Voorbeelden van SQL-query's naar de MySQL-database. Speciale instructies en aanbiedingen
Hoe kom ik erachter hoeveel pc-modellen een bepaalde leverancier heeft geproduceerd? Hoe u de gemiddelde prijs kunt bepalen van computers die hetzelfde hebben specificaties? Op deze en vele andere vragen die met sommigen verband houden statistische informatie, kunt u antwoorden krijgen met behulp van laatste (geaggregeerde) functies. De standaard biedt de volgende aggregatiefuncties:
Al deze functies retourneren één enkele waarde. Tegelijkertijd de functies AANTAL, MIN En MAX toepasbaar op elk gegevenstype, while SOM En AVG worden alleen gebruikt voor numerieke velden. Verschil tussen functie GRAAF(*) En GRAAF(<имя поля>) is dat de tweede bij de berekening geen rekening houdt met NULL-waarden.
Voorbeeld. Zoek het minimum en maximale prijs naar personal computers:
Voorbeeld. Zoek het beschikbare aantal computers geproduceerd door fabrikant A:
Voorbeeld. Als we geïnteresseerd zijn in de hoeveelheid diverse modellen, geproduceerd door fabrikant A, kan de vraag als volgt worden geformuleerd (gebruik makend van het feit dat in de Producttabel elk model één keer wordt vastgelegd):
Voorbeeld. Zoek het aantal beschikbare verschillende modellen geproduceerd door fabrikant A. De zoekopdracht is vergelijkbaar met de vorige, waarin het nodig was om het totale aantal modellen te bepalen geproduceerd door fabrikant A. Hier moet u ook het aantal verschillende modellen vinden in de pc-tafel (dat wil zeggen, die beschikbaar zijn voor verkoop).
Om ervoor te zorgen dat alleen unieke waarden worden gebruikt bij het verkrijgen van statistische indicatoren, wanneer argument van aggregatiefuncties kan worden gebruikt DISTINCT-parameter. Een andere parameter ALLES is de standaard en gaat ervan uit dat alle geretourneerde waarden in de kolom worden geteld. Exploitant,
Als we het aantal geproduceerde pc-modellen willen weten iedereen fabrikant, die u moet gebruiken GROUP BY-clausule, syntactisch volgend WHERE-clausules.
GROUP BY-clausule
GROUP BY-clausule gebruikt om groepen uitvoerregels te definiëren waarop kan worden toegepast aggregatiefuncties (COUNT, MIN, MAX, AVG en SUM). Als deze clausule ontbreekt en er aggregatiefuncties worden gebruikt, worden alle kolommen met namen vermeld in SELECTEER, moet worden opgenomen geaggregeerde functies, en deze functies worden toegepast op de volledige set rijen die voldoen aan het querypredikaat. Anders alle kolommen van de SELECT-lijst niet inbegrepen in totaal moeten functies worden gespecificeerd in de GROUP BY-clausule. Als gevolg hiervan zijn alle uitvoerqueryrijen verdeeld in groepen die worden gekenmerkt door dezelfde combinaties van waarden in deze kolommen. Hierna worden aggregatiefuncties op elke groep toegepast. Houd er rekening mee dat voor GROUP BY alles geldt NULL-waarden worden als gelijk behandeld, d.w.z. bij het groeperen op een veld dat NULL-waarden bevat, vallen al dergelijke rijen in één groep.Als als er een GROUP BY-clausule aanwezig is, in de SELECT-clausule geen geaggregeerde functies, dan retourneert de query eenvoudigweg één rij uit elke groep. Deze functie kan, samen met het trefwoord DISTINCT, worden gebruikt om dubbele rijen in een resultatenset te elimineren.
Laten we een eenvoudig voorbeeld bekijken:
| SELECTEER model, COUNT(model) AS Aantal_model, AVG(prijs) AS Gem._prijs VANAF PC GROEP OP model; |
In dit verzoek wordt voor elk pc-model het aantal bepaald en gemiddelde kosten. Alle lijnen met dezelfde waarden model (modelnummer) vormen een groep, en de SELECT-uitvoer berekent het aantal waarden en de gemiddelde prijswaarden voor elke groep. Het resultaat van de query is de volgende tabel:
| model | Aantal_model | Gem._prijs |
| 1121 | 3 | 850.0 |
| 1232 | 4 | 425.0 |
| 1233 | 3 | 843.33333333333337 |
| 1260 | 1 | 350.0 |
Als de SELECT een datumkolom zou hebben, zou het mogelijk zijn om deze indicatoren voor elke specifieke datum te berekenen. Om dit te doen, moet u datum toevoegen als groeperingskolom, waarna de aggregatiefuncties worden berekend voor elke combinatie van waarden (modeldatum).
Er zijn verschillende specifieke regels voor het uitvoeren van aggregatiefuncties:
- Indien als gevolg van het verzoek geen rijen ontvangen(of meer dan één rij voor een bepaalde groep), dan zijn er geen brongegevens voor het berekenen van de aggregatiefuncties. In dit geval is het resultaat van de COUNT-functies nul en is het resultaat van alle andere functies NULL.
- Argument geaggregeerde functie kan zelf geen aggregatiefuncties bevatten(functie van functie). Die. in één zoekopdracht is het bijvoorbeeld onmogelijk om het maximum aan gemiddelde waarden te verkrijgen.
- Het resultaat van het uitvoeren van de COUNT-functie is geheel getal(GEHEEL GETAL). Andere aggregatiefuncties erven de gegevenstypen van de waarden die ze verwerken.
- Als de SOM-functie een resultaat oplevert dat groter is dan de maximale waarde van het gebruikte gegevenstype, fout.
Dus als het verzoek niet bevat GROUP BY-clausules, Dat geaggregeerde functies inbegrepen SELECT-clausule, worden uitgevoerd op alle resulterende queryrijen. Als het verzoek bevat GROUP BY-clausule, elke set rijen die dezelfde waarden heeft van een kolom of groep kolommen die is opgegeven in GROUP BY-clausule, vormt een groep, en geaggregeerde functies worden voor elke groep afzonderlijk uitgevoerd.
AANBIEDING HEBBEN
Als WHERE-clausule definieert vervolgens een predikaat voor het filteren van rijen AANBIEDING HEBBEN is van toepassing na groepering om een soortgelijk predikaat te definiëren dat groepen op waarden filtert geaggregeerde functies. Deze clausule is nodig om de waarden te valideren die worden verkregen met behulp van geaggregeerde functie niet uit individuele rijen van de recordbron gedefinieerd in FROM-clausule, en van groepen van dergelijke lijnen. Een dergelijke controle kan daarom niet worden opgenomen WHERE-clausule.
Elke webontwikkelaar moet SQL kennen om databasequery's te schrijven. En hoewel phpMyAdmin niet is geannuleerd, is het vaak nodig om je handen vuil te maken om SQL op laag niveau te schrijven.
Daarom hebben wij ons voorbereid korte excursie Door SQL-basisprincipes. Laten we beginnen!
1. Maak een tabel
De instructie CREATE TABLE wordt gebruikt om tabellen te maken. De argumenten moeten de namen van de kolommen zijn, evenals hun gegevenstypen.
Laten we een eenvoudige tabel maken met de naam maand. Het bestaat uit 3 kolommen:
- ID kaart– Maandnummer in het kalenderjaar (geheel getal).
