Captcha-herkenning: methoden en technologieën. De universele CAPTCHA Python CAPTCHA-herkenning testen
Dat was de naam van het werk dat ik presenteerde op de Baltic Science and Engineering Competition, en dat me een charmant stuk papier met een Romeins nummer opleverde, evenals een gloednieuwe laptop.
Het werk bestond uit het herkennen van CAPTCHA's die door grote mobiele operators worden gebruikt in sms-verzendformulieren en het aantonen van het gebrek aan effectiviteit van hun aanpak. Om niemands trots te kwetsen, zullen we deze operatoren allegorisch noemen: rood, geel, groen en blauw.
Het project kreeg de officiële naam Captchure en onofficieel Defecte beveiligingsmaatregelen overtreden... Alle toevalligheden zijn toevallig.
Vreemd genoeg bleken alle (nou ja, bijna alle) CAPTCHA's behoorlijk zwak te zijn. Het kleinste resultaat - 20% - behoort toe aan de gele operator, het grootste - 86% - aan de blauwe. Ik geloof dus dat de taak om "inefficiëntie aan te tonen" met succes is volbracht.
De redenen om voor mobiele operators te kiezen zijn triviaal. Aan de gewaardeerde wetenschappelijke jury vertelde ik het verhaal dat “mobiele operators genoeg geld hebben om een programmeur met enige vaardigheid in te huren, en dat ze tegelijkertijd de hoeveelheid spam moeten minimaliseren; hun CAPTCHA's moeten dus behoorlijk krachtig zijn, wat volgens mijn onderzoek helemaal niet het geval is." Eigenlijk was alles veel eenvoudiger. Ik wilde ervaring opdoen door een simpele CAPTCHA te hacken en de rode operator CAPTCHA als slachtoffer te kiezen. En daarna, achteraf gezien, was het bovengenoemde verhaal geboren.
Dus dichter bij het lichaam. Ik heb geen mega-geavanceerd algoritme om alle vier typen CAPTCHA's te herkennen; in plaats daarvan heb ik voor elk type CAPTCHA afzonderlijk 4 verschillende algoritmen geschreven. Hoewel de algoritmen in detail verschillen, lijken ze over het algemeen erg op elkaar.
Zoals vele auteurs voor mij, heb ik de CAPTCHA-herkenningstaak opgesplitst in 3 subtaken: preprocessing (preprocessing), segmentatie en herkenning. In de voorbewerkingsfase worden verschillende ruis, vervormingen, enz. uit de originele afbeelding verwijderd. Bij segmentatie worden individuele karakters uit de originele afbeelding gehaald en nabewerkt (bijvoorbeeld omgekeerde rotatie). Tijdens de herkenning worden symbolen één voor één verwerkt door een vooraf getraind neuraal netwerk.
Alleen het voorproces was significant anders. Dit komt door het feit dat verschillende CAPTCHA's verschillende methoden voor beeldvervorming toepassen, en de algoritmen voor het verwijderen van deze vervormingen lopen sterk uiteen. Segmentatie maakte gebruik van het sleutelidee om connectiviteitscomponenten te vinden met kleine toeters en bellen (belangrijke moest alleen in geel gestreept worden gedaan). De herkenning was precies hetzelfde voor drie van de vier operators - nogmaals, alleen de gele operator was anders.
Ten slotte worden kleine (minder dan 10px) zwarte verbonden gebieden gevuld met wit:
Soms (zelden, maar het gebeurt) splitst de brief in verschillende delen; Om dit vervelende misverstand te corrigeren, gebruik ik een vrij eenvoudige heuristiek die evalueert of verschillende verbindingscomponenten tot hetzelfde symbool behoren. Deze schatting hangt alleen af van de horizontale positie en grootte van de begrenzingsvakken van elk symbool.
Het is gemakkelijk te zien dat veel symbolen zijn gecombineerd tot één component van connectiviteit, en daarom is het noodzakelijk om ze te scheiden. Dit is waar het feit dat er altijd precies 5 karakters op de afbeelding staan, te hulp komt. Hiermee kunt u met grote nauwkeurigheid berekenen hoeveel tekens er in elk gevonden onderdeel zitten.
Om het werkingsprincipe van zo'n algoritme uit te leggen, zul je wat dieper in het materiaal moeten duiken. Laten we het aantal gevonden segmenten aanduiden met n, en de reeks breedtes ( zei toch, hè?) van alle segmenten buiten de breedtes [n]. We nemen aan dat als na de bovengenoemde stappen n> 5 het beeld niet herkend kon worden. Overweeg alle mogelijke decomposities van het getal 5 in positieve gehele getallen. Er zijn er niet veel - slechts 16. Elke ontleding komt overeen met een mogelijke rangschikking van symbolen volgens de gevonden verbindingscomponenten. Het is logisch om aan te nemen dat hoe breder het resulterende segment, hoe meer tekens het bevat. Van alle decomposities van de vijf kiezen we alleen die waarin het aantal termen gelijk is aan n. Verdeel elk element van breedte door breedte - soort van normaliseer ze. We zullen hetzelfde doen met alle resterende uitbreidingen - deel elk getal erin door de eerste term. En nu (let op, culminatie!) Merk op dat de resulterende geordende n-ki kan worden gezien als punten in de n-dimensionale ruimte. Hiermee rekening houdend, vinden we de ontleding van vijf tot de genormaliseerde breedten die het dichtst in Euclides liggen. Dit is het gewenste resultaat.
Trouwens, in verband met dit algoritme bedacht ik een andere interessante manier om alle decomposities van een getal in termen te zoeken, die ik echter nooit heb geïmplementeerd, omdat ik mezelf heb begraven in Python-gegevensstructuren. Kortom, het komt heel duidelijk naar voren als je merkt dat het aantal uitbreidingen van een bepaalde lengte samenvalt met het overeenkomstige niveau van de driehoek van Pascal. Ik ben er echter zeker van dat dit algoritme al heel lang bekend is.
Dus, na het bepalen van het aantal karakters in elke component, treedt de volgende heuristiek op: we zijn van mening dat de scheidingstekens tussen de karakters dunner zijn dan de karakters zelf. Laten we, om deze diepste kennis te gebruiken, n-1 scheidingstekens over het segment plaatsen, waarbij n het aantal tekens in het segment is, waarna we in een kleine buurt van elk scheidingsteken de projectie van het beeld naar beneden berekenen. Als resultaat van deze projectie krijgen we informatie over hoeveel pixels in elke kolom bij symbolen horen. Ten slotte vinden we in elke projectie het minimum en verplaatsen we de separator daar, waarna we het beeld langs deze separators snijden.
Eindelijk erkenning. Zoals ik al zei, ik gebruik er een neuraal netwerk voor. Om haar dat te leren, plaats ik eerst tweehonderd afbeeldingen onder de algemene noemer trein set door de reeds geschreven en gedebugde eerste twee fasen, waardoor ik een map krijg met een groot aantal netjes uitgesneden segmenten. Vervolgens ruim ik met mijn handen het afval op (bijvoorbeeld de resultaten van een verkeerde segmentering), waarna ik het resultaat op één maat breng en aan FANN geef om het uit elkaar te halen. Aan de uitgang krijg ik een getraind neuraal netwerk, dat wordt gebruikt voor herkenning. Dit plan mislukte slechts één keer - daarover later meer.
Als gevolg hiervan is de codenaam in de testcase (niet gebruikt voor training) testset) 45 van de 100 foto's werden correct herkend. Geen erg hoog resultaat - het kan natuurlijk worden verbeterd, bijvoorbeeld door het voorproces te verfijnen of de herkenning opnieuw uit te voeren, maar eerlijk gezegd was ik te lui om me ermee bezig te houden .
Daarnaast heb ik nog een criterium gebruikt om de prestaties van het algoritme te evalueren: de gemiddelde fout. Het werd als volgt berekend. Voor elke afbeelding werd de Levenshtein-afstand gevonden tussen de mening van het algoritme over deze afbeelding en het juiste antwoord - waarna het rekenkundig gemiddelde over alle afbeeldingen werd genomen. Voor dit soort CAPTCHA was de gemiddelde fout 0,75 tekens / afbeelding. Het lijkt mij dat dit een nauwkeuriger criterium is dan alleen het percentage herkenning.
Trouwens, bijna overal (behalve de gele operator) heb ik precies dit schema gebruikt - 200 foto's in het treinstel, 100 - in de testset.
Groente
Het volgende doel koos ik voor groen - ik wilde iets serieuzers aanpakken dan de selectie van de vervormingsmatrix.
Voordelen:
- Driedimensionaliteitseffect
- Rotatie en verplaatsing:
- Ongelijke helderheid
Gebreken:
- Symbolen zijn merkbaar donkerder dan de achtergrond
- De bovenkant van de rechthoek is duidelijk zichtbaar - kan worden gebruikt voor omgekeerde rotatie
Het bleek dat zelfs ondanks het feit dat deze nadelen schijnbaar onbeduidend zijn, hun exploitatie het mogelijk maakt om zeer effectief met alle voordelen om te gaan.
Laten we opnieuw beginnen met voorbewerken. Laten we eerst de rotatiehoek schatten van de rechthoek waarop de symbolen liggen. Om dit te doen, past u de Erode-operator toe (zoek naar een lokaal minimum) op de originele afbeelding, vervolgens Threshold om de overblijfselen van de rechthoek te selecteren en tenslotte de inversie. Laten we een mooie witte vlek op een zwarte achtergrond krijgen.
