Hashing van gegevens. Hash-functies: concept en basis
Hij is dezelfde hasj "hash-functie"
Staat op de lijst.
Wat is een hasj? Een hashfunctie is een wiskundige transformatie van informatie in een korte, gedefinieerde reeks.
Waarom is dit nodig? Analyse met behulp van hashfuncties wordt vaak gebruikt om de integriteit te verifiëren belangrijke bestanden besturingssysteem, belangrijke programma's, belangrijke gegevens. Controle kan naar behoefte of op regelmatige basis worden uitgevoerd.
Hoe wordt dit gedaan? Bepaal eerst de integriteit van welke bestanden moeten worden gemonitord. Voor elk bestand wordt de hashwaarde berekend met behulp van een speciaal algoritme en het resultaat wordt opgeslagen. Door benodigde tijd Er wordt een soortgelijke berekening gemaakt en de resultaten worden vergeleken. Als de waarden verschillen, is de informatie in het bestand gewijzigd.
Welke kenmerken moet een hashfunctie hebben?
- moet in staat zijn gegevensconversies van willekeurige naar vaste lengte uit te voeren;
- moet een open algoritme hebben zodat de cryptografische kracht ervan kan worden onderzocht;
- moet eenzijdig zijn, dat wil zeggen dat het wiskundig niet mogelijk moet zijn om de initiële gegevens te bepalen op basis van het resultaat;
- moet botsingen ‘weerstaan’, dat wil zeggen dat het geen botsingen mag veroorzaken identieke waarden met verschillende invoergegevens;
- geen grote computerbronnen vereisen;
- bij de kleinste verandering in de invoergegevens zou het resultaat aanzienlijk moeten veranderen.
Wat zijn de populaire hash-algoritmen? Momenteel worden de volgende hashfuncties gebruikt:
- CRC – cyclische redundantiecode of controlesom. Het algoritme is heel eenvoudig, dat is zo groot aantal variaties afhankelijk van de vereiste uitvoerlengte. Niet cryptografisch!
- MD 5 is een zeer populair algoritme. Zoals hij vorige versie MD4 wel cryptografische functie. De hashgrootte is 128 bits.
- SHA -1 is ook een zeer populaire cryptografische functie. De hashgrootte is 160 bits.
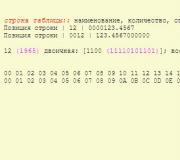
- GOST R 34.11-94 is een Russische cryptografische standaard voor hashfunctieberekeningen. De hashgrootte is 256 bits.
Wanneer kan een systeembeheerder deze algoritmen gebruiken? Vaak wordt bij het downloaden van inhoud, zoals programma's van de website van de fabrikant, muziek, films of andere informatie de waarde verlaagd controlesommen, berekend met behulp van een specifiek algoritme. Om veiligheidsredenen moet u na het downloaden zelfstandig de hashfunctie berekenen en de waarde vergelijken met wat op de website of in de bijlage bij het bestand staat aangegeven. Heb je dit ooit gedaan?
Wat is handiger om een hash te berekenen? Nu zijn er een groot aantal vergelijkbare hulpprogramma's, zowel betaald als gratis voor gebruik. Persoonlijk vond ik HashTab leuk. Ten eerste is het hulpprogramma tijdens de installatie ingebouwd als een tabblad in de bestandseigenschappen, ten tweede kunt u een groot aantal hash-algoritmen selecteren en ten derde is het gratis voor particulier, niet-commercieel gebruik.
Wat is Russisch? Zoals hierboven vermeld, bestaat er in Rusland een hash-standaard GOST R 34.11-94, die op grote schaal wordt gebruikt door veel fabrikanten van informatiebeveiligingstools. Eén van deze hulpmiddelen is het fixatie- en controleprogramma initiële staat softwarepakket"REPAREREN". Dit programma is een middel om de effectiviteit van de inzet van informatiebeveiliging te monitoren.

FIX (versie 2.0.1) voor Windows 9x/NT/2000/XP
- Berekening van controlesommen van gespecificeerde bestanden met behulp van een van de 5 geïmplementeerde algoritmen.
