Китайский, японский и корейский языки. Единицы измерения объема данных и ёмкости памяти: килобайты, мегабайты, гигабайты…
(И дело здесь не в размере)
Эллиотт Хэролд (Elliot Rusty Harold)
Опубликовано 25.09.2013
Сервис Sitemap компании Google не так давно вызвал небольшой переполох в сообществе XML, поскольку начал требовать, чтобы все карты сайтов публиковались исключительно в кодировке UTF-8 Unicode. Google не позволяет использовать даже альтернативные кодировки Unicode (например, UTF-16), не говоря уж об отличных от Unicode кодировках, таких как ISO-8859-1. С технической точки зрения это означает, что Google использует какой-то не соответствующий стандартам синтаксический анализатор XML, поскольку согласно Рекомендации XML «все XML-процессоры ДОЛЖНЫ принимать кодировки UTF-8 и UTF-16 Unicode 3.1». Однако является ли это действительно такой уж проблемой?
UTF-8 доступна для всех
Универсальность является первой и наиболее веской причиной выбора UTF-8. Эта кодировка способна работать практически с любой системой письма, используемой в наши дни. Некоторые пробелы остаются, но они становятся все более редкими и в настоящее время заполняются. Системы письма, которые остаются неохваченными, в большинстве своем также не были реализованы ни в каком другом наборе символов, а даже если и были реализованы, то не являются доступными в XML. В лучшем случае они реализуются фонт-хаками, надстроенными над однобайтными наборами символов, такими как Latin-1. Настоящая поддержка для таких редких систем письма в первую очередь появится в Unicode (причем вероятно, что исключительно в Unicode и нигде больше).
Однако это лишь один из аргументов в пользу Unicode. Почему следует выбирать UTF-8 вместо UTF-16 или других кодировок Unicode? Одной из самых очевидных причин является широкая поддержка инструментальных средств. C UTF-8 работает практически любой сколько-либо заметный редактор, который можно использовать с XML, включая JEdit, BBEdit, Eclipse, emacs и даже Блокнот Windows (Notepad). Никакая другая кодировка Unicode не может похвастаться столь широкой поддержкой инструментальных средств среди XML и не-XML утилит.
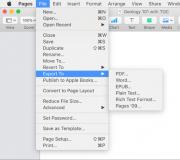
В некоторых случаях (например, в BBEdit и Eclipse) UTF-8 не является набором символов по умолчанию. Пора уже изменить установки по умолчанию – все инструментальные средства должны поставляться с выбором UTF-8 в качестве кодировки по умолчанию. Пока этого не случится, мы будем оставаться в «болоте» функционально несовместимых файлов, которые повреждаются при передаче через национальные границы, границы платформ и лингвистические границы. Однако пока все программы не будут иметь UTF-8 в качестве кодировки по умолчанию, установки по умолчанию можно легко изменить самостоятельно. Например, в Eclipse на панели «General/Editors» («Общие параметры/Редакторы»), показанной на рисунке 1, вы можете указать, что все файлы должны иметь кодировку UTF-8. Можно заметить, что Eclipse «хочет» иметь установку по умолчанию MacRoman; однако если позволить сделать это, ваши файлы не будут компилироваться при передаче программистам, работающим на компьютерах с операционной системой Microsoft® Windows® и любых компьютерах за пределами Америки и Западной Европы.
Рисунок 1. Изменение установленного по умолчанию набора символов в Eclipse

Разумеется, для того чтобы кодировка UTF-8 работала, разработчики, с которыми вы обмениваетесь файлами, также должны использовать UTF-8; но это не должно стать проблемой. В отличие от MacRoman, кодировка UTF-8 не ограничена всего несколькими системами письма и одной малораспространенной платформой. UTF-8 хорошо работает для всех и каждого. Совершенно иначе дело обстоит с MacRoman, Latin-1, SJIS и другими разнообразными традиционными национальными наборами символов.