Dan begint een diepe gedachte. Eerste. Om de rotatiehoek van de gehele rechthoek te schatten, volstaat het om de rotatiehoek van zijn bovenzijde te schatten. Seconde. Je kunt de rotatiehoek van de bovenzijde inschatten door te zoeken naar een rechte lijn evenwijdig aan die zijde. Derde. Om elke rechte lijn te beschrijven, behalve strikt verticaal, zijn twee parameters voldoende: de verticale verschuiving vanaf het middelpunt van de coördinaten en de hellingshoek, en we zijn alleen geïnteresseerd in de tweede. Vierde. Het probleem van het vinden van een rechte lijn kan niet worden opgelost door een heel grote zoektocht - er zijn daar geen te grote draaihoeken en we hebben geen ultrahoge nauwkeurigheid nodig. Vijfde. Om de benodigde rechte lijn te vinden, kunt u elke rechte lijn vergelijken met een schatting van hoe dicht deze bij de gewenste is en vervolgens het maximum kiezen. Zesde. Het belangrijkste. Om een bepaalde hellingshoek van een rechte lijn te schatten, stelt u zich voor dat een rechte lijn met zo'n hellingshoek het beeld van boven raakt. Het is duidelijk dat uit de afmetingen van het beeld en de hellingshoek het mogelijk is om de verticale verplaatsing van de rechte lijn eenduidig te berekenen, zodat deze eenduidig is ingesteld. Verder zullen we deze lijn geleidelijk naar beneden verplaatsen. Op een gegeven moment zal ze de witte vlek aanraken. Laten we dit moment en het snijpunt van de rechte lijn met de plek onthouden. Laat me je eraan herinneren dat de rechte lijn 8-verbonden is in het vliegtuig, daarom zijn de boze kreten van het publiek dat de rechte lijn één dimensie heeft en het gebied een tweedimensionaal concept is, hier ongepast. Daarna zullen we deze rechte lijn nog een tijdje naar beneden verplaatsen, waarbij we bij elke stap het snijpuntgebied onthouden, waarna we de verkregen resultaten zullen samenvatten. Deze som is de schatting van de gegeven rotatiehoek.
Om het bovenstaande samen te vatten: we gaan op zoek naar zo'n rechte lijn dat wanneer deze naar beneden in het beeld beweegt, de helderheid van de pixels die op deze rechte lijn liggen het sterkst toeneemt.
Dus de draaihoek is gevonden. Maar men moet zich niet haasten om de opgedane kennis onmiddellijk toe te passen. Het punt is dat dit de samenhang van het beeld verpest, en dat hebben we nog steeds nodig.
De volgende stap is om de karakters van de achtergrond te scheiden. Het feit dat de karakters beduidend donkerder zijn dan de achtergrond helpt ons hier enorm bij. Een vrij logische stap van de kant van de ontwikkelaars - anders zou de afbeelding erg moeilijk te lezen zijn. Degenen die niet geloven, kunnen proberen het beeld zelf te binariseren en met eigen ogen te zien.
De frontale benadering - een poging om karakters af te snijden door middel van drempels - werkt hier echter niet. Het beste resultaat dat ik heb kunnen bereiken - op t = 140 - ziet er zeer betreurenswaardig uit. Er blijft te veel rommel achter. Daarom moest er een workaround worden toegepast. Het idee is als volgt. Symbolen zijn meestal verbonden. En die horen vaak bij de donkerste punten in het beeld. Maar wat als je probeert te vullen vanaf die donkerste punten en dan te kleine gevulde gebieden weggooit - duidelijk afval?
Het resultaat is, eerlijk gezegd, verbluffend. Bij de meeste afbeeldingen is het mogelijk om de achtergrond volledig te verwijderen. Het komt echter voor dat een symbool in verschillende delen uiteenvalt - in dit geval kan een kruk in segmentatie helpen - maar daarover later meer.
Ten slotte redt de combinatie van de operatoren Dilate en Erode ons van de kleine gaatjes die in de karakters achterblijven, wat de herkenning helpt te vereenvoudigen.
Segmentatie is hier veel eenvoudiger dan voorbewerking. Allereerst zijn we op zoek naar connectiviteitscomponenten.
Vervolgens combineren we de componenten die horizontaal dicht bij elkaar liggen (de procedure is precies hetzelfde als voorheen):
Dit algoritme maakte het mogelijk om een resultaat te behalen van 69% van de succesvol herkende afbeeldingen en een gemiddelde fout van 0,3 symbool / afbeelding.
Blauw
Dus de derde status "verslagen" werd ontvangen door de blauwe operator. Het was, om zo te zeggen, een uitstel voor een echt grote vis ...
Het is moeilijk om iets in de verdiensten op te schrijven, maar ik zal niettemin proberen:
- Rotatie van symbolen is het enige min of meer ernstige obstakel
- Achtergrondgeluid als symbolen
- Symbolen raken elkaar soms
In tegenstelling tot:
- De achtergrond is aanzienlijk lichter dan de symbolen
- Symbolen passen goed in een rechthoek
- Verschillende kleuren symbolen maken het gemakkelijk om ze van elkaar te scheiden
Het voortraject dus. Laten we beginnen met het knippen van de achtergrond. Aangezien het beeld driekleurig is, laten we het in kanalen knippen en vervolgens alle punten weggooien die helderder zijn dan 116 in alle kanalen. Laten we zo'n mooi masker nemen:
Vervolgens converteren we de afbeelding naar de HSV-kleurruimte (Wikipedia). Hierdoor blijft informatie over de kleur van de symbolen behouden en wordt tegelijkertijd het verloop van hun randen verwijderd.
Laten we het eerder verkregen masker toepassen op het resultaat:
Hier stopt het voortraject. Segmentatie is ook vrij triviaal. Laten we, zoals altijd, beginnen met de connectiviteitscomponenten:
Ik had hier kunnen stoppen, maar dit is slechts 73%, wat helemaal niet bij mij past - slechts 4% beter dan het resultaat van de duidelijk complexere CAPTCHA. De volgende stap is dus om de rotatie van de karakters om te keren. Hier komt het feit dat ik al heb gezegd dat lokale symbolen goed in een rechthoek passen, van pas. Het idee is om voor elk teken een omschrijvende rechthoek te vinden en dan, uit de helling, de helling van het teken zelf te berekenen. Hier wordt onder een omschrijvende rechthoek zodanig verstaan dat deze ten eerste alle pixels van een bepaald symbool bevat en ten tweede de kleinst mogelijke oppervlakte heeft. Ik gebruik een kant-en-klare implementatie van het algoritme voor het vinden van zo'n rechthoek uit OpenCV (MinAreaRect2).
Dit algoritme herkent met succes 86% van de afbeeldingen met een gemiddelde fout van 0,16 karakters/afbeelding, wat de aanname bevestigt dat deze CAPTCHA echt de eenvoudigste is. De exploitant is echter ook niet de grootste...
Geel
Het meest interessante deel komt eraan. Om zo te zeggen, de apotheose van mijn creatieve activiteit 🙂 Deze CAPTCHA is echt de moeilijkste, zowel voor een computer als, helaas, voor een persoon.
Voordelen:
- Ruis in de vorm van vlekken en lijnen
- Symbolen draaien en schalen
- Nabijheid van symbolen
Gebreken:
- Zeer beperkt palet
- Alle lijnen zijn erg dun
- Vlekken kruisen symbolen vaak niet
- De rotatiehoek van alle karakters is ongeveer hetzelfde
Ik heb lang nagedacht over de eerste stap. Het eerste dat in me opkwam, was spelen met de lokale maxima (Dilate) om de kleine ruis te verwijderen. Deze benadering leidde er echter toe dat er weinig van de letters overbleef - alleen gescheurde contouren. Het probleem werd verergerd door het feit dat de textuur van de personages zelf heterogeen is - dit is duidelijk zichtbaar bij hoge vergroting. Om er vanaf te komen, besloot ik de domste methode te kiezen - ik opende Paint en schreef de codes op voor alle kleuren in de afbeeldingen. Het bleek dat er vier verschillende texturen in deze afbeeldingen zijn, en drie van hen hebben 4 verschillende kleuren, en de laatste heeft er 3; bovendien bleken alle componenten van deze kleuren veelvouden van 51 te zijn. Daarna maakte ik een kleurentabel, waarmee ik de textuur wist weg te werken. Voor deze "remap" overschrijf ik echter nog steeds alle pixels die te licht zijn, die zich meestal aan de randen van de karakters bevinden - anders moet ik ze markeren als ruis, en dan met ze vechten, terwijl ze weinig informatie bevatten.
Dus na deze transformatie bevat de afbeelding niet meer dan 6 kleuren - 4 kleuren symbolen (we zullen ze conventioneel grijs, blauw, lichtgroen en donkergroen noemen), wit (achtergrondkleur) en "onbekend", wat betekent dat de kleur van de pixel op zijn plaats kon met geen van de beroemde bloemen worden geïdentificeerd. De naam is voorwaardelijk - want op dit moment gooi ik drie kanalen weg en ga ik naar het bekende en handige monochrome beeld.
De volgende stap was om lijnen uit de afbeelding te verwijderen. Hier wordt de situatie gered door het feit dat deze lijnen erg dun zijn - slechts 1 pixel. Een eenvoudig filter stelt zichzelf voor: doorloop het hele beeld en vergelijk de kleur van elke pixel met de kleuren van zijn buren (in paren - verticaal en horizontaal); als de buren qua kleur overeenkomen en tegelijkertijd niet overeenkomen met de kleur van de pixel zelf, maak deze dan hetzelfde als de buren. Ik gebruik een iets geavanceerdere versie van hetzelfde filter, dat in twee fasen werkt. Op de eerste beoordeelt hij de buren op een afstand van 2, op de tweede - op een afstand van 1. Hiermee kunt u het volgende effect bereiken:
Vervolgens verwijder ik de meeste vlekken, evenals de "onbekende" kleur. Om dit te doen, zoek ik eerst naar alle kleine verbonden gebieden (minder dan 15 in gebied, om precies te zijn), plaats ze op een zwart-witmasker en combineer het resultaat met de gebieden die worden ingenomen door de "onbekende" kleur .
Met behulp van deze maskers stimuleer ik het Inpaint-algoritme (of liever, de implementatie ervan in OpenCV). Dit kan zeer effectief zijn bij het verwijderen van het meeste vuil van de afbeelding.