- Fixatie en daaropvolgende monitoring van de initiële staat van het softwarepakket.
- Vergelijking van softwarepakketversies.
- Fixatie en controle van mappen.
- Controle van veranderingen in gespecificeerde bestanden(catalogi).
- Rapporten genereren in TXT-formaten, HTML, SV.
- Het product heeft FSTEC-certificaat volgens NDV 3 nr. 913 tot 1 juni 2013
Hoe zit het met de digitale handtekening? Het resultaat van de hashfunctieberekening gaat samen met de geheime sleutel van de gebruiker naar de invoer cryptografisch algoritme, waar het wordt berekend elektronische digitale handtekening. Strikt genomen maakt de hashfunctie geen deel uit van het digitale handtekeningalgoritme, maar vaak wordt dit met opzet gedaan om een aanval met een publieke sleutel uit te sluiten.
Momenteel veel toepassingen e-commerce kunt u de geheime sleutel van de gebruiker opslaan in een privé-tokengebied (ruToken, eToken) zonder technische haalbaarheid om het daar weg te krijgen. Het token zelf heeft een zeer beperkt geheugengebied, gemeten in kilobytes. Om een document te ondertekenen, is er geen manier om het document naar het token zelf over te brengen, maar het is heel eenvoudig om de hash van het document naar het token over te brengen en bij de uitvoer een elektronische digitale handtekening te ontvangen.
In dit artikel vertel ik het je wat is hasj, waarom het nodig is, waar en hoe het wordt gebruikt, evenals de bekendste voorbeelden.
Veel taken op het gebied van de informatietechnologie zijn van groot belang voor de datavolumes. Als u bijvoorbeeld twee bestanden van 1 KB en twee bestanden van 10 GB moet vergelijken, dan is dit volledig verschillende tijden. Daarom wordt aangenomen dat er veel vraag is naar algoritmen waarmee u met kortere en ruimere waarden kunt werken.
Eén van deze technologieën is Hashing, dat zijn toepassing heeft gevonden bij het oplossen van veel problemen. Maar ik denk dat je als gewone gebruiker nog steeds niet begrijpt wat voor dier dit is en waarvoor het nodig is. Daarom zal ik verder proberen alles in de eenvoudigste woorden uit te leggen.
Opmerking: Het materiaal is ontworpen voor gewone gebruikers en bevat niet veel technische aspecten, maar het is meer dan voldoende voor basiskennis.
Wat is hash of hashing?

Ik zal beginnen met de voorwaarden.
Hash-functie, convolutiefunctie- Dit speciaal soort een functie waarmee u teksten van willekeurige lengte kunt converteren naar een code met een vaste lengte (meestal een korte alfanumerieke notatie).
Hashing- dit is het proces van het converteren van bronteksten.
Hash, Hash-code, Hash-waarde, Hash-som is de uitvoerwaarde van de hashfunctie, dat wil zeggen dat het resulterende blok een vaste lengte heeft.
Zoals je kunt zien, hebben de termen een enigszins figuurlijke omschrijving, waaruit moeilijk te begrijpen is waarom dit allemaal nodig is. Dus ik geef het meteen klein voorbeeld(Ik zal je later over andere toepassingen vertellen). Stel dat u 2 bestanden van 10 GB groot heeft. Hoe kom je er snel achter welke gelijk heeft? U kunt de bestandsnaam gebruiken, maar u kunt deze eenvoudig hernoemen. U kunt de datums bekijken, maar na het kopiëren van de bestanden kunnen de datums hetzelfde zijn of in een andere volgorde. De grootte kan, zoals u begrijpt, niet veel helpen (vooral als de grootten hetzelfde zijn of als u niet naar de exacte bytewaarden hebt gekeken).
Dit is waar juist deze Hash nodig is, wat een kort blok is dat is gevormd uit de brontekst van het bestand. Deze twee bestanden van 10 GB hebben twee verschillende maar korte hashcodes (zoiets als "ACCAC43535" en "BBB3232A42"). Als u ze gebruikt, kunt u er snel achter komen vereiste bestand, zelfs na het kopiëren en wijzigen van namen.