- naam– Maandnaam (string, maximaal 10 tekens).
- dagen– Aantal dagen in deze maand (geheel getal).
Dit is hoe de overeenkomstige eruit zal zien SQL-query:
MAAK TABEL maanden (id int, naam varchar(10), dagen int);
Ook bij het maken van tabellen is het raadzaam om toe te voegen hoofdsleutel voor een van de kolommen. Hierdoor blijven de records uniek en worden ophaalverzoeken versneld. Laat in ons geval de naam van de maand uniek zijn (kolom naam)
MAAK TABEL maanden (id int, naam varchar(10), dagen int, PRIMAIRE SLEUTEL (naam));
| Data type | Beschrijving |
|---|---|
| DATUM | Datumwaarden |
| DATUM TIJD | Datum- en tijdwaarden zijn tot op de minuut nauwkeurig |
| TIJD | Tijd waarden |
2. Rijen invoegen
Laten we nu onze tabel invullen maanden bruikbare informatie. Het toevoegen van records aan een tabel gebeurt met behulp van de INSERT-instructie. Er zijn twee manieren om deze instructie te schrijven.
De eerste methode is om niet de namen op te geven van de kolommen waarin de gegevens zullen worden ingevoegd, maar om alleen de waarden op te geven.
Deze opnamemethode is eenvoudig, maar onveilig, omdat er geen garantie is dat naarmate het project zich uitbreidt en de tabel wordt bewerkt, de kolommen in dezelfde volgorde zullen staan als voorheen. Een veilige (en tegelijkertijd omslachtiger) manier om een INSERT-instructie te schrijven vereist het specificeren van zowel de waarden als de volgorde van de kolommen:
Hier is de eerste waarde in de lijst WAARDEN komt overeen met de eerste de opgegeven naam kolom, enz.
3. Gegevens uit tabellen extraheren
De SELECT-instructie is van ons beste vriend wanneer we gegevens uit de database willen halen. Het wordt heel vaak gebruikt, dus let goed op dit gedeelte.
Het eenvoudigste gebruik van de SELECT-instructie is een query die alle kolommen en rijen uit een tabel retourneert (bijvoorbeeld tabellen op naam karakters):
SELECTEER * UIT "tekens"
Het asterisk (*)-symbool betekent dat we gegevens uit alle kolommen willen halen. Basis dus SQL-gegevens meestal uit meer dan één tabel bestaan, moet het sleutelwoord FROM worden opgegeven, gevolgd door de tabelnaam, gescheiden door een spatie.
Soms willen we geen gegevens uit niet alle kolommen in een tabel halen. Om dit te doen, moeten we in plaats van een asterisk (*) de namen van de gewenste kolommen opschrijven, gescheiden door komma's.
SELECT id, naam FROM maand
Bovendien willen we in veel gevallen dat de resulterende resultaten worden gesorteerd in een bepaalde volgorde. In SQL doen we dit met met behulp van BESTELLING DOOR . Het kan een optionele modifier accepteren: ASC (standaard) sorteren in oplopende volgorde of DESC, sorteren in aflopende volgorde:
SELECTEER id, naam VANAF maand BESTEL OP naam OMSCH
Wanneer u ORDER BY gebruikt, zorg er dan voor dat deze als laatste komt in de SELECT-instructie. Anders wordt er een foutmelding weergegeven.
4. Gegevensfiltering
Je hebt geleerd hoe je kunt selecteren uit een database met met behulp van SQL strikt gedefinieerde kolommen opvragen, maar wat als we ook specifieke rijen nodig hebben? De WHERE-clausule komt hier te hulp, waardoor we de gegevens kunnen filteren afhankelijk van de voorwaarde.
In deze zoekopdracht selecteren we alleen die maanden uit de tabel maand, waarin er meer dan 30 dagen zijn waarbij de operator groter dan (>) wordt gebruikt.
SELECTEER id, naam VAN maand WAAR dagen > 30
5. Geavanceerde gegevensfiltering. EN- en OF-operatoren
Voorheen gebruikten we gegevensfiltering op basis van één enkel criterium. Voor complexere gegevensfiltering kunt u de AND- en OR-operatoren en vergelijkingsoperatoren (=,<,>,<=,>=,<>).
Hier hebben we een tabel met de vier best verkochte albums aller tijden. Laten we degenen kiezen die als rock zijn geclassificeerd en waarvan minder dan 50 miljoen exemplaren zijn verkocht. Dit kan eenvoudig worden gedaan door een AND-operator tussen deze twee voorwaarden te plaatsen.
 SELECTEER * UIT albums WAAR genre = "rock" EN sales_in_millions<= 50
ORDER BY released
SELECTEER * UIT albums WAAR genre = "rock" EN sales_in_millions<= 50
ORDER BY released
6. In/tussen/vind ik leuk
WHERE ondersteunt ook verschillende speciale commando's, waardoor u snel de meest gebruikte zoekopdrachten kunt controleren. Daar zijn ze:
- IN – dient om een reeks voorwaarden aan te geven, waaraan aan alle voorwaarden kan worden voldaan
- BETWEEN – controleert of een waarde binnen het opgegeven bereik ligt
- LIKE – zoekt naar specifieke patronen
Als we bijvoorbeeld albums willen selecteren met knal En ziel muziek, kunnen we IN("value1","value2") gebruiken.
SELECTEER * UIT albums WAAR genre IN ("pop", "soul");
Als we alle albums willen hebben die tussen 1975 en 1985 zijn uitgebracht, moeten we schrijven:
SELECTEER * UIT albums WAAR uitgebracht tussen 1975 en 1985;
7. Functies
SQL zit boordevol functies die allerlei nuttige dingen doen. Hier zijn enkele van de meest gebruikte:
- COUNT() – retourneert het aantal rijen
- SUM() – retourneert de totale som van een numerieke kolom
- AVG() – retourneert het gemiddelde van een reeks waarden
- MIN() / MAX() – Haalt de minimum-/maximumwaarde van een kolom op
Om het meest recente jaar in onze tabel te krijgen, moeten we de volgende SQL-query schrijven:
SELECT MAX(uitgebracht) FROM albums;
8. Subquery's
In de vorige paragraaf hebben we geleerd hoe we eenvoudige berekeningen met gegevens kunnen uitvoeren. Als we het resultaat van deze berekeningen willen gebruiken, kunnen we niet zonder geneste queries. Stel dat we willen uitvoeren artiest, album En jaar van uitgave voor het oudste album in de tabel.
We weten hoe we deze specifieke kolommen kunnen krijgen:
SELECTEER artiest, album, uitgebracht VAN albums;
We weten ook hoe we het vroegste jaar kunnen krijgen:
SELECT MIN (uitgebracht) FROM album;
Het enige dat nu nodig is, is om de twee query's te combineren met WHERE:
SELECTEER artiest,album,uitgebracht VAN albums WAAR uitgebracht = (SELECTEER MIN(uitgebracht) VAN albums);
9. Tabellen samenvoegen
In complexere databases zijn er meerdere tabellen die aan elkaar gerelateerd zijn. Hieronder staan bijvoorbeeld twee tabellen over videogames ( Computerspellen) en ontwikkelaars van videogames ( game_ontwikkelaars).