UTF-8 также лучше работает с инструментальными средствами, которые не ожидают получения многобайтных данных. Другие форматы Unicode (например, UTF-16) обычно содержат многочисленные нулевые байты. Многие инструментальные средства интерпретируют эти байты как конец файла или какой-либо иной специальный разделитель, что приводит к неожиданным, непредвиденным и зачастую неприятным последствиям. Например, если данные UTF-16 «простодушно» загрузить в строку C, строка может оказаться обрезанной на втором байте первого символа ASCII. Файлы UTF-8 содержат только те нули, которые действительно должны быть нулями. Разумеется, не стоит выбирать для обработки документов XML подобные простоватые инструментальные средства. Однако документы часто завершают свой путь в таких необычных местах традиционных систем, где никто на самом деле не принимал во внимание и не понимал последствия «розлива нового вина в старые меха». В системах, не знакомых с Unicode и XML, вероятность появления проблем при использовании кодировки UTF-8 меньше, чем при работе с UTF-16 или другими кодировками Unicode.
Что говорят спецификации
XML являлся первым важным стандартом, который полностью поддерживает UTF-8, но это было только началом тенденции. Органы стандартизации все больше рекомендуют UTF-8. Например, URL-адреса, которые содержат отличные от ASCII символы, долгое время были трудноразрешимой проблемой в Интернете. Работающий на компьютере PC URL-адрес, который содержал отличные от ASCII символы, отказывался работать при загрузке на платформе Mac и наоборот. Эта проблема была решена лишь недавно, когда Консорциум World Wide Web (W3C) и Инженерная группа по развитию Интернета (IETF) договорились о том, что все URL-адреса будут кодироваться только в UTF-8 и ни в какой другой кодировке.
Обе организации (W3C и IETF) в последнее время стали более непреклонными в отношении выбора UTF-8 в общем и целом, а иногда и в качестве единственной кодировки. В документе The W3C Character Model for the World Wide Web 1.0: Fundamentals («Модель символов W3C для World Wide Web 1.0: основы») говорится: «Когда требуется какая-либо однозначная кодировка символов, ДОЛЖНА использоваться кодировка символов UTF-8, UTF-16 или UTF-32. Кодировка US-ASCII имеет восходящую совместимость с UTF-8 (строка US-ASCII также является строкой UTF-8, см. ), поэтому UTF-8 может быть использована, если необходима совместимость с US-ASCII». На практике совместимость с US-ASCII является настолько полезной, что представляет собой практически обязательное требование. W3C мудро поясняет: «В других ситуациях, например для API, может быть более уместной кодировка UTF-16 или UTF-32. Возможные причины выбора одной из этих кодировок включают эффективность внутренней обработки и функциональную совместимость с другими процессами».
Я могу поверить в аргумент об эффективности внутренней обработки. Например, внутреннее представление строк языка Java™ основывается на UTF-16, что значительно ускоряет индексацию в строку. Однако код Java никогда не показывает свое внутреннее представление программам, с которыми он обменивается данными. Вместо этого для внешнего обмена данными используется java.io.Writer , при этом набор символов указывается явным образом. При осуществлении такого выбора настоятельно рекомендуется использовать UTF-8.
Требования IETF являются даже еще более явными. В документе The IETF Charset Policy («Политика IETF в отношении наборов символов») недвусмысленно указано:
Протоколы ДОЛЖНЫ быть способны использовать для всего текста набор символов UTF-8, который состоит из набора кодированных символов ISO 10646 в сочетании со схемой кодирования символов UTF-8, определенной в Приложении R (опубликованном в Поправке 2).Протоколы МОГУТ дополнительно указывать на то, как использовать другие наборы символов или другие схемы кодирования символов для ISO 10646, например UTF-16, но невозможность использования UTF-8 является нарушением данной политики; такое нарушение потребовало бы применения какой-либо процедуры отклонения ( раздел 9) с четким и веским обоснованием в документе спецификации протокола перед входом на путь следования стандартам или продвижением по этому пути.
Для существующих протоколов и протоколов, которые перемещают данные из существующих информационных хранилищ, одним из требований может являться поддержка других наборов символов или даже использование по умолчанию кодировки, отличной от UTF-8. Это приемлемо, но возможность поддержки UTF-8 ДОЛЖНА присутствовать.
Ключевой момент: поддержка традиционных протоколов и файлов может требовать принятия наборов символов и кодировок, отличных от UTF-8, еще в течение какого-то времени – однако я бы наступил на горло собственной песне, если бы мне пришлось делать это. Каждый новый протокол, каждое новое приложение и каждый новый документ должны использовать UTF-8.