Opmerking: Omdat Hash een zeer bekend begrip is in de computerwereld en op internet, wordt vaak alles wat met Hash te maken heeft, tot dit woord afgekort. De zinsnede “Ik gebruik MD5-hash” betekent bijvoorbeeld dat de website of ergens anders het MD5-standaard hash-algoritme gebruikt.
Eigenschappen van hashfuncties
Nu zal ik u vertellen over de eigenschappen van hashfuncties, zodat u gemakkelijker kunt begrijpen waar hashing wordt gebruikt en waarom dit nodig is. Maar eerst nog een definitie.
Botsing- dit is een situatie voor twee verschillende teksten het resultaat is dezelfde hashsom. Zoals u begrijpt, heeft een blok een vaste lengte en dus een beperkt aantal mogelijke waarden, en daarom zijn herhalingen mogelijk.
En nu naar de eigenschappen van Hash-functies zelf:
1. Tekst van elke grootte kan worden ingevoerd en de uitvoer is een datablok met een vaste lengte. Dit volgt uit de definitie.
2. De hashsom van dezelfde teksten moet hetzelfde zijn. Anders zijn dergelijke functies eenvoudigweg nutteloos - het lijkt op een willekeurig getal.
3. Goede eigenschap de convolutie moet een goede verdeling hebben. Ben het ermee eens dat als de grootte van de uitvoerhash bijvoorbeeld 16 bytes is, de functie slechts 3 retourneert verschillende betekenissen voor welke tekst dan ook, dan heeft zo'n functie en deze 16 bytes geen nut (16 bytes zijn 2^128 opties, wat ongeveer gelijk is aan 3,4 * 10^38 graden).
4. Hoe goed de functie reageert op de kleinste veranderingen in de brontekst. Een eenvoudig voorbeeld. We hebben 1 letter gewijzigd in een bestand van 10 GB, de waarde van de functie zou anders moeten worden. Als dit niet het geval is, is het gebruik van een dergelijke functie zeer problematisch.
5. Waarschijnlijkheid van een botsing. Een zeer complexe parameter die onder bepaalde omstandigheden wordt berekend. Maar de essentie ervan is dat wat het nut is van een Hash-functie als de resulterende Hash-som vaak zal samenvallen.
6. Snelheid van hashberekening. Wat is het nut van een convolutiefunctie als het berekenen ervan lang duurt? Geen, want dan is het makkelijker om bestandsgegevens te vergelijken of een andere aanpak te gebruiken.
7. Moeilijkheden bij het herstellen van de originele gegevens op basis van de hashwaarde. Dit kenmerk is specifieker dan algemeen, omdat dit niet overal vereist is. Voor de meest bekende algoritmen wordt dit kenmerk echter geschat. Bijvoorbeeld, bronbestand Het is onwaarschijnlijk dat u iets uit deze functie haalt. Als er echter sprake is van een botsingsprobleem (u moet bijvoorbeeld elke tekst vinden die overeenkomt met een dergelijke hash), dan kan een dergelijk kenmerk belangrijk zijn. Bijvoorbeeld wachtwoorden, maar daarover later meer.
8. Open of gesloten broncode zo'n functie. Als de code niet open is, blijft de complexiteit van dataherstel, namelijk de cryptografische sterkte, twijfelachtig. Voor een deel is dit een probleem met encryptie.
Nu kunnen we verder gaan met de vraag: “Waar is dit allemaal voor?”
Waarom is hasj nodig?
Hash-functies hebben slechts drie hoofddoelen (of beter gezegd: hun doeleinden).
1. Controle van de gegevensintegriteit. IN in dit geval alles is eenvoudig, een dergelijke functie moet snel worden berekend en u in staat stellen snel te controleren of bijvoorbeeld een van internet gedownload bestand tijdens de verzending niet is beschadigd.
2. Verhoogde snelheid voor het ophalen van gegevens. Vaste maat block biedt u veel voordelen bij het oplossen van zoekproblemen. In dit geval waar we het over hebben dat, puur technisch gezien, het gebruik van hashfuncties een positief effect kan hebben op de prestaties. Voor dergelijke functies is het erg belangrijk vertegenwoordigen de waarschijnlijkheid van botsingen en een goede verdeling.