De implementatie van dit algoritme in OpenCV is echter gemaakt om met foto's en video's te werken en om kunstmatig gemaakte afbeeldingen met ruisende tekst niet te herkennen. Na het aanbrengen verschijnen er gradiënten, die ik zou willen vermijden om de segmentatie te vereenvoudigen. Er moet dus extra worden bewerkt, namelijk slijpen. Voor de kleur van elke pixel bereken ik de dichtstbijzijnde uit de bovenstaande tabel (onthoud dat er 5 kleuren zijn - één voor elk van de karakterstructuren en wit).
Ten slotte zal de laatste stap van de voorbewerking zijn om alle resterende kleine verbonden gebieden te verwijderen. Ze verschijnen na het aanbrengen van Inpaint, dus hier is geen herhaling.
Laten we verder gaan met segmentatie. Het wordt enorm gecompliceerd door het feit dat de symbolen erg dicht bij elkaar staan. Het kan voorkomen dat de helft van de ander niet zichtbaar is achter het ene symbool. Het wordt wel heel erg als deze symbolen ook dezelfde kleur hebben. Daarnaast spelen de overblijfselen van puin ook een rol - het kan gebeuren dat in het originele beeld een groot aantal lijnen elkaar op één plek kruisten. In dit geval zal het algoritme dat ik eerder heb beschreven niet in staat zijn om ze kwijt te raken.
Na een week te hebben doorgebracht in vruchteloze pogingen om segmentatie op dezelfde manier te schrijven als in eerdere gevallen, gaf ik het op en veranderde mijn tactiek. Mijn nieuwe strategie was om het hele segmentatieproces in twee delen te splitsen. De eerste evalueert de rotatiehoek van de karakters en voert de omgekeerde rotatie uit. In de tweede van de reeds uitgevouwen afbeelding worden de symbolen opnieuw toegewezen. Dus laten we beginnen. Laten we, zoals altijd, beginnen met het zoeken naar connectiviteitscomponenten.
Vervolgens moet u de rotatiehoek van elk symbool schatten. Zelfs toen ik met een fanatieke operator van greenpeace werkte, bedacht ik hier een algoritme voor, maar ik schreef en paste het alleen hier toe. Om te illustreren hoe het werkt, zal ik een analogie trekken. Stel je een zuiger voor die van onder naar boven beweegt op een zwart-wit symbool. De zuigerhandgreep, waarmee hij wordt geduwd, bevindt zich verticaal, het werkplatform waarmee hij duwt - horizontaal, evenwijdig aan de onderkant van het beeld en loodrecht op de handgreep. De handgreep is in het midden aan het platform bevestigd en op het bevestigingspunt bevindt zich een beweegbare verbinding waardoor het platform kan worden gedraaid. Mogen de terminologiespecialisten mij vergeven.
Laat de hendel omhoog bewegen en duw het platform voor je uit volgens de wetten van de fysica. We nemen aan dat alleen de witte afbeelding van het symbool materieel is en dat de piston gemakkelijk door de zwarte achtergrond gaat. Dan zal de zuiger, die de witte kleur heeft bereikt, ermee gaan interageren, namelijk draaien - op voorwaarde dat de kracht nog steeds op de hendel wordt uitgeoefend. Hij kan in twee gevallen stoppen: als hij op het symbool rustte aan beide zijden van het krachtpunt, of als hij op het symbool rustte bij het krachtpunt. In alle andere gevallen zal hij kunnen blijven bewegen. Let op, culminatie: we nemen aan dat de rotatiehoek van het symbool de hellingshoek is van de zuiger op het moment dat deze stopte.
Dit algoritme is vrij nauwkeurig, maar uiteraard te grote resultaten (meer dan 27 graden) houd ik geen rekening mee. Van de overige vind ik het rekenkundig gemiddelde, waarna ik het hele beeld met min deze hoek roteer. Dan zoek ik opnieuw naar verbindingscomponenten.
Dan wordt het steeds interessanter. In de vorige voorbeelden begon ik verschillende shenanigans met de ontvangen segmenten, waarna ik ze overbracht naar het neurale netwerk. Alles is hier anders. Ten eerste, om op zijn minst gedeeltelijk de informatie te herstellen die verloren is gegaan na het verdelen van het beeld in verbindingscomponenten, schilder ik op elk van hen met een donkergrijze kleur (96) de "achtergrond" - wat naast het uitgesneden segment was, maar deed niet ingaan, waarna ik de contouren van symbolen gladstrijk met dezelfde procedure als in het voorproces voor lijnen (met een afstand tot de buurman gelijk aan één).
Formeel (vanuit het oogpunt van programmamodules) eindigt de segmentatie hier. De oplettende lezer moet gemerkt hebben dat nergens sprake was van de scheiding van plakkerige tekens. Ja, dit is zo - ik draag ze over voor erkenning in deze vorm, en ik maak ze ter plekke af.
De reden is dat de methode van het scheiden van aan elkaar geplakte tekens, die eerder werd beschreven (met de kleinste projectie), hier niet werkt - het lettertype is zeer goed gekozen door de auteurs. Daarom moeten we een andere, complexere aanpak kiezen. Deze benadering is gebaseerd op het idee dat: een neuraal netwerk kan worden gebruikt voor segmentatie.
Helemaal aan het begin heb ik een algoritme beschreven waarmee je het aantal tekens in een segment met een bekende breedte van dit segment en het totale aantal tekens kunt vinden. Ook hier wordt hetzelfde algoritme gebruikt. Voor elk segment wordt het aantal tekens erin berekend. Als hij daar alleen is, hoef je niets af te maken en wordt dit segment meteen >> = naar het neurale netwerk gestuurd. Als er meer dan één symbool is, worden potentiaalscheidingstekens op gelijke afstanden langs het segment geplaatst. Vervolgens beweegt elke separator in zijn eigen kleine buurt, en onderweg wordt de reactie van het neurale netwerk op symbolen in de buurt van deze separator berekend, waarna het alleen nog over is om het maximum te selecteren (in feite doet een nogal stom algoritme het daar allemaal, maar , in principe is alles echt ongeveer hetzelfde).
Uiteraard sluit de deelname van een neuraal netwerk aan het proces van segmentatie (of presegmentatie, zo je wilt) de mogelijkheid uit om het neurale netwerktrainingsschema te gebruiken dat ik al heb beschreven. Om precies te zijn, het staat je niet toe om het allereerste neurale netwerk te krijgen - het kan worden gebruikt om anderen te trainen. Daarom handel ik heel eenvoudig - ik gebruik de gebruikelijke segmentatiemethoden (projectie) om het neurale netwerk te trainen, terwijl bij gebruik het bovenstaande algoritme in het spel komt.
Er is nog een subtiliteit verbonden aan het gebruik van een neuraal netwerk in dit algoritme. In de vorige voorbeelden werd het neurale netwerk getraind op bijna onbewerkte preprocessing- en segmentatieresultaten. Hier kon niet meer dan 12% van de succesvolle erkenning worden behaald. Dit paste helemaal niet bij mij. Daarom heb ik, voordat ik aan het volgende tijdperk van neurale netwerktraining begon, verschillende vervormingen in de originele afbeeldingen geïntroduceerd, waarbij ik de echte ongeveer simuleerde: witte / grijze / zwarte stippen, grijze lijnen / cirkels / rechthoeken toevoegen, roteren. Ik heb ook het treinstel vergroot van 200 afbeeldingen naar 300 en de zogenaamde validset om de kwaliteit van de training tijdens de training te controleren voor 100 afbeeldingen. Hierdoor konden we een prestatieverbetering van ongeveer vijf procent bereiken, en samen met segmentatie door een neuraal netwerk gaf het net het resultaat waar ik het aan het begin van het artikel over had.
Het verstrekken van statistieken wordt bemoeilijkt door het feit dat ik eindigde met: twee neurale netwerken: de ene gaf een hoger percentage herkenning en de andere - een kleinere fout. Hier presenteer ik de resultaten van de eerste.
In totaal zaten er, zoals ik al vaker heb gezegd, 100 afbeeldingen in de testset. Hiervan werden er respectievelijk 20 met succes herkend, 80 waren niet succesvol en de fout was 1,91 tekens per afbeelding. Aanzienlijk slechter dan alle andere operators, maar de CAPTCHA is geschikt.
In plaats van een conclusie
Alles wat met dit werk te maken heeft, heb ik in een speciale forumthread op mijn website geplaatst, in het bijzonder: broncode, Netsukuku). Tegelijkertijd wil ik iets dat in de eerste plaats in een jaar kan worden gedaan (minimaal twee mensen), en ten tweede serieus een hoge plaats zou claimen bij dezelfde ISEF. Misschien kunnen jullie me vertellen welke kant ik op moet?
Goededag! Onlangs had ik voor sommige behoeften een Python-captcha nodig van "nieuwsgierige". Gekeken op google en niets normaals zonder Django zag niet. Hierdoor kwam ik tot de conclusie dat ik niet apart ga schrijven WSGI toepassing, maar gewoon CGI script.
Het pakket is gekozen voor het werken met afbeeldingen Python-beeldvormingsbibliotheek... Helaas biedt PIL wat magere mogelijkheden in vergelijking met: GD2 in PHP.
U kunt het pakket voor Python-versies 2 en 3 hier downloaden: http://www.lfd.uci.edu/~gohlke/pythonlibs/
Ik wil meteen opmerken dat het wordt gebruikt Python 3.1 hoewel ik denk dat het ook op Python 2.6+ zal draaien.
En dus zouden we uiteindelijk een afbeelding van 5-6 tekens op een veelkleurige achtergrond moeten genereren.
Aangezien ik hier niet het archief met alles klaar post, zullen we alles volgens de handleiding doen.
Directory's en hun hiërarchie:
Cgi-bin
—Captcha
—Achtergronden
—Lettertypen
—Index.py
Ik denk dat het hiermee duidelijk is dat er in de cgi-bin-map een captcha-map is met achtergronden en lettertypen en het index.py-script zelf.
Nu hebben we achtergronden nodig. We rijden "achtergronden" in Google Afbeeldingen en downloaden 15-20 stukjes. En je moet zulke rechthoeken 200x60 px maken in het formaat JPEG.