In de tafel Computerspellen er is een ontwikkelaarskolom ( ontwikkelaar_id), maar het bevat een geheel getal, niet de naam van de ontwikkelaar. Dit nummer vertegenwoordigt de identificatie ( ID kaart) van de overeenkomstige ontwikkelaar uit de tabel met game-ontwikkelaars ( game_ontwikkelaars), waarbij twee lijsten logisch aan elkaar worden gekoppeld, waardoor we de informatie die in beide lijsten is opgeslagen tegelijkertijd kunnen gebruiken.
Als we een query willen maken die alles retourneert wat we moeten weten over games, kunnen we een INNER JOIN gebruiken om kolommen uit beide tabellen te koppelen.
SELECTEER video_games.name, video_games.genre, game_developers.name, game_developers.country VAN video_games INNER JOIN game_developers AAN video_games.developer_id = game_developers.id;
Dit is het eenvoudigste en meest voorkomende JOIN-type. Er zijn verschillende andere opties, maar deze zijn van toepassing op minder vaak voorkomende gevallen.
10. Aliassen
Als u naar het vorige voorbeeld kijkt, zult u merken dat er twee kolommen worden genoemd naam. Dit is verwarrend, dus laten we een alias instellen voor een van de herhalende kolommen, zoals deze naam van de tafel game_ontwikkelaars zal gebeld worden ontwikkelaar.
We kunnen de query ook inkorten door de tabelnamen een alias te geven: Computerspellen laten we bellen spellen, game_ontwikkelaars - ontwikkelaars:
SELECT games.name, games.genre, devs.name AS ontwikkelaar, devs.country VAN video_games AS games INNER JOIN game_developers AS ontwikkelaars AAN games.developer_id = devs.id;
11. Gegevensupdate
Vaak moeten we de gegevens in sommige rijen wijzigen. In SQL gebeurt dit met behulp van de UPDATE-instructie. De UPDATE-verklaring bestaat uit:
- De tabel waarin de vervangingswaarde staat;
- Kolomnamen en hun nieuwe waarden;
- De rijen die zijn geselecteerd met WHERE en die we willen bijwerken. Als dit niet gebeurt, veranderen alle rijen in de tabel.
Hieronder vindt u de tabel TV series met tv-series en hun kijkcijfers. Er sloop echter een kleine fout in de tabel: hoewel de serie Game of Thrones en wordt beschreven als een komedie, maar dat is het echt niet. Laten we dit oplossen!
 Tabelgegevens tv_series UPDATE tv_series SET genre = "drama" WHERE id = 2;
Tabelgegevens tv_series UPDATE tv_series SET genre = "drama" WHERE id = 2; 12. Gegevens verwijderen
Het verwijderen van een tabelrij met behulp van SQL is een heel eenvoudig proces. Het enige dat u hoeft te doen, is de tabel en rij selecteren die u wilt verwijderen. Laten we de laatste rij in de tabel uit het vorige voorbeeld verwijderen TV series. Dit wordt gedaan met behulp van de >DELETE-instructie.
VERWIJDEREN UIT tv_serie WAAR id = 4
Wees voorzichtig bij het schrijven van de DELETE-instructie en zorg ervoor dat de WHERE-clausule aanwezig is, anders worden alle rijen in de tabel verwijderd!
13. Verwijder een tabel
Als we alle rijen willen verwijderen maar de tabel zelf willen verlaten, gebruik dan de opdracht TRUNCATE:
TRUNCATE TABLE tabelnaam;
In het geval dat we zowel de gegevens als de tabel zelf willen verwijderen, zal de DROP-opdracht nuttig voor ons zijn:
DROP TABLE tabelnaam;
Wees zeer voorzichtig met deze opdrachten. Ze kunnen niet worden geannuleerd!/p>
Dit is het einde van onze SQL-tutorial! Er is veel dat we nog niet hebben besproken, maar wat je al weet zou voldoende moeten zijn om je wat praktische vaardigheden te geven voor je webcarrière.
Query's worden sindsdien zonder escape-aanhalingstekens geschreven MySQL, MS SQL En PostGree ze zijn verschillend.
SQL-query: de opgegeven (noodzakelijke) velden uit de tabel halen
SELECT id, country_title, count_people FROM tabelnaamWe krijgen een lijst met records: ALLE landen en hun bevolking. De namen van de verplichte velden worden aangegeven, gescheiden door komma's.
SELECT * FROM tabelnaam
* geeft alle velden aan. Dat wil zeggen, er zullen shows zijn ALLES data velden.
SQL-query: records uit een tabel uitvoeren, exclusief duplicaten
SELECTEER DISTINCT landtitel VAN tabelnaamWe krijgen een lijst met records: landen waar onze gebruikers zich bevinden. Er kunnen veel gebruikers uit één land zijn. In dit geval is het uw verzoek.
SQL-query: records uit een tabel weergeven op basis van een bepaalde voorwaarde
SELECT id, country_title, city_title FROM tabelnaam WHERE count_people>100000000We krijgen een lijst met records: landen waar het aantal mensen meer dan 100.000.000 bedraagt.
SQL-query: records uit een tabel uitvoeren met volgorde
SELECTEER id, stadstitel UIT tabelnaam ORDER OP stadstitelWe krijgen een lijst met records: steden in alfabetische volgorde. Aan het begin A, aan het eind Z.
SELECTEER id, stadstitel UIT tabelnaam ORDER OP stadstitel DESC
We krijgen een lijst met records: steden in omgekeerde richting ( OMSCHRIJVING) Oké. Aan het begin I, aan het einde A.
SQL-query: het aantal records tellen
SELECTEER COUNT(*) FROM tabelnaamWe krijgen het aantal (aantal) records in de tabel. IN in dit geval GEEN lijst met vermeldingen.
SQL-query: het gewenste recordbereik wordt uitgevoerd
SELECT * FROM tabelnaam LIMIT 2, 3We halen 2 (tweede) en 3 (derde) records uit de tabel. De zoekopdracht is handig bij het maken van navigatie op WEB-pagina's.
SQL-query's met voorwaarden
Records uit een tabel weergeven door gegeven voorwaarde gebruik van logische operatoren.
SQL-query: AND-constructie
SELECT id, stadtitel VAN tabelnaam WAAR land = "Rusland" EN olie = 1We krijgen een lijst met records: steden uit Rusland EN toegang hebben tot olie. Wanneer moet u de operator gebruiken? EN, dan moeten beide voorwaarden overeenkomen.
SQL-query: OR-constructie
SELECT id, city_title FROM tabelnaam WHERE land = "Rusland" OF land = "VS"We krijgen een lijst met records: alle steden uit Rusland OF VERENIGDE STATEN VAN AMERIKA. Wanneer moet u de operator gebruiken? OF, dan moet TEN MINSTE één voorwaarde overeenkomen.
SQL-query: EN NIET constructie
SELECTEER id, user_login FROM tabelnaam WAAR land = "Rusland" EN NIET count_comments<7We krijgen een lijst met records: alle gebruikers uit Rusland EN wie maakte NIET MINDER 7 opmerkingen.
SQL-query: IN-constructie (B)
SELECT id, user_login FROM tabelnaam WHERE land IN ("Rusland", "Bulgarije", "China")We krijgen een lijst met records: alle gebruikers die in ( IN) (Rusland, of Bulgarije, of China)
SQL-query: NIET IN constructie
SELECT id, user_login FROM tabelnaam WHERE land NIET IN ("Rusland", "China")We krijgen een lijst met records: alle gebruikers die niet in ( NIET IN) (Rusland of China).