Китайский, японский и корейский языки
Одним из распространенных ошибочных представлений является то, что UTF-8 будто бы представляет собой формат сжатия. Это в корне неверно. Символы в диапазоне ASCII занимают в UTF-8 только половину того пространства, которое они занимают в некоторых других кодировках Unicode, в частности в UTF-16. Однако некоторые символы требуют до 50 % больше пространства для кодирования в UTF-8 – особенно китайские, японские и корейские (CJK) иероглифы.
Но даже когда вы кодируете XML CJK в UTF-8, фактическое увеличение размера по сравнению с UTF-16, вероятно, не будет столь значительным. Например, документ XML на китайском языке содержит множество таких символов ASCII, как <, >, &, =, ", ", и пробел. Все эти символы занимают в UTF-8 меньше пространства, чем в UTF-16. Точная величина коэффициента сжатия или расширения варьируется от одного документа к другому, но в любом случае разница едва ли будет сильно бросаться в глаза.
Наконец, стоит отметить, что идеографическая письменность, подобная китайской и японской, обычно является «экономной» в отношении количества символов по сравнению с буквенной письменностью, например латиницей и кириллицей. Некоторое большое абсолютное количество этих символов требуют трех и более байтов на символ для полного представления указанных систем письма; это означает, что одни и те же слова и предложения могут выражаться с помощью меньшего числа символов, чем в таких языках, как английский и русский. Например, японская идеограмма для дерева – æ¨. (Это выглядит немного похоже на дерево). Данная идеограмма занимает в UTF-8 три байта, в то время как английское слово «tree» («дерево») состоит из четырех букв и занимает четыре байта. Японская идеограмма для рощи – æ- (два дерева рядом друг с другом). Она также занимает в UTF-8 три байта, в то время как английское слово «grove» («роща») состоит из пяти букв и занимает пять байтов. Японская идеограмма 森 (три дерева) по-прежнему занимает всего три байта. А эквивалентное английское слово «forest» («лес») занимает шесть.
Если же вас действительно интересует сжатие, сжимайте XML с помощью утилит zip или gzip. Сжатый UTF-8, вероятно, будет близок по размеру к сжатому UTF-16 независимо от первоначальной разницы в размерах. Изначально больший размер одного из документов будет скомпенсирован бóльшей избыточностью, устраняемой алгоритмом сжатия.
Надежность
Истинная «изюминка» заключается в том, что в соответствии с проектным замыслом UTF-8 является намного более надежным и проще интерпретируемым форматом, чем любая другая кодировка текста, разработанная до этого и после появления UTF-8. Во-первых, в отличие от UTF-16, UTF-8 не имеет проблем с порядком следования байтов. UTF-8 с прямым и обратным порядком байтов идентичны, поскольку UTF-8 определяется в 8-битных байтах, а не в 16-битных словах. UTF-8 не имеет двусмысленности в отношении порядка байтов, которую пришлось бы разрешать с помощью меток порядка следования байтов или иной эвристики.
Еще более важной характеристикой UTF-8 является отсутствие необходимости фиксации состояния. Каждый байт потока или последовательности UTF-8 является однозначным. В UTF-8 вы всегда знаете, где находитесь – т. е. по отдельному байту вы сразу можете определить, является ли он однобайтным символом, первым байтом двухбайтного символа, вторым байтом двухбайтного символа либо вторым, третьим или четвертым байтом трех- или четырехбайтного символа. (Это далеко не все возможности, но приведенная информация поможет вам получить общее представление). В UTF-16 вы не всегда знаете, представляет ли байт «0x41» букву «A». Иногда это так, а иногда – нет. Вам нужно в достаточной степени отслеживать состояние, чтобы понять, в каком месте потока находитесь. Если какой-либо отдельный байт теряется, то все последующие данные, начиная с этого места, повреждаются. В UTF-8 потерянные или искаженные байты обнаруживаются сразу не влекут за собой повреждение остальных данных.