We gooien alles in de map met achtergronden.
Nu de lettertypen. We zijn geïnteresseerd in TrueType lettertypen (* .ttf). We nemen ongeveer 15 lettertypen en plaatsen deze in de map lettertypen.
Alle achtergronden zijn er, de lettertypen zijn er, nu index.py zelf.
Afdrukken ("Inhoudstype: afbeelding / jpeg"); afdrukken (""); import sys, os, re, random from PIL import Image, ImageFont, ImageDraw class captcha (object): def __init __ (self): self.string = ""; zelf.root = os.getcwd (); self.path_backgrounds = self.root + "/ backgrounds /"; self.path_fonts = self.root + "/ fonts /"; def gen_string (zelf): chars = ("a", "b", "d", "e", "f", "g", "h", "j", "m", "n", " q "," r "," t "," u "," y "," A "," B "," D "," E "," F "," G "," H "," J " , "M", "N", "Q", "R", "T", "U", "Y", "1", "2", "3", "4", "5", " 6 "," 7 "," 8 "," 9 "); voor i binnen bereik (random.randint (5, 6)): self.string + = tekens; retourneer zelf.string; def gen_backgrounds (zelf): afbeeldingen =; if os.path.exists (self.path_backgrounds): for f in os.listdir (self.path_backgrounds): if os.path.isdir (self.path_backgrounds + "/" + f): doorgaan; if re.search ("\. (jpeg | jpg) $", f, re.IGNORECASE): images.append (self.path_backgrounds + "/" + f); anders: sys.exit (); if len (afbeeldingen) == 0: sys.exit (); afbeeldingen retourneren; def gen_fonts (zelf): fonts =; if os.path.exists (self.path_fonts): voor f in os.listdir (self.path_fonts): if os.path.isdir (self.path_fonts + "/" + f): doorgaan; if re.search ("\. (ttf) $", f, re.IGNORECASE): fonts.append (self.path_fonts + "/" + f); anders: sys.exit (); if len (lettertypen) == 0: sys.exit (); lettertypen retourneren; def gen_image (zelf): string = zelf.gen_string (); achtergronden = self.gen_backgrounds (); lettertypen = zelf.gen_fonts (); image = Image.new ("RGB", (200,60), "#FFF") draw = ImageDraw.Draw (afbeelding); voor i in bereik (5): background = Image.open (backgrounds); x = willekeurig.randint (0, 160); cp = achtergrond.crop ((x, 0, x + 40, 60)); afbeelding.plakken (cp, (i * 40, 0)); if len (string) == 5: x = random.randint (25, 30); anders: x = willekeurig.randint (8, 11); voor char in string: font = fonts; y = willekeurig.randint (5, 25); font_size = willekeurig.randint (24, 30); color_dark = "rgb (" + str (random.randint (0,150)) + "," + str (random.randint (0,100)) + "," + str (random.randint (0,150)) + ")"; color_font = "rgb (" + str (random.randint (50.200)) + "," + str (random.randint (0,150)) + "," + str (random.randint (50.200)) + ")"; ttf = ImageFont.truetype (lettertype, lettergrootte) draw.text ((x + 1, y + 1), char, fill = color_dark, font = ttf) draw.text ((x, y), char, fill = color_font, lettertype = ttf) x + = willekeurig.randint (13, 15) + 18; afbeelding.save (sys.stdout, "JPEG") cp = captcha (); cp.gen_image (); # cp.tekenreeks; tekenreeks
Dat is alles. Ik heb een afbeelding gegenereerd op http://localhost/cgi-bin/captcha/index.py. Vervolgens kunt u een opslagmechanisme toevoegen voor de gegenereerde tekenreeks ( cp.string) met sessies of elders.
De meeste mensen weten het niet, maar mijn scriptie was een programma om tekst uit een afbeelding te lezen. Ik dacht dat als ik een hoog herkenningspercentage kon krijgen, het zou kunnen worden gebruikt om de zoekresultaten te verbeteren. Mijn uitstekende adviseur, Dr. Gao Junbing, stelde voor dat ik een proefschrift over dit onderwerp zou schrijven. Eindelijk heb ik de tijd gevonden om dit artikel te schrijven en hier zal ik proberen je te vertellen over alles wat ik heb geleerd. Was er maar zoiets toen ik voor het eerst begon...
Zoals ik al eerder zei, probeerde ik gewone afbeeldingen van internet te halen en er tekst uit te halen om de zoekresultaten te verbeteren. De meeste van mijn ideeën waren gebaseerd op captcha-hacktechnieken. Zoals iedereen weet, is captcha het erg irritante ding, zoals "Voer de letters in die je in de afbeelding ziet" op de registratie- of feedbackpagina's.
Captcha is zo ontworpen dat een persoon de tekst zonder moeite kan lezen, terwijl een machine dat niet kan (hallo, reCaptcha!). In de praktijk werkte dit nooit, aangezien bijna elke captcha die op de site werd gepost binnen enkele maanden werd gehackt.
Ik was er goed in - meer dan 60% van de afbeeldingen werd met succes ontcijferd uit mijn kleine verzameling. Best goed gezien het aantal verschillende afbeeldingen op internet.
In mijn onderzoek heb ik geen materiaal gevonden dat mij zou kunnen helpen. Ja, er zijn artikelen, maar die bevatten zeer eenvoudige algoritmen. Ik vond zelfs verschillende niet-werkende voorbeelden in PHP en Perl, nam er verschillende fragmenten uit en kreeg goede resultaten voor een heel eenvoudige captcha. Maar geen van hen hielp me veel, omdat het te gemakkelijk was. Ik ben een van die mensen die theorie kan lezen, maar niets begrijpt zonder echte voorbeelden. En in de meeste artikelen stond dat ze de code niet zouden publiceren, omdat ze bang waren dat deze voor slechte doeleinden zou worden gebruikt. Persoonlijk denk ik dat captcha tijdverspilling is, omdat het vrij eenvoudig te omzeilen is als je weet hoe.
Vanwege het ontbreken van materiaal dat captcha-hacking voor beginners laat zien, heb ik dit artikel geschreven.
Laten we beginnen. Hier is een lijst van wat ik in dit artikel ga behandelen:
- Gebruikte technologieën
- Wat is captcha
- AI-ondersteunde beeldherkenning
- Onderwijs
- Alles op een rijtje
- Resultaten en conclusies
Gebruikte technologieën
Alle voorbeelden zijn geschreven in Python 2.5 met behulp van de PIL-bibliotheek. Zou ook in Python 2.6 moeten werken.
Installeer ze in de bovenstaande volgorde en u bent klaar om de voorbeelden uit te voeren.
Toevluchtsoord
In de voorbeelden zal ik veel waarden hard coderen in de code. Mijn doel is niet om een universele captcha-herkenner te maken, maar alleen om te laten zien hoe het werkt.
Captcha, wat is het tenslotte?
In feite is een captcha een voorbeeld van een eenrichtingsconversie. Je kunt gemakkelijk een tekenset nemen en er een captcha van krijgen, maar niet andersom. Een andere subtiliteit is dat het gemakkelijk te lezen moet zijn door een mens, maar niet vatbaar voor machinale herkenning. Captcha kan worden gezien als een simpele "Ben je een mens?"-test. Kortom, ze worden geïmplementeerd als een afbeelding met een soort symbolen of woorden.
Ze worden gebruikt om spam op veel internetsites te voorkomen. Een captcha is bijvoorbeeld te vinden op de registratiepagina van Windows Live ID.
U krijgt een afbeelding te zien en als u echt een persoon bent, moet u de tekst ervan in een apart veld invoeren. Klinkt als een goed idee dat je kan beschermen tegen duizenden automatische registraties om Viagra te spammen of te verspreiden op je forum? Het probleem is dat AI, en met name de methoden van beeldherkenning, aanzienlijke veranderingen hebben ondergaan en op bepaalde gebieden zeer effectief worden. OCR (Optical Character Recognition) is tegenwoordig behoorlijk nauwkeurig en herkent gemakkelijk gedrukte tekst. Er werd besloten om wat kleur en lijnen toe te voegen om het moeilijk te maken voor de computer om te werken zonder enig ongemak voor de gebruikers. Dit is een soort wapenwedloop en zoals gewoonlijk komen ze met krachtigere wapens voor elke verdediging. Verbeterde captcha verslaan is moeilijker, maar nog steeds mogelijk. Bovendien moet de afbeelding vrij eenvoudig worden gehouden om gewone mensen niet te irriteren.
Deze afbeelding is een voorbeeld van een captcha die we gaan decoderen. Dit is een echte captcha die op een echte site wordt geplaatst.
Dit is een vrij simpele captcha die bestaat uit karakters van dezelfde kleur en grootte op een witte achtergrond met wat ruis (pixels, kleuren, lijnen). Je zou denken dat dit achtergrondgeluid het moeilijk maakt om het te herkennen, maar ik zal je laten zien hoe je het gemakkelijk kunt verwijderen. Hoewel dit geen erg sterke captcha is, is het een goed voorbeeld voor ons programma.
Tekst uit afbeeldingen zoeken en extraheren
Er zijn veel methoden om de positie van tekst in een afbeelding te bepalen en te extraheren. Met behulp van Google kun je duizenden artikelen vinden die nieuwe methoden en algoritmen voor het zoeken naar tekst uitleggen.
Voor dit voorbeeld gebruik ik kleurextractie. Dit is een vrij eenvoudige techniek waarmee ik behoorlijk goede resultaten heb behaald. Dit is de techniek die ik heb gebruikt voor mijn scriptie.
Voor onze voorbeelden zal ik het meerwaardige beelddecompositiealgoritme gebruiken. Dit betekent in feite dat we eerst een histogram van de kleuren van de afbeelding plotten. Dit wordt gedaan door alle pixels in de afbeelding te nemen, gegroepeerd op kleur, en vervolgens elke groep te tellen. Als je naar onze test-captcha kijkt, zie je drie primaire kleuren:
- Witte achtergrond)
- Grijs (ruis)
- Rood (tekst)
Het ziet er heel eenvoudig uit in Python.