SQL-query: IS NULL-constructie (lege of NIET lege waarden)
SELECT id, user_login FROM tabelnaam WAAR de status NULL isWe krijgen een lijst met records: alle gebruikers waarvan de status niet is gedefinieerd. NULL is een apart issue en wordt daarom apart gecontroleerd.
SELECT id, user_login FROM tabelnaam WAAR de staat NIET NULL is
We krijgen een lijst met records: alle gebruikers waarvoor de status is gedefinieerd (NIET NULL).
SQL-query: LIKE-constructie
SELECT id, user_login FROM tabelnaam WAAR achternaam LIKE "Ivan%"We krijgen een lijst met records: gebruikers waarvan de achternaam begint met de combinatie “Ivan”. Het %-teken betekent ELK aantal ELK teken. Om het %-teken te vinden, moet je de escape “Ivan\%” gebruiken.
SQL-query: TUSSEN constructie
SELECT id, user_login FROM tabelnaam WAAR salaris TUSSEN 25000 EN 50000We krijgen een lijst met records: gebruikers die een salaris ontvangen van 25.000 tot en met 50.000.
Er zijn VEEL logische operatoren, dus bestudeer de SQL-serverdocumentatie in detail.
Complexe SQL-query's
SQL-query: het combineren van meerdere queries
(SELECT id, user_login FROM table_name1) UNION (SELECT id, user_login FROM table_name2)We krijgen een lijst met vermeldingen: gebruikers die in het systeem zijn geregistreerd, evenals gebruikers die afzonderlijk op het forum zijn geregistreerd. De UNION-operator kan meerdere query's combineren. UNION werkt als SELECT DISTINCT, dat wil zeggen dat dubbele waarden worden verwijderd. Om absoluut alle records te krijgen, moet u de UNION ALL-operator gebruiken.
SQL-query: veldwaarde telt MAX, MIN, SUM, AVG, COUNT
Eén maximale tellerwaarde weergeven in de tabel:
SELECT MAX(teller) FROM tabelnaamUitvoer van één, minimale tellerwaarde in de tabel:
SELECT MIN(teller) FROM tabelnaamDe som van alle tellerwaarden in de tabel weergeven:
SELECT SUM(teller) FROM tabelnaamWeergave van de gemiddelde tellerwaarde in de tabel:
SELECTEER AVG(teller) VAN tabelnaamHet aantal tellers in de tabel weergeven:
SELECT COUNT(teller) FROM tabelnaamWeergave van het aantal meters in werkplaats nr. 1 in de tabel:
SELECT COUNT(counter) FROM tabelnaam WHERE office="Werkplaats nr. 1"Dit zijn de populairste teams. Het wordt aanbevolen om, waar mogelijk, dit soort SQL-query's voor berekeningen te gebruiken, omdat geen enkele programmeeromgeving qua gegevensverwerkingssnelheid kan vergelijken met de SQL-server zelf bij het verwerken van zijn eigen gegevens.
SQL-query: records groeperen
SELECT continent, SUM(land_gebied) VAN land GROEP OP continentWe krijgen een lijst met records: met de naam van het continent en de som van de gebieden van al hun landen. Dat wil zeggen, als er een lijst is met landen waarin van elk land het gebied is vastgelegd, dan kunt u met behulp van de GROUP BY-constructie de omvang van elk continent achterhalen (gebaseerd op groepering op continenten).
SQL-query: meerdere tabellen gebruiken via alias
SELECT o.order_no, o.amount_paid, c.company FROM bestellingen AS o, klant AS met WAAR o.custno=c.custno AND c.city="Tyumen"We ontvangen een lijst met records: bestellingen van klanten die alleen in Tyumen wonen.
Met een goed ontworpen database van dit type komt de zoekopdracht zelfs het meest voor, dus werd er een speciale operator in MySQL geïntroduceerd die vele malen sneller werkt dan de hierboven geschreven code.
SELECT o.order_no, o.amount_paid, z.company FROM bestellingen AS o LINKS JOIN klant AS z ON (z.custno=o.custno)
Geneste subquery's
SELECT * FROM tabelnaam WHERE salaris=(SELECT MAX(salaris) FROM werknemer)We krijgen één record: informatie over de gebruiker met het maximale salaris.
Aandacht! Geneste subquery's zijn een van de grootste knelpunten in SQL-servers. Samen met hun flexibiliteit en kracht verhogen ze ook de belasting van de server aanzienlijk. Wat leidt tot een catastrofale vertraging voor andere gebruikers. Gevallen van recursieve aanroepen in geneste zoekopdrachten komen zeer vaak voor. Daarom raad ik ten zeerste aan om GEEN geneste query's te gebruiken, maar deze in kleinere query's op te splitsen. Of gebruik de hierboven beschreven LEFT JOIN-combinatie. Bovendien is dit type verzoek een verhoogde bron van beveiligingsschendingen. Als u besluit geneste subquery's te gebruiken, moet u deze zeer zorgvuldig ontwerpen en de eerste keer uitvoeren op kopieën van databases (testdatabases).
SQL-query's die gegevens wijzigen
SQL-query: INSERT
Instructies INVOEGEN Hiermee kunt u records in een tabel invoegen. In eenvoudige woorden: maak een rij met gegevens in een tabel.
Optie 1. De instructie die vaak wordt gebruikt is:
INSERT INTO tabelnaam (id, gebruiker_login) VALUES (1, "ivanov"), (2, "petrov")Naar de tafel " tafel naam"Er worden twee (twee) gebruikers tegelijk ingevoegd.
Optie 2. Het is handiger om de stijl te gebruiken:
INSERT tabelnaam SET id=1, user_login=”ivanov”; INSERT tabelnaam SET id=2, user_login=”petrov”;Dit heeft zijn voor- en nadelen.
Belangrijkste nadelen:
- Veel kleine SQL-query's worden iets langzamer uitgevoerd dan één grote SQL-query, maar andere query's staan in de wachtrij voor service. Dat wil zeggen: als het voltooien van een grote SQL-query 30 minuten duurt, zullen de resterende queries gedurende al die tijd bamboe roken en op hun beurt wachten.
- Het verzoek blijkt groter te zijn dan de vorige versie.
Belangrijkste voordelen:
- Bij kleine SQL-query's worden andere SQL-query's niet geblokkeerd.
- Gemakkelijk te lezen.
- Flexibiliteit. Bij deze optie hoeft u de structuur niet te volgen, maar hoeft u alleen de noodzakelijke gegevens toe te voegen.
- Wanneer u op deze manier archieven maakt, kunt u eenvoudig één regel kopiëren en deze via de opdrachtregel (console) uitvoeren, waardoor u niet het hele ARCHIEF herstelt.
- De schrijfstijl is vergelijkbaar met de UPDATE-verklaring, waardoor deze gemakkelijker te onthouden is.
SQL-query: UPDATE
UPDATE tabelnaam SET user_login="ivanov", gebruikersnaam_achternaam="Ivanov" WHERE id=1In de tafel " tafel naam"in de record met nummer id=1 worden de waarden van de velden user_login en user_surname gewijzigd in de opgegeven waarden.
SQL-query: DELETE
DELETE FROM tabelnaam WHERE id=3In tabel tabelnaam wordt het record met id-nummer 3 verwijderd.