Кодировка UTF-8 не является идеальной для всех без исключения применений. Приложения, которые требуют произвольного доступа к конкретным индексам в пределах документа, могут работать быстрее при использовании какой-либо кодировки с фиксированной шириной, например UCS2 или UTF-32. (UTF-16 – является кодировкой с переменной шириной, если принимать во внимание замещающие пары). Однако обработка XML не относится к таким приложениям. Спецификация XML фактически требует, чтобы синтаксические анализаторы начинали анализ с первого байта документа XML и продолжали анализ до конца, и все существующие синтаксические анализаторы работают именно так. Ускорение произвольного доступа никоим образом не помогло бы обработке XML; поэтому, хотя это и могло бы стать одной и веских причин использования какой-либо другой кодировки в базе данных или иной системе, это не имеет отношения к XML.
Заключение
В условиях все большей интернационализации мира, когда лингвистические и политические границы с каждым днем становятся все более размытыми, зависящие от местной специфики наборы символов становятся непригодными. Unicode – это единственный набор символов, который можно использовать во всех существующих в мире локалях. UTF-8 представляет собой надлежащую реализацию Unicode, которая:
- характеризуется широкой поддержкой инструментальных средств, включая наилучшую совместимость с традиционными системами ASCII;
- проста и эффективна для обработки;
- устойчива к повреждению данных;
- является платформенно-независимой.
Пришло время прекратить споры о наборах символов и кодировках – выберите UTF-8 и покончите с дискуссиями.
Теоретически давно существует решение этих проблем. Оно называетсяUnicode (Юникод). Unicode – это кодировочная таблица, в которой для кодирования каждого символа используется 2 байта, т.е. 16 бит. На основании такой таблицы может быть закодированоN=2 16 =65 536 символов.
Юникод включает практически все современные письменности, в том числе: арабскую, армянскую, бенгальскую, бирманскую, греческую, грузинскую, деванагари, иврит, кириллицу, коптскую, кхмерскую, латинскую, тамильскую, хангыль, хань (Китай, Япония, Корея), чероки, эфиопскую, японскую (катакана, хирагана, кандзи) и другие.
С академической целью добавлены многие исторические письменности, в том числе: древнегреческая, египетские иероглифы, клинопись, письменность майя, этрусский алфавит.
В Юникоде представлен широкий набор математических и музыкальных символов, а также пиктограмм.
Для символов кириллицы в Юникоде выделено два диапазона кодов:
Cyrillic (#0400 - #04FF)
Cyrillic Supplement (#0500 - #052F).
Но внедрение таблицы Unicode в чистом виде сдерживается по той причине, что если код одного символа будет занимать не один байт, а два байта, что для хранения текста понадобится вдвое больше дискового пространства, а для его передачи по каналам связи – вдвое больше времени.
Поэтому сейчас на практике больше распространено представление Юникода UTF-8 (Unicode Transformation Format). UTF-8 обеспечивает наилучшую совместимость с системами, использующими 8-битные символы. Текст, состоящий только из символов с номером меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 4 байтов. В целом, так как самые распространенные в мире символы – символы латинского алфавита - в UTF-8 по-прежнему занимают 1 байт, такое кодирование экономичнее, чем чистый Юникод.
В кодируемом английском тексте используется только 26 букв латинского алфавита и еще 6 знаков пунктуации. В этом случае текст, содержащий 1000 символов можно гарантированно сжать без потерь информации до размера:
Словарь Эллочки – «людоедки» (персонаж романа «Двенадцать стульев») составляет 30 слов. Сколько бит достаточно, чтобы закодировать весь словарный запас Эллочки? Варианты: 8, 5, 3, 1.
Единицы измерения объема данных и ёмкости памяти: килобайты, мегабайты, гигабайты…
Итак, в мы выяснили, что в большинстве современных кодировок под хранение на электронных носителях информации одного символа текста отводится 1 байт. Т.е. в байтах измеряется объем (V), занимаемый данными при их хранении и передаче (файлы, сообщения).
Объем данных (V) – количество байт, которое требуется для их хранения в памяти электронного носителя информации.
Память носителей в свою очередь имеет ограниченную ёмкость , т.е. способность вместить в себе определенный объем. Ёмкость памяти электронных носителей информации, естественно, также измеряется в байтах.
