on erinevad, saate seda ka kasutada, see on kirjutatud teises. Komponendi töötamiseks peab teil olema programmi 1C: Enterprise kaustas BIN fail DistrDB.dll.
Vaatame hajutatud andmebaaside loomise samme. Näiteks on meil tööbaas kataloogis D:\base1. See tuleb muuta keskseks ja luua perifeerne alus.
1. Loo välisseadmete andmebaasi jaoks kataloog D:\base2.
2. Looge kataloogides D:\base1 ja D:\base2 kaustad CP ja PC (kasutage ladina tähti).
3. Käivitage keskandmebaasi konfiguraator (D:\base1) ja valige Menüü - Administreerimine - Hajutatud teabeturve - Haldus.
4. Klõpsake nuppu "Central Information Security", ilmuvas aknas sisestage andmebaasi kood ja nimi. Koodi jaoks on parem kasutada numbreid või ladina tähti. Sisestage näiteks 001 ja "Central base", kinnitage, vajutades nuppu "OK".
5. Välisseadmete andmebaasi loomiseks klõpsake nuppu "Uus välisseadmete teabe turvalisus". Sisestame selle parameetrid: 002 ja “Peripheral base 1”.
6. Kasutage kursorit, et valida alus „Peripheral base 1“ ja vajutage nuppu „Setup“. autovahetus". Seadistustes muutke käsitsi režiim automaatseks. Olge ettevaatlik, see on oluline.
7. Valige kursori abil andmebaas "Peripheral base 1" ja vajutage nuppu "Laadi andmed üles" ja seejärel nuppu "OK". Üleslaadimise tulemusena ilmub fail D:\base1\CP\020.zip.
8. Käivitage 1C konfiguraatori režiimis, lisage 1C käivitusaknas uus andmebaas “Peripheral database 1”, määrake selle jaoks eelnevalt loodud kataloog D:\base2.
9. Valige Menüü - Haldus - Hajutatud teabeturve - Haldus. Küsimusele “Infobaasi ei leitud. Kas soovite andmeid laadida?" Klõpsake nuppu "Jah" ja määrake faili nimi "D:\base1\CP\020.zip", klõpsake nuppu "OK". Kui allalaadimine on lõppenud, võib välisseadmete andmebaasi loomise protsessi lugeda lõpetatuks.
Antud on ka välisandmebaasi loomise meetodid, taastades keskandmebaasi koopia varukoopiast või lisades keskandmebaasi koopia failid SQL-vormingus ja käivitades skripti. See on kasulik suurte andmemahtude puhul, kui üles- ja allalaadimine võtab tunde või on täiesti ebareaalne.
Juhised URDB (URIB) komponendi abil hajutatud andmebaaside vahel vahetamiseks
Vaatleme lihtsustatud näidet; me teostame vahetuse käsitsi, käivitades konfiguraatori. Saate kasutada konfiguraatori pakkrežiimi; vahetuspakettide edastamiseks saate kasutada posti, ftp-d ja automaatset failide kopeerimist.
Vahetuse teostamiseks tuleb valida Menüü – Haldus – Hajutatud teabeturve – Automaatvahetus. Kui vahetus on automaatne (vt eelmise juhise punkt 6), siis kõik läheb korda.
1. Seega muudame või loome mõned objektid, mis migreeruvad välisseadmete andmebaasi. Objektide migratsioonireeglid määratakse objekti atribuutide vahekaardil "Migratsioon" (vt objektipuud konfiguraatoris).
2. Käivitage keskandmebaasi konfiguraator, valige Menüü - Haldus - Hajutatud teabeturve - Automaatvahetus, klõpsake nuppu "Käivita".
3. Teisaldage saadud fail D:\base1\CP\020.zip kausta D:\base2\CP\
4. Muudame välisseadmete andmebaasis mõnda objekti. Eelistatavalt mitte neid, mida enne keskandmebaasis muudeti, sest keskandmebaasil on vahetuse käigus objektide muutmisel eelisõigus.
5. Käivitage välisseadmete andmebaasi konfiguraator, valige Menüü - Administreerimine - Hajutatud teabeturve - Automaatvahetus, klõpsake nuppu "Käivita".
6. Automaatvahetuse tulemusena peaks meil tulema keskandmebaasist muudatusi. Meil peaks olema ka fail, mis edastatakse keskandmebaasi D:\base2\PC\021.zip
7. Kopeerige fail D:\base2\PC\021.zip kausta D:\base1\PC
8. Korrake punkti 2. Selle tulemusena ilmuvad välisandmebaasist saadud muudatused keskandmebaasi.
Niisiis, vahetuse üldpõhimõte: automaatse vahetuse vahelduv käivitamine koos failide (vahetuspakettide) samaaegse liigutamisega ühe andmebaasi arvuti kaustast teise andmebaasi arvuti kausta ja ühe andmebaasi CP kaustast teise andmebaasi CP kausta. teine andmebaas.
Konfiguratsioonimuudatused tehakse ainult keskandmebaasis. Konfiguratsiooni muutmisel on vaja välisseadmete andmebaasides vahetada eksklusiivses režiimis. Välisandmebaaside pakettide edukaks töötlemiseks keskandmebaasis tuleb konfiguratsioon laadida välisseadmete andmebaasidesse. Kui jääte segadusse, pole midagi, keskandmebaasi poolt tagasi lükatud pakett laaditakse uuesti alla.
Sageli tekib olukord, kui organisatsioonil on mitu filiaali või jaemüügipunkti, mis asuvad üksteisest geograafiliselt kaugel. Siiski on jätkuvalt vaja säilitada kogu organisatsioonis järjepidevat arvestust. Üks selle probleemi lahendamise võimalustest on luua ühtne võrk, mis hõlmab kõigi filiaalide automatiseeritud tööjaamu ja majutab 1C teabebaasi avalikus serveris. See meetod võib olla tehniliselt keeruline ja kulukas. Lisaks kerkivad esile mitmed infoturbega seotud probleemid.
Teine võimalus on luua hajutatud teabebaas (RIB). Hajutatud teabebaas on hierarhiline struktuur, mis koosneb eraldi teabebaasidest platvormil 1C:Enterprise, mille vahel korraldatakse andmevahetust konfiguratsiooni ja andmete sünkroonimise eesmärgil. Neid üksikuid teabebaase nimetatakse RIB-sõlmedeks.
Jaotatud teabebaasi saab luua 1C: Enterprise süsteemi erinevate konfiguratsioonide põhjal. Mõelgem selle loomisele 1C näitel: kaubanduse juhtimine 10.3.
Oletame, et kaubandusorganisatsioonis avatakse täiendav jaemüügipunkt, kus on vajalik juurdepääs organisatsiooni üldisele kauplemissüsteemile. RIB-i loomiseks peate tegema järgmised sammud:

See lõpetab hajutatud teabebaasi loomise. Info vahetamiseks tuleb alustada andmevahetust Keskandmebaasis (selles toimunud muudatused laetakse alla), seejärel poes (keskandmebaasist tehtud muudatused laetakse alla ja poes toimunud muudatused ) ja uuesti keskandmebaasi (sellesse laaditakse muudatused, mis toimusid poes).
Hajutatud teabebaasidel on oma kokkupõrke lahendamise mehhanism. Seega, kui vahetuse käigus selgub, et mõnda objekti (dokumenti, kataloogi jne) on muudetud nii põhi- kui ka allandmebaasis, siis on prioriteet põhiandmebaasis tehtud muudatus.
Kui on vaja muuta hajutatud infobaasi konfiguratsiooni, tuleb seda teha juursõlmes (vt artikli esimest joonist), ülejäänud sõlmede konfiguratsioonid lukustatakse. Pärast vajalike muudatuste tegemist saab need RIB-sõlmede vahelise andmevahetuse standardprotseduuri abil üle kanda alamsõlmedesse. Pärast vahetuse läbiviimist alamsõlme konfiguraatoris on vaja teabebaasi konfiguratsiooni värskendada.
Kui teil on probleeme hajutatud teabebaasi seadistamisega, aitavad meie spetsialistid andmevahetust seadistada ja selgitavad üksikasjalikult, kuidas seda kasutada.
Jaotatud teabebaasi loomiseks peate programmi sisestama režiimis 1C: Enterprise. Jaotatud andmebaasi sõlmede loomiseks valige menüüst: Toimingud - Vahetusplaanid. Avaneb aken "Vali objekt: Vahetusplaan".
1. Kaaluge valikut "täieliku" vahetusplaaniga.
Vahetus viiakse läbi kõigi hajutatud teabebaasis asuvate organisatsioonide lõikes.
Valime "täieliku" vahetusplaani. Avaneb aken "Täielik vahetusplaan".
Täidame kaks kirjet:
Nimetagem esimest kirjet "Põhisõlm", märkige kood "GU",
Nimetagem teist kirjet "allsõlm", märkige kood "PU".
Nagu jooniselt näeme, on esimesel kirjel rohelise ringiga ikoon, see on ikoon "Põhisõlm".