- Het wordt aanbevolen om alle veldnamen in kleine letters te schrijven en, indien nodig, te scheiden met een geforceerde spatie “_” voor compatibiliteit met verschillende programmeertalen, zoals Delphi, Perl, Python en Ruby.
- Schrijf SQL-opdrachten in HOOFDLETTERS voor leesbaarheid. Onthoud altijd dat andere mensen de code na u kunnen lezen, en hoogstwaarschijnlijk ook u zelf na N tijd.
- Benoem de velden eerst met een zelfstandig naamwoord en daarna met een actie. Bijvoorbeeld: stadstatus, gebruiker_login, gebruikersnaam.
- Probeer reservewoorden in verschillende talen te vermijden die problemen kunnen veroorzaken in SQL, PHP of Perl, zoals (naam, aantal, link). Bijvoorbeeld: link kan gebruikt worden in MS SQL, maar is gereserveerd in MySQL.
Dit materiaal is een korte referentie voor het dagelijkse werk en pretendeert niet een super-mega-gezaghebbende bron te zijn, wat de originele bron is van SQL-query's van een bepaalde database.
- Vertaling
- Handleiding
Heeft u “SELECT * WHERE a=b FROM c” of “SELECT WHERE a=b FROM c ON *” nodig?
Als je net als ik bent, ben je het ermee eens: SQL is een van die dingen die op het eerste gezicht gemakkelijk lijken (leest als Engels!), maar op de een of andere manier moet je elke eenvoudige zoekopdracht Googlen om de juiste syntaxis te vinden.
En dan joins, aggregatie, subquery's beginnen, en het blijkt volkomen onzin te zijn. Iets zoals dit:
SELECT leden.voornaam || " " || Members.lastname AS "Volledige naam" FROM leningen INNER JOIN leden ON members.memberid=borrowings.memberid INNER JOIN boeken ON books.bookid=borrowings.bookid WHERE leningen.bookid IN (SELECT bookid FROM boeken WHERE stock>(SELECT avg(stock ) UIT boeken)) GROEPEREN OP leden.voornaam, leden.achternaam;
Bue! Dit zal elke nieuweling, of zelfs een ontwikkelaar op gemiddeld niveau, afschrikken als hij SQL voor de eerste keer ziet. Maar het is allemaal niet zo erg.
Het is gemakkelijk om te onthouden wat intuïtief is, en met deze gids hoop ik de drempel voor nieuwelingen om met SQL te beginnen te verlagen en degenen die al ervaring hebben een nieuwe manier te bieden om naar SQL te kijken.
Hoewel de SQL-syntaxis vrijwel hetzelfde is tussen verschillende databases, gebruikt dit artikel PostgreSQL voor query's. Sommige voorbeelden zullen werken in MySQL en andere databases.
1. Drie magische woorden
Er zijn veel trefwoorden in SQL, maar SELECT, FROM en WHERE zijn in bijna elke zoekopdracht aanwezig. Even later zult u begrijpen dat deze drie woorden de meest fundamentele aspecten vertegenwoordigen van het construeren van query's in de database, en dat andere woorden nog veel meer zijn complexe vragen, zijn slechts add-ons erbovenop.
2. Onze basis
Laten we eens kijken naar de database die we in dit artikel als voorbeeld zullen gebruiken:


We hebben boeken bibliotheek en mensen. Er is ook een speciale tafel voor het opnemen van uitgegeven boeken.
- In de tabel 'boeken' wordt informatie opgeslagen over de titel, auteur, publicatiedatum en beschikbaarheid van het boek. Het is makkelijk.
- In de tabel "leden" - de voor- en achternaam van alle mensen die zich hebben aangemeld voor de bibliotheek.
- In de tabel ‘leningen’ wordt informatie opgeslagen over boeken die uit de bibliotheek zijn gehaald. De kolom bookid verwijst naar de ID van het boek in de tabel 'boeken', en de kolom memberid verwijst naar de corresponderende persoon uit de tabel 'leden'. Ook hebben wij een uitgiftedatum en een datum waarop het boek geretourneerd moet worden.
3. Eenvoudig verzoek
Laten we beginnen met een eenvoudig verzoek: we hebben het nodig namen En identificatiegegevens(id) van alle boeken geschreven door de auteur “Dan Brown”
Het verzoek zal als volgt zijn:
SELECTEER bookid ALS "id", titel VAN boeken WAAR auteur="Dan Brown";
En het resultaat is als volgt:
| ID kaart | titel |
|---|---|
| 2 | Het verloren symbool |
| 4 | Inferno |
Redelijk makkelijk. Laten we naar het verzoek kijken om te begrijpen wat er aan de hand is.
3.1 VAN - waar we de gegevens vandaan halen
Dit lijkt nu misschien voor de hand liggend, maar FROM zal later heel belangrijk zijn als we bij joins en subquery's komen.
FROM verwijst naar de tabel die moet worden opgevraagd. Dit kan een bestaande tabel zijn (zoals in het bovenstaande voorbeeld), of een tabel die direct is gemaakt via joins of subquery's.
3.2 WAAR - welke gegevens worden getoond
WHERE gedraagt zich eenvoudigweg als een filter lijnen, die we willen uitvoeren. In ons geval willen we alleen rijen zien waarvan de waarde in de auteurskolom 'Dan Brown' is.
3.3 SELECTEREN - hoe gegevens worden weergegeven
Nu we alle benodigde kolommen uit de tabel hebben, moeten we beslissen hoe we deze gegevens precies moeten weergeven. In ons geval hebben we alleen boektitels en ID's nodig, dus dat is wat we doen. laten we kiezen Met met behulp van SELECT. Tegelijkertijd kunt u de kolom hernoemen met AS.
De hele vraag kan worden gevisualiseerd met behulp van een eenvoudig diagram:

4. Verbindingen (verbindingen)
Nu willen we de titels zien (niet noodzakelijkerwijs uniek) van alle Dan Brown-boeken die zijn uitgecheckt bij de bibliotheek, en wanneer die boeken moeten worden teruggestuurd:
SELECTeer boeken.title AS "Titel", lenings.returndate AS "Retourdatum" VAN leningen WORD LID VAN boeken OP leningen.bookid=books.bookid WAAR boeken.author="Dan Brown";
Resultaat:
| Titel | Retourdatum |
|---|---|
| Het verloren symbool | 2016-03-23 00:00:00 |
| Inferno | 2016-04-13 00:00:00 |
| Het verloren symbool | 2016-04-19 00:00:00 |
Het verzoek is grotendeels vergelijkbaar met het vorige met uitzondering van VAN-secties. Het betekent dat we vragen gegevens uit een andere tabel op. We hebben geen toegang tot de tabel “boeken” en ook niet tot de tabel “leningen”. In plaats daarvan wenden we ons tot nieuwe tafel, die is gemaakt door deze twee tabellen samen te voegen.
leningen WORD LID van boeken OP leningen.bookid=books.bookid - dit is, overweeg, nieuwe tafel, die werd gevormd door alle records uit de tabellen "boeken" en "leningen" te combineren waarin de bookid-waarden overeenkomen. Het resultaat van een dergelijke fusie zal zijn:

En dan bevragen we deze tabel op dezelfde manier als in het bovenstaande voorbeeld. Dit betekent dat u zich bij het samenvoegen van tabellen alleen maar zorgen hoeft te maken over de manier waarop u de koppeling moet maken. En dan wordt het verzoek net zo duidelijk als in het geval van “ eenvoudig verzoek» vanaf punt 3.