Однако байт – мелкая единица измерения объема данных, более крупными являются килобайт, мегабайт, гигабайт, терабайт…
Следует запомнить, что приставки “кило”, “мега”, “гига”… не являются в данном случае десятичными. Так “кило” в слове “килобайт” не означает “тысяча”, т.е. не означает “10 3 ”. Бит – двоичная единица, и по этой причине в информатике удобно пользоваться единицами измерения кратными числу “2”, а не числу “10”.
1 байт = 2 3 =8 бит, 1 килобайт = 2 10 = 1024 байта. В двоичном виде 1 килобайт = &10000000000 байт.
Т.е. “кило” здесь обозначает ближайшее к тысяче число, являющееся при этом степенью числа 2, т.е. являющееся “круглым” числом в двоичной системе счисления.
Таблица 10.
|
Именование |
Обозначение |
Значение в байтах |
|
|
килобайт | |||
|
мегабайт |
2 10 Kb = 2 20 b | ||
|
гигабайт |
2 10 Mb = 2 30 b | ||
|
терабайт |
2 10 Gb = 2 40 b |
1 099 511 627 776 b |
|
В связи, с тем, что единицы измерения объема и ёмкости носителей информации кратны 2 и не кратны 10, большинство задач по этой теме проще решается тогда, когда фигурирующие в них значения представляются степенями числа 2. Рассмотрим пример подобной задачи и ее решение:
В текстовом файле хранится текст объемом в 400 страниц. Каждая страница содержит 3200 символов. Если используется кодировка KOI-8 (8 бит на один символ), то размер файла составит:
Решение
Определяем общее количество символов в текстовом файле. При этом мы представляем числа, кратные степени числа 2 в виде степени числа 2, т.е. вместо 4, записываем 2 2 и т.п. Для определения степени можно использовать Таблицу 7.
символов.
2) По условию задачи 1 символ занимает 8 бит, т.е. 1 байт => файл занимает 2 7 *10000 байт.
3) 1 килобайт = 2 10 байт => объем файла в килобайтах равен:
 .
.
Сколько бит в одном килобайте?
&10000000000000.
Чему равен 1 Мбайт?
1000000 байт.
1024 байта;
1024 килобайта;
Сколько бит в сообщении объемом четверть килобайта? Варианты: 250, 512, 2000, 2048.
Объем текстового файла 640 Kb . Файл содержит книгу, которая набрана в среднем по32 строки на странице и по64 символа в строке. Сколько страниц в книге: 160, 320, 540, 640, 1280?
Досье на сотрудников занимают 8 Mb . Каждое из них содержит16 страниц (32 строки по64 символа в строке). Сколько сотрудников в организации: 256; 512; 1024; 2048?
Этот пост для тех, кто не понимает, что такое UTF-8, но хочет это понять, а доступная документация часто очень обширно освещает этот вопрос. Я попробую здесь описать это так, как сам бы хотел, чтобы раньше мне кто-то так рассказал. Так как часто у меня по поводу UTF-8 была в голове каша.
Несколько простых правил
- Итак, UTF-8 — это «обертка» для Unicode. Это не отдельная кодировка символов, это «обертнутый» Unicode. Вы, наверное, знаете Base64 кодировку, или слышали о ней — она может обернуть бинарные данные в печатаемые символы. Дак вот, UTF-8 это такой же Base64 для Unicode, как Base64 для бинарных данных. Это раз. Если вы это поймете, то уже многое станет ясно. И она также, как Base64, признана решить проблему совместимости в символах (Base64 была придумана для email, чтобы передавать файлы почтой, в которой все символы — печатаемые)
- Далее, если код работает с UTF-8, то внутри он все равно работает с Unicode кодировками, то есть, где-то глубоко внутри есть таблицы символов именно Unicode символов. Правда, можно не иметь таблиц символов Unicode, если надо просто посчитать, сколько символов в строке, например (см. ниже)
- UTF-8 сделан с той целью, чтобы старые программы и сегодняшние компьютеры могли работать нормально с Unicode символами, как со старыми кодировками, типа KOI8, Windows-1251 и т.п.. В UTF-8 нет байтов с нулями, все байты — они либо от 0x01 — 0x7F, как обычный ASCII, либо 0x80 — 0xFF, что также работает под программами, написанными на Си, как и работало бы не с ASCII символами. Правда, для корректной работы с символами программа должна знать Unicode таблицы.