De volgende code opent een afbeelding, converteert deze naar GIF (maakt het makkelijker voor ons, aangezien er maar 255 kleuren in zitten) en drukt een histogram van kleuren af.
Van PIL import Afbeelding im = Afbeelding.open ("captcha.gif") im = im.convert ("P") print im.histogram ()
Als resultaat krijgen we het volgende:
Hier zien we het aantal pixels voor elk van de 255 kleuren in de afbeelding. Je kunt zien dat wit (255, de meest recente) de meest voorkomende is. Het wordt gevolgd door rood (tekst). Om dit te verifiëren, laten we een klein script schrijven:
Van PIL-import Afbeelding van operator import itemgetter im = Image.open ("captcha.gif") im = im.convert ("P") his = im.histogram () waarden = () voor i binnen bereik (256) : waarden [i] = his [i] voor j, k in gesorteerd (values.items (), key = itemgetter (1), reverse = True) [: 10]: print j, k
En we krijgen de volgende gegevens:
Dit is een lijst van de 10 meest voorkomende kleuren in een afbeelding. Zoals verwacht wordt wit het meest herhaald. Dan zijn er grijs en rood.
Zodra we deze informatie hebben, maken we nieuwe afbeeldingen op basis van deze kleurgroepen. Voor elk van de meest voorkomende kleuren maken we een nieuwe binaire afbeelding (van 2 kleuren) waarbij de pixels van die kleur worden gevuld met zwart en al het andere met wit.
We hebben rood als de derde meest voorkomende kleur, wat betekent dat we een groep pixels willen behouden met een kleur van 220. Toen ik experimenteerde, ontdekte ik dat kleur 220 vrij dicht bij 220 ligt, dus we zullen die groep pixels behouden ook. De onderstaande code opent de captcha, converteert deze naar GIF, maakt een nieuwe afbeelding van dezelfde grootte met een witte achtergrond en doorloopt vervolgens de originele afbeelding op zoek naar de gewenste kleur. Als het een pixel vindt met de kleur die we nodig hebben, markeert het dezelfde pixel in de tweede afbeelding met zwart. Voordat het werk wordt voltooid, wordt de tweede afbeelding opgeslagen.
Van PIL import Afbeelding im = Afbeelding.open ("captcha.gif") im = im.convert ("P") im2 = Afbeelding.new ("P", im.size, 255) im = im.convert ("P ") temp = () voor x binnen bereik (im.grootte): voor y binnen bereik (im.grootte): pix = im.getpixel ((y, x)) temp = pix if pix == 220 of pix == 227: # dit zijn de nummers om im2.putpixel ((y, x), 0) im2.save ("output.gif") te krijgen
Het uitvoeren van dit stuk code geeft ons de volgende uitvoer.
Op de afbeelding kunt u zien dat het ons is gelukt om de tekst uit de achtergrond te halen. Om dit proces te automatiseren, kunt u het eerste en tweede script combineren.
Ik hoor je vragen: "Wat als de tekst op de captcha in verschillende kleuren is geschreven?" Ja, onze techniek kan nog steeds werken. Stel dat de meest voorkomende kleur de achtergrondkleur is en dan kun je de kleuren van de karakters vinden.
Tot nu toe hebben we de tekst met succes uit de afbeelding gehaald. De volgende stap is om te bepalen of de afbeelding tekst bevat. Ik zal hier nog geen code schrijven, omdat dit het begrijpen moeilijk maakt, terwijl het algoritme zelf vrij eenvoudig is.
Voor elke binaire afbeelding: voor elke pixel in de binaire afbeelding: als de pixel aan staat: als een pixel die we eerder hebben gezien ernaast staat: toevoegen aan dezelfde set anders: toevoegen aan een nieuwe set
Als gevolg hiervan heb je een reeks karaktergrenzen. Dan hoef je ze alleen maar met elkaar te vergelijken en te kijken of ze opeenvolgend gaan. Zo ja, dan heb je de jackpot gekregen en heb je de symbolen die ernaast staan correct geïdentificeerd. U kunt ook de afmetingen van de verkregen gebieden controleren of gewoon een nieuwe afbeelding maken en deze laten zien (de methode show () van de afbeelding) om er zeker van te zijn dat het algoritme nauwkeurig is.
Van PIL import Afbeelding im = Afbeelding.open ("captcha.gif") im = im.convert ("P") im2 = Afbeelding.new ("P", im.size, 255) im = im.convert ("P ") temp = () voor x binnen bereik (im.grootte): voor y binnen bereik (im.grootte): pix = im.getpixel ((y, x)) temp = pix if pix == 220 of pix == 227: # dit zijn de cijfers om im2.putpixel ((y, x), 0) te krijgen # nieuwe code begint hier inletter = False foundletter = False start = 0 end = 0 letters = voor y binnen bereik (im2.size): # slice over voor x binnen bereik (im2.size): # slice down pix = im2.getpixel ((y, x)) if pix! = 255: inletter = True if foundletter == False en inletter == True: foundletter = True start = y if foundletter == True en inletter == False: foundletter = False end = y letters.append ((start, end)) inletter = False print letters
Als resultaat kregen we het volgende:
[(6, 14), (15, 25), (27, 35), (37, 46), (48, 56), (57, 67)]
Dit zijn de horizontale posities van het begin en einde van elk teken.
AI en vectorruimte in patroonherkenning
Beeldherkenning kan worden beschouwd als het grootste succes van moderne AI, waardoor het kan worden ingebed in allerlei commerciële toepassingen. Postcodes zijn hier een goed voorbeeld van. In veel landen worden ze zelfs automatisch gelezen, omdat het een vrij eenvoudige taak is om een computer getallen te leren herkennen. Het is misschien niet voor de hand liggend, maar patroonherkenning wordt beschouwd als een AI-probleem, zij het een zeer gespecialiseerd probleem.
Neurale netwerken zijn bijna het eerste dat je tegenkomt als je kennis maakt met AI in patroonherkenning. Persoonlijk heb ik nooit enig succes gehad met neurale netwerken in karakterherkenning. Ik leer hem meestal 3-4 symbolen, waarna de nauwkeurigheid zo laag wordt dat het een orde van grootte hoger zou zijn als ik de symbolen willekeurig raad. In het begin veroorzaakte dit bij mij een lichte paniek, omdat het de ontbrekende schakel in mijn scriptie was. Gelukkig las ik onlangs een artikel over vectorruimtezoekmachines en beschouwde ik ze als een alternatieve methode voor het classificeren van gegevens. Uiteindelijk bleken ze de beste keuze, want.
- Ze vereisen geen uitgebreide studie.
- U kunt onjuiste gegevens toevoegen/verwijderen en direct het resultaat zien
- Ze zijn gemakkelijker te begrijpen en te programmeren.
- Ze bieden geclassificeerde resultaten, zodat u de top X-overeenkomsten kunt zien
- Herken je iets niet? Voeg het toe en je kunt het meteen herkennen, zelfs als het totaal anders is dan iets dat je eerder hebt gezien.
Natuurlijk is er geen gratis kaas. Het grootste nadeel is snelheid. Ze kunnen veel langzamer zijn dan neurale netwerken. Maar ik denk dat hun voordelen nog steeds opwegen tegen dit nadeel.
Als je wilt begrijpen hoe vectorruimte werkt, raad ik je aan om de theorie van vectorruimtezoekmachines te lezen. Dit is de beste die ik heb gevonden voor beginners.
Ik bouwde mijn beeldherkenning op basis van het bovenstaande document en dit was het eerste dat ik probeerde te schrijven in mijn favoriete programmeertaal die ik op dat moment studeerde. Lees dit document en u zult de essentie ervan begrijpen - kom hier terug.
Al terug? Oke. Nu moeten we onze vectorruimte programmeren. Gelukkig is dit helemaal niet moeilijk. Laten we beginnen.
Wiskundeklasse importeren VectorCompare: def magnitude (zelf, concordantie): totaal = 0 voor woord, aantal in concordance.iteritems (): totaal + = aantal ** 2 return math.sqrt (totaal) def relatie (zelf, concordance1, concordantie2) : relevantie = 0 topwaarde = 0 voor woord, aantal in concordance1.iteritems (): if concordance2.has_key (woord): topwaarde + = aantal * concordance2 retourneer topwaarde / (self.magnitude (concordance1) * self.magnitude (concordance2))
Dit is een 15-regelige implementatie van vectorruimte in Python. In wezen zijn er slechts 2 woordenboeken nodig en wordt een getal tussen 0 en 1 weergegeven om aan te geven hoe ze gerelateerd zijn. 0 betekent dat ze niet gerelateerd zijn, en 1 betekent dat ze identiek zijn.
Onderwijs
Het volgende dat we nodig hebben, is een reeks afbeeldingen waarmee we onze symbolen zullen vergelijken. We hebben een leerpakket nodig. Deze set kan worden gebruikt om elke vorm van AI te trainen die we zullen gebruiken (neurale netwerken, enz.).
De gebruikte gegevens kunnen cruciaal zijn voor het succes van de herkenning. Hoe beter de data, hoe groter de kans op succes. Aangezien we van plan zijn een specifieke captcha te herkennen en er al symbolen uit kunnen halen, waarom zouden we ze dan niet als trainingsset gebruiken?
Dit is wat ik deed. Ik heb veel gegenereerde captcha's gedownload en mijn programma brak ze in letters. Vervolgens verzamelde ik de resulterende afbeeldingen in een verzameling (groep). Na verschillende pogingen had ik ten minste één voorbeeld van elk teken dat de captcha had gegenereerd. Het toevoegen van meer voorbeelden zal de herkenningsnauwkeurigheid vergroten, maar dit was genoeg voor mij om mijn theorie te bevestigen.