3. Voor cryptografische behoeften. Dit type convolutiefuncties worden gebruikt in die veiligheidsgebieden waar het belangrijk is dat de resultaten moeilijk te vervangen zijn of waar het nodig is om de taak van het verkrijgen zo moeilijk mogelijk te maken nuttige informatie van Hasj.
Waar en hoe wordt hasj gebruikt?
Zoals je waarschijnlijk al geraden hebt, wordt hasj gebruikt om veel problemen op te lossen. Hier zijn er een paar:
1. Wachtwoorden worden meestal niet opgeslagen in open vorm, maar dan in de vorm van Hash-sommen, waardoor je meer kunt geven hoge graad beveiliging. Zelfs als een aanvaller toegang krijgt tot zo’n database, zal hij immers nog veel tijd moeten besteden aan het vinden van de juiste teksten voor deze Hash Codes. Dit is waar de karakteristieke “moeilijkheid om de originele gegevens uit de hash-waarden te herstellen” belangrijk is.
Opmerking: Ik raad u aan het artikel te lezen: een paar tips om het niveau van wachtwoordbeveiliging te verhogen.
2. Bij programmeren, inclusief databases. Natuurlijk hebben we het meestal over datastructuren die dit mogelijk maken snel zoeken. Puur technisch aspect.
3. Bij het verzenden van gegevens via een netwerk (inclusief internet). Veel protocollen, zoals TCP/IP, bevatten speciale controlevelden die de hashsom bevatten origineel bericht zodat als er ergens een storing optreedt, dit geen invloed heeft op de dataoverdracht.
4. Voor verschillende algoritmen gerelateerd aan veiligheid. Hash wordt bijvoorbeeld gebruikt in elektronische digitale handtekeningen.
5. Om de integriteit van bestanden te controleren. Als je goed hebt opgelet, kun je vaak bestanden op internet vinden (bijvoorbeeld archieven) aanvullende beschrijvingen met hashcode. Deze maatregel wordt niet alleen gebruikt om ervoor te zorgen dat u niet per ongeluk een bestand start dat beschadigd is tijdens het downloaden van internet, maar er zijn ook eenvoudige hostingfouten. In dergelijke gevallen kunt u snel de hash controleren en, indien nodig, het bestand opnieuw uploaden.
6. Soms worden hash-functies gebruikt om te creëren unieke identificatiegegevens(als onderdeel). Bij het opslaan van bijvoorbeeld afbeeldingen of alleen bestanden gebruiken ze meestal een hash in de namen, samen met de datum en tijd. Hiermee kunt u voorkomen dat bestanden met dezelfde naam worden overschreven.
Hoe verder je gaat, hoe vaker Hash-functies worden gebruikt informatietechnologie. Voornamelijk vanwege het feit dat de datavolumes en kracht het grootst zijn eenvoudige computers zijn veel gegroeid. In het eerste geval hebben we het meer over zoeken, en in het tweede geval hebben we het meer over beveiligingskwesties.
Beroemde hashfuncties
De volgende drie hashfuncties worden als de meest bekende beschouwd.
Vaak zegt de beschrijving bij het downloaden van torrents of de bestanden zelf iets als “ad33e486d0578a892b8vbd8b19e28754” (bijvoorbeeld in ex.ua), vaak met het voorvoegsel “md5”. Dit is de hashcode - het resultaat dat de hashfunctie produceert na het verwerken van de binnenkomende gegevens. Vertaald uit het Engels betekent hasj een puinhoop, marihuana, wiet of een gerecht van fijngehakt vlees en groenten. heel, heel moeilijk, je zou bijna onmogelijk kunnen zeggen. Dan rijst de vraag: "Waarom is dit allemaal überhaupt nodig?" Over dit en we zullen praten in dit artikel.
Wat is een hashfunctie en hoe werkt deze?