- Все, что имеет старший 7-ой бит в байте (если считать биты с нулевого) UTF-8 — часть кодированного потока Unicode.
UTF-8 изнутри
Если вы знаете битовую систему, то вот вам краткая памятка , как кодируется UTF-8:
Первый байт Unicode символа в UTF-8 начинается с байта, где 7-ой бит всегда единица, и 6-ой бит всегда также единица. При этом в первом байте, если смотреть на биты слева направо (7-ой, 6-ой и так до нулевого), идет столько единиц, сколько байтов, включая первый, идет на кодирование одного Unicode символа. Заканчивается последовательность единиц нулем. А после этого идут биты самого Unicode символа. Остальные биты Unicode символа попадают во второй, или даже в третий байты (максимум три, почему — смотрите чуть ниже). Остальные байты, кроме первого, всегда идут с началом ’10’ и потом 6 битов следующей части Unicode символа.
Пример
Например: есть байты 110 10000 и второй 10 011110 . Первый — начинается с ‘110’ — это значит, что раз две единицы — будет два байта UTF-8 потока, и второй байт, как и все остальные, начинается с ’10’. А кодируют эти два байта символ Unicode, который состоит из 10100 битов от первого куска + 101101 от второго, получается -> 10000011110 -> 41E в 16-ричной системе, или U+041E в написании Unicode обозначений. Это символ большая русская О .
Сколько максимум байт на символ?
Также, давайте посмотрим, сколько максимум байт уходит в UTF-8, чтобы закодировать 16 бит кодировки Unicode. Вторые и далее байты всегда максимум могут вместить 6 бит. Значит, если начать с конечных байтов, то два байта уйдут точно (2-ой и третий), а первый должен начинаться с ‘1110’, чтобы закодировать три. Значит первый байт максимум в таком варианте может закодировать первые 4 бита символа Unicode. Получается 4 + 6 + 6 = 16 байт. Выходит, что UTF-8 может иметь либо 2, либо 3 байта на символ Unicode (один не может, так как нет надобности кодировать 6 бит (8 — 2 бита ’10’) — они будут ASCII символом. Именно поэтому первый байт UTF-8 никогда не может начинаться с ’10’).
Заключение
Кстати, благодаря такой кодировке, можно взять любой байт в потоке, и определить: является ли байт Unicode символом (если 7-ой бит — значит не ASCII), если да, то первый ли он в потоке UTF-8 или не первый (если ’10’, значит не первый), если не первый, то мы можем переместиться назад побайтово, чтобы найти первый код UTF-8 (у которого 6-ой бит будет 1), либо переместится вправо и пропустить все ’10’ байты, чтобы найти следующий символ. Благодаря такой кодировке, программы также могут, не зная Unicode, считать, сколько символов в строке (на основании первого байта UTF-8 вычислить длину символа в байтах). Вообщем, если подумать, кодировка UTF-8 придумана очень грамотно, и в то же время очень эффективно.
Юникод поддерживает практически все существующие наборы символов. Наилучшей формой кодирования набора символов Юникода является UTF-8-кодировка. В ней реализована совместимость с ASCII, устойчивость к искажению данных, эффективность и простота обработки. Но обо всём по порядку.
Формы кодирования
Компьютеры оперируют числами не просто как абстрактными математическими объектами, а как комбинациями единиц хранения и обработки информации фиксированного размера - байтов и 32-разрядных слов. Стандарт кодировки должен это учитывать при определении способа представления
В компьютерных системах целые числа хранятся в ячейках памяти размером 8 бит (1 байт), 16 или 32 бит. Каждая форма кодирования Юникода определяет, какая последовательность ячеек памяти представляет целое число, соответствующее конкретному символу. В стандарте представлены три различные формы кодирования символов Юникода: 8, 16 и 32-битными блоками. Соответственно, они носят название UTF-8, UTF-16 и UTF-32. Название UTF расшифровывается как формат преобразования Юникода. Каждая из трёх форм кодирования является равноправным средством представления символов Юникода, имеет преимущества в различных областях применения.
Данные кодировки могут быть использованы для представления всех символов стандарта Юникод. Таким образом, они полностью совместимы для решений, по разным причинам использующих разные формы кодирования. Каждая кодировка может быть однозначно преобразована в любую из двух других без потери данных.