Laten we een iets complexere join met twee tabellen proberen.
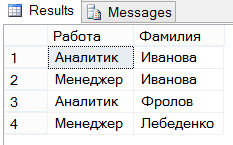
Nu willen we de voor- en achternaam krijgen van mensen die boeken van de auteur “Dan Brown” uit de bibliotheek hebben gehaald.
Deze keer gaan we van onder naar boven:
Stap Stap 1- waar halen we de gegevens vandaan? Om het gewenste resultaat te krijgen, moeten we de tabellen “leden” en “boeken” samenvoegen met de tabel “leningen”. Het JOIN-gedeelte ziet er als volgt uit:
leningen WORD LID van boeken OP leningen.bookid=boeken.bookid WORD LID van leden OP Members.memberid=borrowings.memberid
Het resultaat van de verbinding is te zien op de link.
Stap 2- welke gegevens tonen wij? We zijn alleen geïnteresseerd in gegevens waarbij de auteur van het boek “Dan Brown” is
WAAR boeken.author="Dan Brown"
Stap 3- hoe tonen we de gegevens? Nu de gegevens zijn ontvangen, hoeft u alleen maar de voor- en achternaam weer te geven van degenen die de boeken hebben meegenomen:
SELECTeer leden.voornaam ALS "Voornaam", leden.achternaam ALS "Achternaam"
Super! Het enige dat overblijft is het combineren van de drie componenten en het doen van het verzoek dat we nodig hebben:
SELECTEER leden.voornaam ALS "Voornaam", leden.achternaam ALS "Achternaam" VAN leningen WORD LID VAN boeken OP leningen.bookid=boeken.bookid WORD LID VAN leden OP Members.memberid=borrowings.memberid WAAR boeken.author="Dan Brown";
Wat zal ons opleveren:
| Voornaam | Achternaam |
|---|---|
| Mike | Willis |
| Ellen | Horton |
| Ellen | Horton |
Geweldig! Maar de namen worden herhaald (ze zijn niet uniek). We zullen dit snel oplossen.
5. Aggregatie
Grof gezegd, Er zijn aggregaties nodig om meerdere rijen naar één te converteren. Tegelijkertijd wordt tijdens de aggregatie verschillende logica gebruikt voor verschillende kolommen.
Laten we doorgaan met ons voorbeeld waarin dubbele namen verschijnen. Het is duidelijk dat Ellen Horton meer dan één boek heeft meegenomen, maar dit is niet het meeste De beste manier laat deze informatie zien. U kunt nog een verzoek indienen:
SELECTEER leden.voornaam AS "Voornaam", leden.achternaam AS "Achternaam", count(*) AS "Aantal geleende boeken" UIT leningen WORD LID VAN boeken OP lenen.bookid=boeken.bookid WORD LID VAN leden OP member.memberid=leningen .memberid WAAR boeken.author="Dan Brown" GROEPEREN OP leden.voornaam, leden.achternaam;
Wat ons het gewenste resultaat zal opleveren:
| Voornaam | Achternaam | Aantal geleende boeken |
|---|---|---|
| Mike | Willis | 1 |
| Ellen | Horton | 2 |
Bijna alle aggregaties worden geleverd met een GROUP BY-clausule. Dit ding verandert een tabel die door een query kan worden opgehaald in groepen tabellen. Elke groep komt overeen met een unieke waarde (of groep waarden) van de kolom die we hebben opgegeven in GROUP BY . In ons voorbeeld zetten we het resultaat van de vorige oefening om in een groep rijen. We doen ook een aggregatie met count , die meerdere rijen omzet in een geheel getal (in ons geval het aantal rijen). Deze betekenis wordt vervolgens aan elke groep toegekend.
Elke rij in het resultaat vertegenwoordigt het resultaat van de aggregatie van elke groep.
Men kan tot de logische conclusie komen dat alle velden in het resultaat óf in GROUP BY moeten worden opgegeven, óf dat er aggregatie op moet worden uitgevoerd. Omdat alle andere velden op verschillende regels van elkaar kunnen verschillen, en als je ze met SELECT selecteert, is het niet duidelijk welke van de mogelijke waarden moet worden genomen.
In het bovenstaande voorbeeld telfunctie alle rijen verwerkt (aangezien we het aantal rijen hebben geteld). Andere functies zoals som of max verwerken alleen gespecificeerde lijnen. Als we bijvoorbeeld willen weten hoeveel boeken elke auteur heeft geschreven, hebben we de volgende vraag nodig:
SELECTEER auteur, som(voorraad) UIT boeken GROEP OP auteur;
Resultaat:
| auteur | som |
|---|---|
| Robin Sharma | 4 |
| Dan Bruin | 6 |
| John groen | 3 |
| Amish Tripathi | 2 |
Hier som functie verwerkt alleen de voorraadkolom en berekent de som van alle waarden in elke groep.
6. Subquery's

Subquery's zijn reguliere SQL-query's die zijn ingebed in grotere query's. Ze zijn onderverdeeld in drie typen, afhankelijk van het type resultaat dat wordt geretourneerd.
6.1 Tweedimensionale tafel
Er zijn query's die meerdere kolommen retourneren. Goed voorbeeld Dit is een query uit een eerdere aggregatieoefening. Omdat het een subquery is, retourneert het eenvoudigweg een andere tabel waartegen nieuwe query's kunnen worden gemaakt. Als we doorgaan met de vorige oefening, als we het aantal boeken willen weten dat is geschreven door de auteur “Robin Sharma”, dan is een van mogelijke manieren- gebruik subquery's:
SELECT * FROM (SELECT auteur, som (voorraad) FROM boeken GROEP OP auteur) AS resultaten WAAR auteur = "Robin Sharma";
Resultaat:
Kan worden geschreven als: ["Robin Sharma", "Dan Brown"]
2. Nu gebruiken we dit resultaat in een nieuwe query:
SELECT titel, boek-ID UIT boeken WAAR auteur IN (SELECT auteur UIT (SELECT auteur, som(voorraad) UIT boeken GROEP OP auteur) AS resultaten WAAR som > 3);
Resultaat:
| titel | boeknummer |
|---|---|
| Het verloren symbool | 2 |
| Wie zal huilen als je sterft? | 3 |
| Inferno | 4 |
Dit is hetzelfde als:
SELECTEER titel, boek-id UIT boeken WAAR auteur IN ("Robin Sharma", "Dan Brown");
6.3 Individuele waarden
Er zijn zoekopdrachten die slechts één rij en één kolom opleveren. Ze kunnen worden behandeld als constante waarden en kunnen overal worden gebruikt waar waarden worden gebruikt, zoals in vergelijkingsoperatoren. Ze kunnen ook worden gebruikt als tweedimensionale tabellen of arrays met één element.
Laten we bijvoorbeeld informatie krijgen over alle boeken waarvan het aantal in de bibliotheek de gemiddelde waarde overschrijdt dit moment.
Het gemiddelde kan op deze manier worden verkregen:
selecteer gem(stock) uit boeken;
Wat geeft ons:
7. Schrijfbewerkingen
De meeste schrijfbewerkingen voor databases zijn vrij eenvoudig vergeleken met complexere leesbewerkingen.