Deze functie is ontworpen om binnenkomende gegevens naar wens te transformeren groot formaat waardoor een vaste lengte ontstaat. Het proces van een dergelijke conversie wordt hashing genoemd en het resultaat is een hash of hash-code. Soms worden ook de woorden ‘vingerafdruk’ of ‘berichtoverzicht’ gebruikt, maar in de praktijk komen ze veel minder vaak voor. Er zijn veel verschillende algoritmen waarmee je een data-array kunt omzetten in een bepaalde reeks tekens van een bepaalde lengte. Het meest gebruikte algoritme heet md5 en werd in 1991 ontwikkeld. Ondanks het feit dat md5 tegenwoordig enigszins verouderd is en niet wordt aanbevolen voor gebruik, wordt het nog steeds gebruikt en vaak schrijven sites in plaats van het woord ‘hashcode’ gewoon md5 en geven de code zelf aan.
Waarom is een hashfunctie nodig?

Als je het resultaat kent, is het bijna onmogelijk om de invoergegevens te bepalen, maar dezelfde invoergegevens geven hetzelfde resultaat. Daarom wordt vaak een hashfunctie (ook wel convolutiefunctie genoemd) gebruikt om zeer belangrijke informatie, zoals wachtwoord, login, identiteitsnummer en andere persoonlijke informatie. In plaats van de informatie die de gebruiker invoert te vergelijken met wat er in de database is opgeslagen, worden hun hashes vergeleken. Dit zorgt ervoor dat in het geval van een onbedoeld informatielek niemand belangrijke gegevens voor eigen doeleinden kan gebruiken. Door de hashcode te vergelijken, is het ook handig om te controleren of bestanden correct van internet worden gedownload, vooral als er tijdens het downloaden verbindingsonderbrekingen zijn geweest.
Hashfuncties: wat zijn dat? T

Afhankelijk van het doel kan een hashfunctie uit drie typen bestaan:
1. Functie voor het controleren van de integriteit van informatie
Wanneer dit via het netwerk gebeurt, wordt een hash van het pakket berekend, en dit resultaat wordt ook samen met het bestand verzonden. Bij ontvangst wordt de hashcode opnieuw berekend en vergeleken met de via het netwerk ontvangen waarde. Als de code niet overeenkomt, duidt dit op fouten en wordt het beschadigde pakket opnieuw verzonden. Zo'n functie hoge snelheid berekening, maar een klein aantal hashwaarden en slechte stabiliteit. Een voorbeeld van dit type: CRC32, dat slechts 232 verschillende waarden heeft.
2. Cryptografische functie
Gebruikt voor bescherming tegen (ND). Hiermee kunt u controleren of er gegevensbeschadiging is opgetreden als gevolg van een ongeluk tijdens de bestandsoverdracht via het netwerk. De echte hash is in dit geval openbaar beschikbaar en de hash van het resulterende bestand kan worden berekend met behulp van de set verschillende programma's. Dergelijke functies hebben een lange en stabiele levensduur, en het zoeken naar botsingen (mogelijke samenvallende resultaten uit verschillende brongegevens) is erg moeilijk. Dit zijn de functies die worden gebruikt om wachtwoorden (SH1, SH2, MD5) en andere waardevolle informatie in de database op te slaan.
3. Een functie die is ontworpen om een efficiënte datastructuur te creëren
Het doel is een compacte en redelijk ordelijke organisatie van informatie in een speciale structuur die een hashtabel wordt genoemd. Met deze tabel kunt u toevoegen nieuwe informatie, verwijder informatie en zoek met zeer hoge snelheid naar de gewenste gegevens.
String-hashing-algoritmen helpen veel problemen op te lossen. Maar ze hebben een groot nadeel: dat ze meestal niet 100% correct zijn, omdat er veel strings zijn waarvan de hashes hetzelfde zijn. Een ander ding is dat je dit bij de meeste problemen kunt negeren, omdat de kans op het matchen van hashes nog steeds erg laag is.
Hash-definitie en berekening
Een van de beste manieren definieer een hashfunctie uit string S als volgt:
H(S) = S + S * P + S * P^2 + S * P^3 + ... + S[N] * P^N
waarbij P een getal is.