Van PIL import Image import hashlib import time im = Image.open ("captcha.gif") im2 = Image.new ("P", im.size, 255) im = im.convert ("P") temp = () print im.histogram () voor x binnen bereik (im.grootte): voor y binnen bereik (im.grootte): pix = im.getpixel ((y, x)) temp = pix if pix == 220 of pix == 227: # dit zijn de getallen om im2.putpixel te krijgen ((y, x), 0) inletter = False foundletter = False start = 0 end = 0 letters = voor y binnen bereik (im2.size): # slice over voor x binnen bereik (im2.size): # slice down pix = im2.getpixel ((y, x)) if pix! = 255: inletter = True if foundletter == False en inletter == True: foundletter = True start = y if foundletter == True en inletter == False: foundletter = False end = y letters.append ((start, end)) inletter = False # Nieuwe code is hier. We extraheren elke afbeelding en slaan deze op schijf op met # wat hopelijk een unieke naam is count = 0 voor letter in letters: m = hashlib.md5 () im3 = im2.crop ((letter, 0, letter, im2.size) ) m.update ("% s% s"% (time.time (), count)) im3.save ("./% s.gif"% (m.hexdigest ())) count + = 1
Als resultaat krijgen we een set afbeeldingen in dezelfde map. Elk van hen krijgt een unieke hash toegewezen voor het geval u meerdere captcha's gaat verwerken.
Hier is het resultaat van deze code voor onze test-captcha:
Jij bepaalt hoe je deze afbeeldingen opslaat, maar ik zet ze gewoon in een map met dezelfde naam als in de afbeelding (symbool of nummer).
Alles op een rijtje
Laatste stap. We hebben tekstextractie, karakterextractie, herkenningstechniek en trainingsset.
We krijgen een captcha-afbeelding, selecteren de tekst, krijgen de symbolen en vergelijken ze met onze trainingsset. Je kunt het definitieve programma met een tutorial set en enkele captcha's downloaden via deze link.
Hier laden we gewoon de trainingsset om ermee te kunnen vergelijken:
Def buildvector (im): d1 = () count = 0 for i in im.getdata (): d1 = i count + = 1 return d1 v = VectorCompare () iconset = ["0", "1", "2" , "3", "4", "5", "6", "7", "8", "9", "0", "a", "b", "c", "d", " e "," f "," g "," h "," i "," j "," k "," l "," m "," n "," o "," p "," q " , "r", "s", "t", "u", "v", "w", "x", "y", "z"] imageset = voor letter in iconset: voor img in os.listdir ("./iconset/%s/"%(letter)): temp = if img! =" Thumbs.db ": temp.append (buildvector (Image.open (" ./ iconset /% s /% s "% (letter, img)))) imageset.append ((letter: temp))
En dan gebeurt alle magie. We zoeken uit waar elk symbool is en valideren het met onze vectorruimte. Vervolgens sorteren we de resultaten en printen ze uit.
Count = 0 voor letter in letters: m = hashlib.md5 () im3 = im2.crop ((letter, 0, letter, im2.size)) gok = voor afbeelding in afbeeldingenset: voor x, y in afbeelding.iteritems () : if len (y)! = 0: guess.append ((v.relation (y, buildvector (im3)), x)) guess.sort (reverse = True) print "", Guess count + = 1
conclusies
Nu hebben we alles wat we nodig hebben en kunnen we proberen onze wondermachine te starten.
Het invoerbestand is captcha.gif. Verwachte uitvoer: 7s9t9j
Python crack.py (0,96376811594202894, "7") (0,96234028545977002, "s") (0,9286884286888929, "9") (0,98350370609844473, "t") (0,96751165072506273, "9") (0,96989711688772628, 0,96989711688772628
Hier zien we het bedoelde symbool en de mate van vertrouwen dat het echt is (van 0 tot 1).
Het lijkt erop dat we het echt hebben gedaan!
In feite zal dit script bij test-captcha's in ongeveer 22% van de gevallen een succesvol resultaat opleveren.
Python crack_test.py Correcte schattingen - 11.0 Verkeerde schattingen - 37.0 Percentage correct - 22.9166666667 Percentage fout - 77.08333333333
De meeste van de onjuiste resultaten zijn te wijten aan de onjuiste herkenning van het cijfer "0" en de letter "O". Er is niets onverwachts, want zelfs mensen verwarren ze vaak. We hebben nog steeds een probleem met het splitsen van tekens, maar dit kan eenvoudig worden opgelost door het splitsresultaat te controleren en een middenweg te vinden.
Maar zelfs met zo'n niet erg perfect algoritme, kunnen we elke vijfde captcha in zo'n tijd oplossen, waar een persoon geen tijd zou hebben om er zelfs maar één op te lossen.
Het uitvoeren van deze code op een Core 2 Duo E6550 geeft de volgende resultaten:
Echte 0m5.750s gebruiker 0m0.015s sys 0m0.000s
Onze catalogus bevat 48 captcha's, wat betekent dat het ongeveer 0,12 seconden duurt om er een op te lossen. Met ons slagingspercentage van 22% kunnen we ongeveer 432.000 captcha's per dag oplossen en 95.040 correcte resultaten krijgen. Hoe zit het met multithreading?
Dat is alles. Ik hoop dat mijn ervaring door u voor goede doeleinden zal worden gebruikt. Ik weet dat je deze code kunt beschadigen, maar om iets echt gevaarlijks te doen, moet je hem behoorlijk veranderen.
Voor degenen die zichzelf proberen te beschermen met captcha's, kan ik zeggen dat dit je niet veel zal helpen, omdat ze programmatisch kunnen worden omzeild of gewoon andere mensen kunnen betalen die ze handmatig zullen oplossen. Overweeg andere manieren om uzelf te beschermen.
Ik besloot Python een beetje onder de knie te krijgen, maar het beheersen van "gewoon niet pkhp" is niet interessant. Eigenbelang is geworden automatisch oplossende captcha Python.
Het begon met een post uit 2012 (grafische bibliotheek in het algemeen in 2009).
Code: https://habrahabr.ru/post/149091/
Ik heb 2.7.10 uit de doos en de code is geschreven onder 2.5 (met een van beide PIL). Ze schrijven dat 2.7.3 prima werkt.
PIL rolde zo
Code: # downloaden
curl -O -L http://effbot.org/media/downloads/Imaging-1.1.7.tar.gz
# extract
tar -xzf Imaging-1.1.7.tar.gz
cd-beeldvorming-1.1.7
# bouwen en installeren
python setup.py bouwen
sudo python setup.py installeren
# of installeer het alleen voor jou zonder beheerdersrechten:
# python setup.py install --user
Toen heb ik de module als volgt geïmporteerd
Code: # typ in de console
Python
# schakel de tolk in die u opdracht geeft
importeer PIL
# als alles in orde is, drukt u op Ctrl + D om af te sluiten
De slang is niet vriendelijk met het Cyrillische alfabet, hij heeft een constructie toegevoegd aan het begin van het bestand (om het mogelijk te maken om commentaar op het vaartuig in het Cyrillisch te geven)
Code: # - * - codering: utf-8 - * -
Hier is de fiets zelf (ik kan geen loops schrijven en ik weet niet hoe ik moet evalueren, dus ik heb veel met mijn handen vervangen).
Code: # - * - codering: utf-8 - * -
# deze shit is nodig voor Russische karakters
van PIL import Afbeelding
van operator itemgetter importeren
im = im.convert ("P")
zijn = im.histogram ()
waarden = ()
voor i binnen bereik (256):
waarden [i] = zijn [i]
voor j, k in gesorteerd (values.items (), key = itemgetter (1), reverse = True) [: 15]:
print "or pix ==", j #, k
# variabele j slaat tien populairste kleuren op
van PIL import Afbeelding
im = Afbeelding.open ("captcha.gif")
im = im.convert ("P")
im = im.convert ("P")
voor x binnen bereik (im.grootte):
voor y binnen bereik (im.grootte):
pix = im.getpixel ((y, x))
temp = pix
# kleur hier
im2.putpixel ((y, x), 0)
im2.save ("output.gif")
# hier lijkt alles weer voorbij te zijn
van PIL import Afbeelding
im = Afbeelding.open ("output.gif")
im = im.convert ("P")
im2 = Image.new ("P", im.size, 255)
im = im.convert ("P")
voor x binnen bereik (im.grootte):
voor y binnen bereik (im.grootte):
pix = im.getpixel ((y, x))
temp = pix
if pix == 255: # dit zijn de nummers die je moet krijgen
im2.putpixel ((y, x), 0)
# nieuwe code begint hier
inletter = False
gevondenletter = False
begin = 0
einde = 0
pix = im2.getpixel ((y, x))
als pix! = 255:
inletter = True
gevondenletter = True
begin = ja
gevondenletter = False
einde = y
letters.toevoegen ((begin, einde))
Inletter = Onwaar
brieven afdrukken
#fig weet het
klasse VectorVergelijk:
def magnitude (zelf, concordantie):
totaal = 0
voor woord, tel in concordance.iteritems ():
totaal + = aantal ** 2
return math.sqrt (totaal)
Def relatie (zelf, concordantie1, concordantie2):
relevantie = 0
topwaarde = 0
voor woord, tel in concordance1.iteritems ():
if concordance2.has_key (woord):
topwaarde + = aantal * concordantie2
retourneer topwaarde / (zelf.magnitude (concordance1) * self.magnitude (concordance2))
# karakterset
van PIL import Afbeelding
hashlib importeren
import tijd
im = Afbeelding.open ("captcha.gif")
im2 = Image.new ("P", im.size, 255)
im = im.convert ("P")
afdruk im.histogram ()
voor x binnen bereik (im.grootte):
voor y binnen bereik (im.grootte):
pix = im.getpixel ((y, x))
temp = pix
# kleur hier
if pix == 187 of pix == 224 of pix == 188 of pix == 223 of pix == 145 of pix == 151 of pix == 181 of pix == 144 of pix == 225 of pix == 182 of pix == 189 of pix == 12 of pix == 17 of pix == 139 of pix == 152: # of pix ==
im2.putpixel ((y, x), 0)
inletter = False
gevondenletter = False
begin = 0
einde = 0
voor y binnen bereik (im2.size): # slice over
voor x binnen bereik (im2.size): # slice down
pix = im2.getpixel ((y, x))
# het was "niet gelijk aan 255", dat wil zeggen - het was "niet gelijk aan wit"
als pix == 255:
inletter = True
If foundletter == False en inletter == True:
gevondenletter = True
begin = ja
If foundletter == True en inletter == False:
gevondenletter = False
einde = y
letters.toevoegen ((begin, einde))
inletter = False
# Nieuwe code is hier. We extraheren gewoon elke afbeelding en slaan deze op schijf op met
# wat is hopelijk een unieke naam
aantal = 0
voor letter in letters:
m = hashlib.md5 ()
im3 = im2.crop ((letter, 0, letter, im2.size))
m.update ("% s% s"% (tijd.tijd (), aantal))
im3.save ("./% s.gif"% (m.hexdigest ()))
tel + = 1
Het werkingsprincipe is als volgt: maak een histogram, verwijder de meest voorkomende tinten, sla de rest opnieuw op in zwart-wit, doorbreek de grenzen van symbolen, vergelijk symbolen met voorbeelden.