7.1 Bijwerken
De syntaxis van een UPDATE-verzoek is semantisch hetzelfde als een leesverzoek. Het enige verschil is dat we in plaats van kolommen te selecteren met SELECT, de kennis instellen met SET.
Als alle boeken van Dan Brown verloren zijn gegaan, moet u de hoeveelheidswaarde opnieuw instellen. De vraag hiervoor zou zijn:
UPDATE boeken SET voorraad=0 WAAR auteur="Dan Brown";
WHERE doet hetzelfde als voorheen: selecteert rijen. In plaats van de SELECT die we gebruikten bij het lezen, gebruiken we nu SET. Nu moet u echter niet alleen de kolomnaam opgeven, maar ook een nieuwe waarde voor deze kolom in de geselecteerde rijen.
7.2 Verwijderen
Een DELETE-query is eenvoudigweg een SELECT- of UPDATE-query zonder kolomnamen. Ernstig. Net als bij SELECT en UPDATE blijft het WHERE-blok hetzelfde: het selecteert de rijen die moeten worden verwijderd. De verwijderbewerking vernietigt de hele rij, dus het heeft geen zin om afzonderlijke kolommen op te geven. Dus als we besluiten het aantal Dan Brown-boeken niet opnieuw in te stellen, maar alle records helemaal te verwijderen, kunnen we het volgende verzoek indienen:
VERWIJDER UIT boeken WAAR auteur="Dan Brown";
7.3 Invoegen
Misschien is INSERT het enige dat verschilt van andere soorten zoekopdrachten. Het formaat is:
INVOEGEN IN x (a,b,c) WAARDEN (x, y, z);
Waar a, b, c de kolomnamen zijn, en x, y en z de waarden zijn die in die kolommen moeten worden ingevoegd, in dezelfde volgorde. Dat is het eigenlijk.
Laten we eens kijken specifiek voorbeeld. Hier is een INSERT-query die de volledige tabel 'boeken' vult:
INSERT INTO boeken (bookid,titel,auteur,gepubliceerd,voorraad) WAARDEN (1,"Scion of Ikshvaku","Amish Tripathi","22-06-2015",2), (2,"Het verloren symbool"," Dan Brown", "22-07-2010",3), (3",Wie zal huilen als je sterft?", "Robin Sharma", "15-06-2006",4), (4",Inferno" "Dan Brown", "05-05-2014",3), (5,"De fout in onze sterren", "John Green", "01-03-2015",3);
8. Controleer
We zijn aan het einde gekomen, ik stel een kleine test voor. Kijk eens naar dat verzoek helemaal aan het begin van het artikel. Kunt u het uitzoeken? Probeer het op te splitsen in secties SELECT , FROM , WHERE , GROUP BY , en denk erover na individuele onderdelen subquery's.
Hier staat het in een beter leesbare vorm:
SELECT leden.voornaam || " " || Members.lastname AS "Volledige naam" FROM leningen INNER JOIN leden ON members.memberid=borrowings.memberid INNER JOIN boeken ON books.bookid=borrowings.bookid WHERE leningen.bookid IN (SELECT bookid FROM boeken WHERE stock> (SELECT avg(stock ) UIT boeken)) GROEPEREN OP leden.voornaam, leden.achternaam;
Deze zoekopdracht retourneert een lijst met mensen die een boek uit de bibliotheek hebben uitgeleend en waarvan het totale aantal boven het gemiddelde ligt.
Resultaat:
| Voor-en achternaam |
|---|
| Lida Tyler |
Ik hoop dat je er zonder problemen uit hebt kunnen komen. Maar zo niet, dan zou ik graag uw opmerkingen en feedback ontvangen, zodat ik dit bericht kan verbeteren.
Tags: tags toevoegen
Tabelexpressies worden subquery's genoemd die worden gebruikt waar de aanwezigheid van een tabel wordt verwacht. Er zijn twee typen tabelexpressies:
afgeleide tabellen;
gegeneraliseerde tabelexpressies.
Deze twee vormen van tabelexpressies worden in de volgende subsecties besproken.
Afgeleide tabellen
Afgeleide tafel is een tabelexpressie die is opgenomen in de FROM-clausule van een query. Afgeleide tabellen kunnen worden gebruikt in gevallen waarin het gebruik van kolomaliassen niet mogelijk is omdat de SQL-vertaler een andere instructie verwerkt voordat de alias bekend is. In het onderstaande voorbeeld ziet u een poging om een kolomalias te gebruiken in een situatie waarin een andere clausule wordt verwerkt voordat de alias bekend is:
GEBRUIK SampleDb; SELECTEER MAAND(EnterDatum) als enter_month FROM Works_on GROUP BY enter_month;
Als u deze query probeert uit te voeren, wordt het volgende foutbericht weergegeven:
Bericht 207, Niveau 16, Staat 1, Regel 5 Ongeldige kolomnaam "enter_month". (Bericht 207: Niveau 16, Staat 1, Regel 5 Ongeldige kolomnaam enter_month)
De reden voor de fout is dat de GROUP BY-clausule wordt verwerkt voordat de corresponderende lijst van de SELECT-instructie wordt verwerkt, en dat de kolomalias enter_month onbekend is wanneer de groep wordt verwerkt.
Dit probleem kan worden opgelost door een afgeleide tabel te gebruiken die de voorgaande query bevat (zonder de GROUP BY-clausule), aangezien de FROM-clausule wordt uitgevoerd voordat GROEP aanbieding DOOR:
GEBRUIK SampleDb; SELECT enter_month FROM (SELECT MONTH(EnterDate) als enter_month FROM Works_on) AS m GROUP BY enter_month;
Het resultaat van deze query zal als volgt zijn:
Normaal gesproken kan een tabelexpressie overal in een SELECT-instructie worden geplaatst waar een tabelnaam kan voorkomen. (Het resultaat van een tabelexpressie is altijd een tabel of, in speciale gevallen, een expressie.) Het onderstaande voorbeeld toont het gebruik van een tabelexpressie in de selectielijst van een SELECT-instructie:
Het resultaat van deze vraag:
Algemene tabelexpressies
Gemeenschappelijke tabelexpressie (OTB) is een benoemde tabelexpressie die wordt ondersteund door de Transact-SQL-taal. Algemene tabelexpressies worden gebruikt in de volgende twee typen query's:
niet-recursief;
recursief.
Deze twee soorten verzoeken worden in de volgende paragrafen besproken.
OTB en niet-recursieve zoekopdrachten
De niet-recursieve vorm van OTB kan worden gebruikt als alternatief voor afgeleide tabellen en weergaven. Typisch wordt OTB bepaald door MET clausules En aanvullende aanvraag, wat verwijst naar de naam die wordt gebruikt in de WITH-clausule. In Transact-SQL de waarde trefwoord MET is dubbelzinnig. Om dubbelzinnigheid te voorkomen, moet de instructie die voorafgaat aan de WITH-instructie worden afgesloten met een puntkomma.