Принцип неналожения
Каждая из форм кодирования Юникода разработана с учётом недопустимости частичного наложения. Например, Windows-932 формирует символы из одного или двух байтов кода. Длина последовательности зависит от первого байта, поэтому значения лидирующего байта в последовательности из двух байтов и одиночного байта не пересекаются. Однако значения одиночного байта и замыкающего байта последовательности могут совпадать. Это означает, например, что при поиске символа D (код 44) можно ошибочно найти его входящим во вторую часть последовательности из двух байтов символа «Д» (код 84 44). Чтобы выяснить, какая последовательность является правильной, программа должна учесть предыдущие байты.
Ситуация усложнится, если ведущий и замыкающий байт совпадут. Это значит, что для снятия неоднозначности будет проводиться обратный поиск до достижения начала текста или однозначной последовательности кода. Это не только неэффективно, но не защищено от возможных ошибок, ведь достаточно одного неправильного байта, чтобы весь текст стал нечитабельным.
Формат преобразования Юникода позволяет избежать данной проблемы, потому что значения ведущей, замыкающей и одиночной единицы хранения информации не совпадают. Благодаря этому все кодировки Юникода подходят для поиска и сравнения, никогда не давая ошибочного результата из-за совпадения разных частей кода символов. Тот факт, что данные формы кодирования соблюдают принцип неналожения, отличает их от других многобайтовых восточноазиатских кодировок.
Другим аспектом непересечения является то, что каждый символ имеет чётко определяемые границы. При этом отпадает необходимость в сканировании неопределённого числа предыдущих символов. Данную особенность кодировок иногда называют самосинхронизацией. Искажение одной единицы кода введёт к искажению только одного символа, а окружающие символы остаются нетронутыми. В 8-битном формате преобразования, если указатель ссылается на байт, начинающийся с 10xxxxxx (в двоичной кодировке), для поиска начала символа потребуется от одного до трёх обратных переходов.

Согласованность
Консорциум Юникода в полной мере поддерживает все 3 формы кодировок. Важно не противопоставлять UTF-8 и Юникод, ведь все форматы преобразования - одинаково правомерные воплощения форм кодирования символов стандарта Юникод.
Байт-ориентация
Для представления символа UTF-32 понадобится одна 32-битная единица кода, которая совпадает с кодом Юникода. UTF-16 - от одной до двух 16-битных единиц. А UTF-8 использует до 4 байт.
Кодировка UTF-8 создана для совместимости с байт-ориентированными системами на основе ASCII. Большая часть существующего программного обеспечения и практика информационных технологий длительное время опирались на представление символов в виде последовательности байтов. Множество протоколов зависит от неизменности и использует либо избегает специальные управляющие символы. Простым способом адаптировать Юникод к таким ситуациям можно, применив 8-битное кодирование для представления символов Юникода, эквивалентных любому или управляющему символу. Для этого и предназначена кодировка UTF-8.
Переменная длина
UTF-8 - кодировка переменной длины, состоящая из 8-битных единиц хранения информации, старшие биты которых обозначают, к какой части последовательности относится каждый отдельный байт. Один диапазон значений отведён для первого элемента последовательности кода, другой - для последующих. Это обеспечивает непересекаемость кодировки.

ASCII
UTF-8-кодировка полностью поддерживает коды ASCII (0x00-0x7F). Это значит, что символы Юникода U+0000-U+007F конвертируются в единственный байт 0x00-0x7F UTF-8 и таким образом становятся неотличимыми от ASCII. Более того, чтобы избежать многозначности, значения 0x00-0x7F не используются больше ни в одном байте представления символов Юникода. Для кодирования неидеографических символов, отличных от ASCII, используется последовательность из двух байтов. Символы диапазона U+0800-U+FFFF представлены тремя байтами, а дополнительные с кодами больше U+FFFF требуют четырёх байтов.
Область применения
Кодировке UTF-8 обычно отдаётся предпочтение в протоколе HTML и ему подобным.
XML стал первым стандартом с полной поддержкой кодировки UTF-8. Организации, занимающиеся стандартизацией, тоже её рекомендуют. Проблема поддержки в адресах URL, отличных от ASCII-символов, была решена, когда консорциум W3С и инженерная группа IETF пришли к соглашению о кодировании всех исключительно в UTF-8.