Originele captcha, geen 10 populaire tinten, geen 15 populaire tinten (ik heb het niet onderverdeeld in symbolen - omdat er een niet-geheel symbool is).
Originele captcha, zonder 15 populaire tinten, opgesplitst in 2 karakters (vies).
Onder een eenvoudige captcha is het heel goed mogelijk om een gissing op te schrijven. We hebben interessante plaatsen nodig met eenvoudige captcha's om af te werken en te rennen.
Er zijn verschillende manieren om de CAPTCHA's die sites beveiligen te omzeilen. Ten eerste zijn er speciale diensten die goedkope handarbeid gebruiken en aanbieden om letterlijk 1000 captcha's op te lossen voor $ 1. Als alternatief kunt u proberen een intelligent systeem te schrijven dat, volgens bepaalde algoritmen, de herkenning zelf zal uitvoeren. Dit laatste kan nu worden geïmplementeerd met een speciaal hulpprogramma.
Captcha oplossen
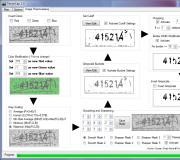
Het herkennen van CAPTCHA's is vaak een niet-triviale taak. Het is noodzakelijk om veel verschillende filters op het beeld op te leggen om vervorming en interferentie te verwijderen, waardoor ontwikkelaars de beschermingsweerstand willen versterken. Vaak moet je een trainbaar systeem implementeren op basis van neurale netwerken (dit is overigens niet zo moeilijk als het lijkt) om een acceptabel resultaat te bereiken voor de geautomatiseerde oplossing van captcha's. Om te begrijpen waar ik het over heb, is het beter om het archief te openen en de prachtige artikelen te lezen "Captcha hacken: theorie en praktijk. Begrijpen hoe captcha's worden verbroken ”en“ Laten we eens kijken en herkennen. Hacking Captcha-filters "van respectievelijk # 135 en # 126 nummers. Vandaag wil ik je vertellen over de ontwikkeling van TesserCap, die de auteur een universele CAPTCHA-oplosser noemt. Vreemde zaak, wat men ook mag zeggen.Eerste blik op TesserCap
Wat deed de auteur van het programma? Hij bekeek hoe het probleem van een geautomatiseerde CAPTCHA-oplossing meestal wordt benaderd en probeerde deze ervaring samen te vatten in één tool. De auteur merkte op dat om ruis uit de afbeelding te verwijderen, dat wil zeggen om het moeilijkste probleem bij het herkennen van captcha's op te lossen, dezelfde filters het vaakst worden gebruikt. Het blijkt dat als je een handig hulpmiddel implementeert waarmee je filters op afbeeldingen kunt toepassen zonder complexe wiskundige transformaties, en het combineert met een OCR-systeem voor tekstherkenning, je een volledig werkbaar programma kunt krijgen. Dit is in feite gedaan door Gursev Singh Kalra van McAfee. Waarom was het nodig? De auteur van het hulpprogramma besloot te controleren hoe veilig de captcha's van grote bronnen zijn. Voor het testen hebben we de internetsites geselecteerd die het meest worden bezocht volgens de versie van de bekende statistiekenservice. Monsters zoals Wikipedia, eBay en captcha-aanbieder reCaptcha kwamen in aanmerking voor tests. Als we in algemene termen kijken naar het principe van de werking van het programma, dan is het vrij eenvoudig. De originele captcha gaat naar het beeldvoorverwerkingssysteem, dat de captcha ontdoet van ruis en vervormingen en het resulterende beeld langs de transportband doorgeeft aan het OCR-systeem, dat de tekst erop probeert te herkennen. TesserCap heeft een interactieve grafische interface en heeft de volgende eigenschappen:- Heeft een veelzijdig beeldvoorverwerkingssysteem dat voor elke individuele captcha kan worden geconfigureerd.
- Bevat Tesseract-herkenningsengine die tekst extraheert uit een eerder geparseerde en weergegeven CAPTCHA-afbeelding.
- Ondersteunt het gebruik van verschillende coderingen in het herkenningssysteem.
 Voorbewerking en extractie van afbeeldingen
Voorbewerking en extractie van afbeeldingen tekst van captcha
Over
We konden niet anders dan een paar woorden zeggen over de auteur van het geweldige hulpprogramma TesserCap. Zijn naam is Gursev Singh Kalra. Hij is Principal Consultant voor Foundstone Professional Services, een dochteronderneming van McAfee. Gursev heeft gesproken op conferenties zoals ToorCon, NullCon en ClubHack. Hij is de auteur van de tools TesserCap en SSLSmart. Daarnaast ontwikkelde hij verschillende tools voor de interne behoeften van het bedrijf. Favoriete programmeertalen zijn Ruby, Ruby on Rails en C#. Foundstone® Professional Services, waar hij werkt, biedt organisaties expertise en training om ervoor te zorgen dat hun bedrijfsmiddelen voortdurend en effectief worden beschermd tegen de meest urgente bedreigingen. Het Professional Services-team bestaat uit gerenommeerde beveiligingsexperts en -ontwikkelaars met uitgebreide ervaring in het werken met multinationale ondernemingen en de overheidKoppel. Hoofdtabblad
Na het starten van het programma krijgen we een venster te zien met drie tabbladen: Main, Options, Image Preprocessing. Het hoofdtabblad bevat bedieningselementen die worden gebruikt om de CAPTCHA-beeldtest te starten en te stoppen, teststatistieken te genereren (hoeveel geraden en hoeveel niet), te navigeren en een afbeelding te selecteren voor voorbewerking. Het URL-invoerveld (controle # 1) moet de exacte URL bevatten die de webtoepassing gebruikt om de captcha's op te halen. De URL kan worden verkregen door op de rechterkant van de CAPTCHA-afbeelding te klikken, de paginacode te kopiëren of te bekijken en de URL te extraheren uit het src-attribuut van de ..site / common / rateit / captcha.asp?-afbeeldingstag. Naast de adresregel is er een element dat het aantal captcha's instelt dat moet worden geladen om te testen. Omdat de applicatie slechts 12 afbeeldingen tegelijk kan weergeven, biedt het bedieningselementen voor het pagina-voor-pagina scrollen van gedownloade captcha's. Tijdens grootschalige tests kunnen we dus door de gedownloade captcha's scrollen en de resultaten van hun herkenning bekijken. De Start- en Stop-knoppen starten en stoppen respectievelijk met testen. Na het testen moet u de resultaten van beeldherkenning evalueren en ze allemaal als correct of onjuist markeren. Welnu, de laatste, de belangrijkste functie wordt gebruikt om elk beeld over te brengen naar het voorverwerkingssysteem, waarin een filter wordt ingesteld dat ruis en vervorming uit het beeld verwijdert. Om een afbeelding naar het preprocessing-systeem te sturen, klikt u met de rechtermuisknop op de gewenste afbeelding en selecteert u het item Send To Image Preprocessor in het contextmenu.Koppel. Tabblad Opties
Het tabblad opties bevat verschillende bedieningselementen voor het configureren van de TesserCap. Hier kunt u het OCR-systeem selecteren, de webproxy-instellingen instellen, het doorsturen en voorverwerken van afbeeldingen inschakelen, aangepaste HTTP-headers toevoegen en het tekenbereik voor het OCR-systeem specificeren: cijfers, kleine letters, hoofdletters, speciale tekens. Nu over elke optie in meer detail. Allereerst kun je een OCR-systeem kiezen. Standaard is er maar één beschikbaar - Tesseract-ORC, dus u hoeft zich hier geen zorgen te maken over een keuze. Een ander zeer interessant kenmerk van het programma is de keuze uit een reeks karakters. Neem bijvoorbeeld een captcha van een site - u kunt zien dat deze geen enkele letter bevat, maar alleen uit cijfers. Dus waarom hebben we extra tekens nodig die de kans op onjuiste herkenning alleen maar vergroten? Maar hoe zit het met de hoofdletters? Kan het programma een captcha herkennen die bestaat uit hoofdletters van welke taal dan ook? Nee ik kan niet. Het programma haalt een lijst met tekens die worden gebruikt voor herkenning uit de configuratiebestanden in \ Program Files \ Foundstone Free Tools \ TesserCap 1.0 \ tessdata \ configs. Laat me het uitleggen aan de hand van een voorbeeld: als we de opties Numeriek en Kleine letters hebben geselecteerd, verwijst het programma naar het lagere numerieke bestand dat begint met de parameter tessedit char witte lijst. Dit wordt gevolgd door een lijst met symbolen die zullen worden gebruikt om de captcha op te lossen. Standaard bevatten bestanden alleen letters van het Latijnse alfabet, dus om het Cyrillische alfabet te herkennen, moet u de lijst met tekens vervangen of aanvullen. Nu een beetje over waar het veld Http Request Headers voor is. Op sommige websites moet je bijvoorbeeld inloggen om de captcha te zien. Om TesserCap toegang te geven tot de captcha, moet het programma de HTTP-verzoekheaders zoals Accept, Cookie en Referrer, enz. doorgeven. Met behulp van een webproxy (Fiddler, Burp, Charles, WebScarab, Paros, enz.), kunt u onderschep de verzonden verzoekheaders en voer ze in het invoerveld Http Request Headers in. Een andere optie die zeker van pas zal komen, is Follow Redirects. Het punt is dat TesserCap standaard geen omleidingen volgt. Als de test-URL de omleiding moet volgen om de afbeelding te krijgen, moet u deze optie selecteren. Welnu, de laatste optie blijft, die het beeldvoorverwerkingsmechanisme in- of uitschakelt, wat we verder zullen overwegen. Voorbewerking van afbeeldingen is standaard uitgeschakeld. Gebruikers stellen eerst beeldvoorbewerkingsfilters in volgens de geteste CAPTCHA-beelden en activeren vervolgens deze module. Alle CAPTCHA-afbeeldingen die worden geladen nadat de optie Voorverwerking van afbeeldingen inschakelen is ingeschakeld, worden voorverwerkt en vervolgens doorgegeven aan het Tesseract OCR-systeem voor tekstextractie.Koppel. Tabblad Voorbewerking van afbeeldingen
Nou, we zijn bij het meest interessante tabblad gekomen. Hier worden filters geconfigureerd om verschillende geluiden en vervaging van captcha's te verwijderen, die de taak van het herkenningssysteem zoveel mogelijk proberen te compliceren. Het opzetten van een universeel filter is uiterst eenvoudig en bestaat uit negen stappen. In elke fase van de beeldvoorbewerking worden de wijzigingen weergegeven. Bovendien heeft de pagina een validatiecomponent waarmee u de juistheid van captcha-herkenning kunt evalueren wanneer een filter wordt toegepast. Laten we elke fase in detail bekijken. Fase 1. Kleurinversie Deze stap keert de pixelkleuren voor de CAPTCHA-afbeeldingen om. De onderstaande code laat zien hoe dit gebeurt: for (elke pixel in CAPTCHA) (if (invertRed is true) new red = 255 - current red if (invertBlue is true) new blue = 255 - current blue if (invertGreen is true ) new green = 255 - huidig groen) Het omkeren van een of meer kleuren opent vaak nieuwe mogelijkheden voor het valideren van een geteste CAPTCHA. Fase 2. Kleurverandering Bij deze stap kunt u de kleurcomponenten voor alle pixels in de afbeelding wijzigen. Elk numeriek veld kan 257 ( 1 tot 255) mogelijke waarden bevatten. Voor RGB-componenten van elke pixel worden, afhankelijk van de waarde in het veld, de volgende acties uitgevoerd:- Als de waarde -1 is, verandert de corresponderende kleurcomponent niet.