GEBRUIK AdventureWorks2012; SELECTEER SalesOrderID VAN Sales.SalesOrderHeader WHERE TotalDue > (SELECTEER AVG(TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR(OrderDate) = "2005") EN Vracht > (SELECTEER AVG(TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR(OrderDate) = "2005 ")/2,5;
De query in dit voorbeeld selecteert orders waarvan de totale belastingen (TotalDue) groter zijn dan het gemiddelde van alle belastingen en waarvan de vrachtkosten (Freight) groter zijn dan 40% van de gemiddelde belastingen. De belangrijkste eigenschap van deze query is de lengte ervan, aangezien de subquery twee keer geschreven moet worden. Een mogelijke manier om de hoeveelheid queryconstructie te verminderen, is door een weergave te maken die een subquery bevat. Maar deze oplossing is een beetje ingewikkeld omdat er een weergave moet worden gemaakt en deze vervolgens moet worden verwijderd nadat de query is uitgevoerd. Een betere aanpak zou zijn om een OTB te creëren. Het onderstaande voorbeeld toont het gebruik van niet-recursieve OTB, waardoor de bovenstaande querydefinitie wordt ingekort:
GEBRUIK AdventureWorks2012; WITH price_calc(year_2005) AS (SELECT AVG(TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR(OrderDate) = "2005") SELECT SalesOrderID FROM Sales.SalesOrderHeader WHERE TotalDue > (SELECT year_2005 FROM price_calc) AND Freight > (SELECT year_2005 FROM price_calc ) /2,5;
De syntaxis van de WITH-clausule in niet-recursieve query's is als volgt:
De parameter cte_name vertegenwoordigt de OTB-naam die de resulterende tabel definieert, en de parameter column_list vertegenwoordigt de lijst met kolommen van de tabelexpressie. (In het bovenstaande voorbeeld heet de OTB price_calc en heeft deze één kolom, year_2005.) De parameter inner_query vertegenwoordigt een SELECT-instructie die de resultatenset van de corresponderende tabelexpressie specificeert. De gedefinieerde tabelexpressie kan vervolgens worden gebruikt in de outside_query. (De buitenste query in het bovenstaande voorbeeld gebruikt OTB price_calc en de kolom year_2005 om de dubbel geneste query te vereenvoudigen.)
OTB en recursieve zoekopdrachten
In deze sectie wordt materiaal met een grotere complexiteit gepresenteerd. Daarom wordt aanbevolen om het bij de eerste keer lezen over te slaan en er later op terug te komen. OTB's kunnen worden gebruikt om recursie te implementeren, omdat OTB's verwijzingen naar zichzelf kunnen bevatten. Basis OTB-syntaxis voor recursieve vraag het lijkt hierop:
De parameters cte_name en column_list hebben dezelfde betekenis als in OTB voor niet-recursieve zoekopdrachten. De hoofdtekst van een WITH-clausule bestaat uit twee query's die door de operator worden gecombineerd UNIE ALLEMAAL. De eerste query wordt slechts één keer aangeroepen en begint het resultaat van de recursie te verzamelen. De eerste operand van de UNION ALL-operator verwijst niet naar OTB. Deze query wordt een referentiequery of bron genoemd.
De tweede query bevat een verwijzing naar de OTB en vertegenwoordigt het recursieve deel ervan. Daarom wordt het een recursief lid genoemd. In de eerste aanroep van het recursieve deel vertegenwoordigt de OTB-referentie het resultaat van de referentiequery. Het recursieve lid gebruikt het resultaat van de eerste queryoproep. Hierna roept het systeem het recursieve deel opnieuw aan. Een aanroep naar een recursief lid stopt wanneer een eerdere aanroep ernaar een lege resultatenset retourneert.
De operator UNION ALL voegt zich bij de momenteel verzamelde rijen, evenals extra lijnen, toegevoegd huidige oproep recursief lid. (De aanwezigheid van de operator UNION ALL betekent dat dubbele rijen niet uit het resultaat worden verwijderd.)
Ten slotte specificeert de parameter outside_query de buitenste query die OTB gebruikt om alle aanroepen voor de join van beide leden op te halen.
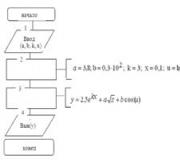
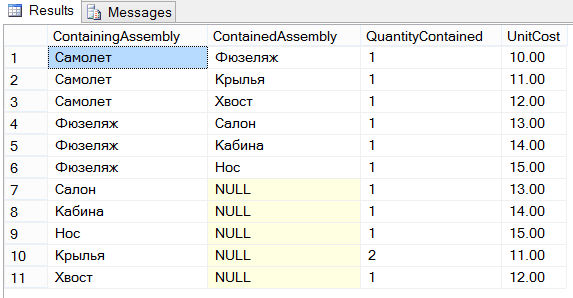
Om de recursieve vorm van OTB te demonstreren, gebruiken we de vliegtuigtabel die is gedefinieerd en gevuld met de code uit het onderstaande voorbeeld:
GEBRUIK SampleDb; TABEL MAKEN Vliegtuig (ContainingAssembly VARCHAR(10), ContainedAssembly VARCHAR(10), HoeveelheidContained INT, UnitCost DECIMAL(6,2)); INSERT IN Vliegtuig WAARDEN ("Vliegtuig", "Romp", 1, 10); INSERT IN Vliegtuig WAARDEN ("Vliegtuig", "Vleugels", 1, 11); INSERT IN Vliegtuig WAARDEN ("Vliegtuig", "Staart", 1, 12); INSERT IN Vliegtuig WAARDEN ("Romp", "Salon", 1, 13); INSERT IN Vliegtuig WAARDEN ("Romp", "Cockpit", 1, 14); INSERT INTO Airplane WAARDEN ("Romp", "Neus", 1, 15); INSERT INTO Airplane WAARDEN ("Cabin", NULL, 1,13); INSERT INTO Airplane WAARDEN ("Cockpit", NULL, 1, 14); INSERT INTO Airplane WAARDEN ("Neus", NULL, 1, 15); INSERT IN Vliegtuig WAARDEN ("Vleugels", NULL,2, 11); INSERT INTO Airplane WAARDEN ("Staart", NULL, 1, 12);
De Vliegtuigtafel heeft vier kolommen. De kolom ContainingAssembly identificeert het samenstel, en de kolom ContainedAssembly identificeert de onderdelen (één voor één) waaruit het overeenkomstige samenstel bestaat. De onderstaande figuur toont een grafische weergave van een mogelijk type vliegtuig en zijn onderdelen:

De Vliegtuigtabel bestaat uit de volgende 11 rijen:
In het volgende voorbeeld wordt de WITH-clausule gebruikt om een query te definiëren die de totale kosten van elke build berekent:
GEBRUIK SampleDb; WITH list_of_parts(assembly1, aantal, kosten) AS (SELECT ContainingAssembly, HoeveelheidContained, UnitCost VAN Vliegtuig WAAR ContainedAssembly NULL UNION IS ALLES SELECTEER a.ContainingAssembly, a.QuantityContained, CAST(l.quantity * l.cost AS DECIMAL(6,2) ) VAN lijst_van_onderdelen l, Vliegtuig a WAAR l.assembly1 = a.ContainedAssembly) SELECTEER montage1 "Onderdeel", hoeveelheid "Aantal", kosten "Prijs" VAN lijst_van_onderdelen;
De WITH-clausule definieert een OTB-lijst met de naam list_of_parts, bestaande uit drie kolommen: assemblage1, hoeveelheid en kosten. De eerste SELECT-instructie in het voorbeeld wordt slechts één keer aangeroepen om de resultaten van de eerste stap van het recursieproces op te slaan. De SELECT-instructie op de laatste regel van het voorbeeld geeft het volgende resultaat weer.