“Peasõlme” teabebaasi koopia loomiseks klõpsake “Slave node” ja klõpsake ikooni “Loo esialgne pilt”. See on teabebaas "Allsõlm".

Avaneb aken “Esialgse infoturbe pildi loomine”, vali “Selles arvutis või kohtvõrgus olevas arvutis”, vajuta “Edasi”.

Valige väljal "Infobase'i kataloog" koht, kuhu "Põhisõlme" koopia installitakse, ja klõpsake nuppu "Lõpeta".

Pärast teabebaasi "Allsõlm" loomist kuvatakse järgmine teade:

Klõpsake nuppu "OK".
Lisage "1C: Enterprise" teabebaas "Allsõlm". Me läheme allutatud andmebaasi režiimis "1C: Enterprise". Avame: Toimingud – Vahetusplaanid. Avaneb aken "Vali objekt: Vahetusplaan". Valime "täieliku" vahetusplaani. Avaneb aken "Täielik vahetusplaan". Näeme, et ikoon “Põhisõlm” on oranž, mis tähendab, et see sõlm on meie asukoha teabebaasi põhisõlm.

Teeme nii ülem- kui ka alamsõlmedes järgmised sätted:
1.
Lisage hajutatud teabebaasi eesliide.
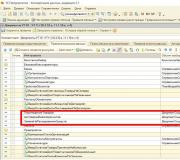
Seda tehakse selleks, et kahes andmebaasis loodud dokumentide ja kataloogide numbrites ja koodides ei tekiks konflikte, seega märgime igas andmebaasis prefiksi, mis lisatakse dokumendinumbritele ja kataloogikoodidele. Avage: Tööriistad - Programmi sätted - vahekaart "Andmevahetus". Sisestage väljale "Hajutatud teabebaasi sõlme eesliide" allandmebaasi "PU" ja põhiandmebaasi "GU".

2.
Lisage seade sõlmede vaheliseks andmevahetuseks:
Ava: Teenus – hajutatud teabebaas (DIB) – RIB-sõlmede konfigureerimine. Avaneb aken "Andmevahetuse seaded".

Klõpsake "Lisa" ja avaneb aken "Andmevahetuse seaded". Sisestage oma seade "Nimi".

Sõlm ilmub automaatselt väljale "Sõlm", "Peasõlme" jaoks on "Sõlm", "Alusõlme" jaoks on "Peasõlm".
Väljal "Kaust" valige kaust, kuhu vahetusandmed saadetakse; kõige parem on määrata üks kataloog põhi- ja alamandmebaasi jaoks.
Väljal "Vahetustüüp" konfigureerime andmete edastamise andmebaaside vahel: faili või FTP-ressursi kaudu. Valige näiteks "jagamine failiressursi kaudu".
Ülejäänud väljadel me midagi ei muuda.
Klõpsake nuppu "OK". Näeme, et on ilmunud seadistus.
3.
Andmete vahetamiseks teeme järgmist:
Kõigepealt klõpsake andmebaasis, kus muudatused tehti, ikooni "Vaheta vastavalt kehtivale seadistusele", nagu on näidatud joonisel.

Pärast üleslaadimist ilmub üleslaadimise tulemuste aken.

Seejärel klõpsake andmebaasis, kuhu soovite muudatusi üle kanda, ikooni “Vaheta vastavalt kehtivale seadistusele” ja andmed lähevad soovitud andmebaasi.
2. Kaaluge võimalust vahetusplaaniga "Organisatsiooni järgi".
Vahetus viiakse läbi hajutatud teabebaasis asuvate valitud organisatsioonide vahel.
Hajutatud andmebaasi sõlmede loomiseks valige menüüst: Toimingud - Vahetusplaanid. Avaneb aken "Vali objekt: Vahetusplaan".

Valime vahetusplaani “Organisatsiooni järgi”. Avaneb aken „Organisatsiooni vahetusplaan”.
Täidame kaks kirjet:
Nimetagem esimest kirjet "Põhisõlm", märkige kood "GU", näeme erinevust "Vahetusplaanist: täis", ilmus tabel, milles märgime organisatsioonid, mille jaoks vahetus toimub.
Nimetagem teist kirjet "allsõlm", märkige kood "PU", märkige organisatsioon.

Kõigis muudes aspektides on seadistus absoluutselt sama, mis "Vahetusplaan: täis".