- Als de waarde niet -1 is, worden alle gevonden componenten van de opgegeven kleur (rood, groen of blauw) gewijzigd volgens de waarde die in de velden is ingevoerd. Een waarde van 0 verwijdert de component, een waarde van 255 stelt de maximale intensiteit in, enzovoort.
- Gemiddeld -> (Rood + Groen + Blauw) / 3.
- Mens -> (0,21 * Rood + 0,71 * Groen + 0,07 * Blauw).
- Gemiddelde van minimale en maximale kleurcomponenten -> (Minimum (Rood + Groen + Blauw) + Maximum (Rood + Groen + Blauw)) / 2.
- Minimum -> Minimum (Rood + Groen + Blauw).
- Maximaal -> Maximaal (Rood + Groen + Blauw).
 Fase 4. Anti-aliasing en verscherping Om het moeilijker te maken om tekst uit CAPTCHA-afbeeldingen te extraheren, wordt er ruis aan toegevoegd in de vorm van stippen van één of meerdere pixels, vreemde lijnen en ruimtelijke vervorming. Wanneer het beeld wordt afgevlakt, neemt willekeurige ruis toe, die vervolgens wordt geëlimineerd door Bucket- of Cutoff-filters. In het numerieke veld Passes moet u specificeren hoe vaak het bijbehorende afbeeldingsmasker moet worden toegepast voordat u doorgaat naar de volgende stap. Laten we eens kijken naar de filtercomponenten voor afvlakking en verscherping. Er zijn twee soorten afbeeldingsmaskers beschikbaar:
Fase 4. Anti-aliasing en verscherping Om het moeilijker te maken om tekst uit CAPTCHA-afbeeldingen te extraheren, wordt er ruis aan toegevoegd in de vorm van stippen van één of meerdere pixels, vreemde lijnen en ruimtelijke vervorming. Wanneer het beeld wordt afgevlakt, neemt willekeurige ruis toe, die vervolgens wordt geëlimineerd door Bucket- of Cutoff-filters. In het numerieke veld Passes moet u specificeren hoe vaak het bijbehorende afbeeldingsmasker moet worden toegepast voordat u doorgaat naar de volgende stap. Laten we eens kijken naar de filtercomponenten voor afvlakking en verscherping. Er zijn twee soorten afbeeldingsmaskers beschikbaar: - Vaste maskers. TesserCap heeft standaard zes van de meest populaire afbeeldingsmaskers. Deze maskers kunnen het beeld gladmaken of verscherpen (Laplace-transformatie). Wijzigingen worden direct weergegeven na het selecteren van een masker met behulp van de bijbehorende knoppen.
- Aangepaste afbeeldingsmaskers. De gebruiker kan ook aangepaste maskers voor beeldverwerking instellen door waarden in de numerieke velden in te voeren en op de knop Masker opslaan te klikken. als de som van de coëfficiënten in deze vensters kleiner is dan nul, wordt een fout gegenereerd en wordt het masker niet toegepast. Als u een vast masker selecteert, hoeft u de knop Masker opslaan niet te gebruiken.
- Laat het zoals het is.
- Vervang door wit.
- Vervang door zwart.
Captcha herkennen
Nou, misschien hebben we alle opties van dit hulpprogramma overwogen, en nu zou het leuk zijn om wat captcha te testen op sterkte .. Het resultaat van de analyse van de captcha-site met een voorlopige
Het resultaat van de analyse van de captcha-site met een voorlopige afbeelding verwerken. Op basis van de resultaten, het filter
kon niet worden gevonden Start het hulpprogramma en ga naar de website van het tijdschrift. We zien een lijst met vers nieuws, ga naar de eerste die tegenkomt en scroll naar de plek waar je je reactie kunt achterlaten. Ja, het is niet zo eenvoudig om een opmerking toe te voegen (natuurlijk, anders zouden ze alles voor een lange tijd spammen) - je moet een captcha invoeren. Laten we eens kijken of dit geautomatiseerd kan worden. Kopieer de URL van de afbeelding en plak deze in de adresbalk van TesserCap. We geven aan dat je 12 captcha's moet downloaden en op Start moet klikken. Het programma uploadde plichtsgetrouw 12 foto's en probeerde ze te herkennen. Helaas werden alle captcha's ofwel niet herkend, zoals blijkt uit de -Mislukte- inscriptie eronder, ofwel werden ze onjuist herkend. Over het algemeen is het niet verrassend, aangezien externe ruis en vervorming niet zijn verwijderd. Dit is wat we nu gaan doen. Klik met de rechtermuisknop op een van de 12 geüploade afbeeldingen en stuur deze naar de Send To Image Preprocessor. Nadat we alle 12 captcha's zorgvuldig hebben bekeken, zien we dat ze alleen cijfers bevatten, dus ga naar het tabblad opties en geef aan dat alleen cijfers herkend moeten worden (Tekenset = Numeriek). Nu kunt u naar het tabblad Image Preprocessing gaan om filters te configureren. Ik moet meteen zeggen dat ik na het spelen met de eerste drie filters ("Color Inversion", "Color Change", "Grayscale") geen positief effect zag, dus ik liet alles standaard daar. Ik selecteerde Smooth Mask 2 en stelde het aantal passen in op één. Ik sloeg het filter Grayscale buckets over en ging meteen naar de clipping-instelling. Ik koos de waarde 154 en gaf aan dat de pixels die kleiner zijn op 0 moeten worden gezet, en die die groter zijn op 255. Om de resterende punten kwijt te raken, zette ik hakken aan en veranderde de randbreedte naar 10. Er was geen zin om het laatste filter op te nemen, dus ik klikte meteen op Oplossen. Op de captcha had ik het nummer 714945, maar het programma herkende het als 711435. Dit is, zoals je kunt zien, helemaal verkeerd. Uiteindelijk lukte het, hoe hard ik ook vocht, niet om de captcha goed te herkennen. Ik moest experimenteren met pastebin.com, die ik zonder problemen kon herkennen. Maar als u ijveriger en geduldiger blijkt te zijn en erin slaagt om de juiste herkenning van captcha's van de site te krijgen, ga dan onmiddellijk naar het tabblad Opties en schakel voorbewerking van afbeeldingen in (Enable Image Preprocessing). Ga dan naar Main en download door op Start te klikken een nieuwe portie captcha's, die nu door uw filter worden voorbewerkt. Nadat het programma is uitgevoerd, markeert u de correct / onjuist herkende captcha's (knoppen Markeer als correct / Markeer als onjuist). Vanaf nu kunt u de overzichtsstatistieken over herkenning bekijken met Show Statistics. Over het algemeen is dit een soort rapport over de beveiliging van een of andere CAPTCHA. Als de vraag gaat over de keuze voor een of andere oplossing, dan is het met behulp van TesserCap heel goed mogelijk om uw eigen testen uit te voeren.
CAPTCHA-controleresultaat op populaire sites
Website en aandeel van erkende captcha's:- Wikipedia> 20-30%
- Ebay> 20-30%
- reddit.com> 20-30%
- CNBC> 50%
- foodnetwork.com> 80-90%
- dagelijksemail.nl> 30%
- megaupload.com> 80%
- pastebin.com> 70-80%
- cavenue.com> 80%