Het is redelijk om voor P een priemgetal te kiezen dat ongeveer gelijk is aan het aantal tekens in het invoeralfabet. Als bijvoorbeeld wordt aangenomen dat de strings alleen uit kleine strings bestaan Latijnse letters, Dat goede keuze zal P = 31 zijn. Als letters zowel hoofdletters als kleine letters kunnen zijn, dan is bijvoorbeeld P = 53.
Alle code in dit artikel gebruikt P = 31.
Het is raadzaam om de hashwaarde zelf in de grootste op te slaan numeriek type- int64, ook bekend als lang lang. Het is duidelijk dat wanneer de tekenreekslengte ongeveer 20 tekens bedraagt, er al waardeoverloop zal optreden. Sleutelpunt- dat we geen aandacht besteden aan deze overflows, alsof we een hash modulo 2^64 nemen.
Een voorbeeld van hashberekening als alleen kleine Latijnse letters zijn toegestaan:
Const int p = 31; lange lange hash = 0, p_pow = 1; voor (grootte_t i=0; i Bij de meeste problemen is het zinvol om eerst alle noodzakelijke machten van P in een array te berekenen. We zijn nu in staat dit probleem effectief op te lossen. Gegeven een lijst met strings S, elk niet langer dan M tekens lang. Stel dat u alle dubbele tekenreeksen wilt vinden en deze in groepen wilt verdelen, zodat elke groep alleen identieke tekenreeksen bevat. Met normale stringsortering zouden we een algoritme krijgen met een complexiteit van O(NM log N), terwijl we met hashes O(N M + N log N) zouden krijgen. Algoritme. Laten we de hash van elke regel berekenen en de regels op deze hash sorteren. Vector Stel dat we een string S krijgen, en de indices I en J. We moeten de hash van de substring S vinden. Per definitie hebben we: H = S[I] + S * P + S * P^2 + ... + S[J] * P^(J-I) H * P[I] = S[I] * P[I] + ... + S[J] * P[J], H * P[I] = H - H De resulterende eigenschap is erg belangrijk. Dat blijkt inderdaad zo te zijn Omdat we alleen de hashes van alle voorvoegsels van een string S kennen, kunnen we de hash van elke substring in O(1) verkrijgen. Het enige probleem dat zich voordoet is dat je moet kunnen delen door P[I]. Eigenlijk is het niet zo eenvoudig. Omdat we een hash modulo 2^64 berekenen, moeten we, om te delen door P[I], het inverse element ervan in het veld vinden (bijvoorbeeld met behulp van het uitgebreide Euclidische algoritme), en vermenigvuldigen met dit inverse element. Er is echter een gemakkelijkere manier. In de meeste gevallen in plaats van hashes te delen door machten van P, kun je ze integendeel vermenigvuldigen met deze machten. Laten we zeggen dat er twee hashes worden gegeven: de ene vermenigvuldigd met P[I] en de andere met P[J]. Als ik< J, то умножим перый хэш на P, иначе же умножим второй хэш на P. Теперь мы привели хэши к одной степени, и можем их спокойно сравнивать. Code die bijvoorbeeld hashes van alle voorvoegsels berekent en vervolgens twee subtekenreeksen in O(1) vergelijkt: String s; int i1, i2, len; // invoergegevens // tel alle machten p const int p = 31; vector Hier zijn enkele typische toepassingen van hashing: Laat een string S met lengte N gegeven worden, die alleen uit kleine Latijnse letters bestaat. U moet het aantal verschillende subtekenreeksen in deze tekenreeks vinden. Om dit op te lossen, nemen we de lengte van de subtekenreeks één voor één: L = 1 .. N. Voor elke L zullen we een array van hashes van substrings met lengte L bouwen, de hashes in dezelfde mate reduceren, en deze array sorteren. We voegen het aantal verschillende elementen in deze array toe aan het antwoord. Uitvoering: String s; // invoerreeks int n = (int) s.length(); // tel alle machten van p const int p = 31; vector Voorbeeld taak. Identieke strings zoeken
Substring-hash en de snelle berekening ervan
Hashen gebruiken
Bepalen van het aantal verschillende substrings