Совместимость с ASCII облегчает переход к новому программному обеспечению. С UTF-8 работает большинство текстовых редакторов, в том числе JEdit, Emacs, BBEdit, Eclipse и "Блокнот" операционной системы Windows. Ни одна другая форма кодирования Юникода не может похвалиться такой поддержкой со стороны инструментальных средств.
Преимущество кодировки заключается в том, что она состоит из последовательности байтов. Со строками UTF-8 легко работать в C и других языках программирования. Это единственная форма кодирования, не требующая метки порядка байтов BOM или объявления кодировки в XML.

Самосинхронизация
В окружении, использующем 8-битную обработку символов, по сравнению с другими многобайтными кодировками, UTF-8 обладает следующими преимуществами:
- Первый байт последовательности кода содержит информацию о его длине. Это повышает эффективность прямого поиска.
- Упрощено нахождение начала символа, так как начальный байт ограничен фиксированным диапазоном значений.
- Отсутствует пересечение значений байтов.
Сравнение преимуществ
UTF-8-кодировка компактна. Но при применении для кодирования восточноазиатских символов (китайских, японских, корейских, использующих знаки китайского письма) используются 3-байтные последовательности. Также UTF-8-кодировка уступает другим формам кодирования по скорости обработки. А двоичная сортировка строк даёт тот же результат, что и двоичная сортировка Юникода.
Схема кодировки символов
Схема кодировки символов состоит из формы кодирования символов и способа побайтного расположения единиц кода. Для определения схемы кодирования стандартом Юникода предусмотрено использование начальной метки порядка байтов (BOM, Byte order mark).
При включении BOM в UTF-8 функция метки ограничивается только указанием на использование формы кодирования. Проблемы определения порядка байтов у UTF-8 нет, так как её размер единицы кодирования равен одному байту. Использование BOM для данной формы кодирования не является ни обязательным, ни рекомендуемым. BOM может встречаться в текстах, конвертированных из других кодировок, использующих метку порядка байтов, или для сигнатуры кодировки UTF-8. Представляет собой последовательность из 3 байтов EF 16 BB 16 BF 16 .

Как задать кодировку UTF-8
В UTF-8 устанавливается с помощью следующего кода:
˂meta http-equiv="Content-Type" content="text/html; charset=utf-8"˃
В PHP кодировка UTF-8 задаётся с помощью функции header() в самом начале файла после задания значения уровня вывода ошибок:
error_reporting(-1);
Charset=utf-8");
Для подключения к базам данных MySQL кодировка UTF-8 устанавливается так:
mysql_set_charset("utf8");
В CSS-файлах кодировка символов UTF-8 указывается так:
@charset "utf-8";

При сохранении файлов всех типов выбирается кодировка UTF-8 без BOM, иначе сайт работать не будет. Для этого в программе DreamWeave нужно выбрать пункт меню «Модификации - Свойства страницы - Заголовок/Кодировка», изменить кодировку на UTF-8. Затем следует перезагрузить страницу, убрать галочку из пункта «Подключить Юникод сигнатуры (BOM)» и применить изменения. Если какой-либо текст на странице или в базе данных был введён другой формой кодирования, то его нужно ввести заново или перекодировать. При работе с регулярными выражениями обязательно использовать модификатор u.
В текстовом редакторе Notepad++, если кодировка отлична от UTF-8, через пункт меню «Преобразовать в UTF-8 без BOM» изменить кодировку и сохранить в кодировке UTF-8.

Альтернативы нет
В условиях глобализации, когда политические и языковые границы стираются, наборы символов, которые имеют местные особенности, становятся малопригодными. Юникод является единственным набором символов с поддержкой всех локализаций. А UTF-8 - пример правильной реализации Юникода, которая:
- поддерживает широкий диапазон инструментальных средств, в том числе совместимость с кодировкой ASCII;
- обладает устойчивостью к искажению данных;
- проста и эффективна при обработке;
- не зависит от платформы.
С появлением UTF-8 дискуссии о том, какая форма кодирования или набор символов лучше, стали бессмысленны.