Programma's voor het zoeken naar gegevens in bestanden. Een programma voor het zoeken naar tekst in bestanden op een computer
Zoeken naar tekst in documenten in doc-, xls- en pdf-formaten is iets dat ik al heel lang wil vermelden. Maar niet zoeken binnen één document, dit is vrij eenvoudig - iedereen kent Ctrl + F, maar zoeken naar een Russisch woord, bijvoorbeeld in 10 of > documenten. Ze allemaal openen en handmatig zoeken is mogelijk, maar tijdrovend. En als er honderd documenten/bestanden zijn, maar je hoeft bijvoorbeeld alleen Vasil Petrovich te vinden... Het is dit soort zoekopdrachten waar ik meer in detail over wilde praten.
Zoeken naar tekst in bestanden (in het Engels)
Zoeken naar tekst (in het Engels) in bestanden als *.txt, *.html kan bijvoorbeeld met Total Commander 6.53. Helemaal niet Totaal commandant- een onmisbare bestandsbeheerder, als je hem nog niet gebruikt - het is de moeite waard downloaden en beginnen met gebruiken! Het biedt zeer goede navigatie afhankelijk van uw harde schijf, en dankzij de structuur met twee vensters kunt u meerdere bewerkingen tegelijkertijd uitvoeren met elk bestand. En dus kun je naar een woord/meerdere woorden zoeken door op Alt+F7 te drukken, het vakje "zoeken met tekst" aan te vinken en ok! Maar het kan niet zoeken in verschillende bestanden zoals *.doc, *.xls. U moet een ander programma gebruiken.
Zoek Russische woorden
Uit tests die ik heb uitgevoerd met verschillende programma's voor het zoeken naar Russische woorden in bestanden bleek dat het programma FindFiles3 aandacht verdient. Het is specifiek ontworpen om naar bestanden te zoeken op naam en/of inhoud. Waar een standaard zoekopdracht het gevonden stukje tekst niet laat zien, vindt FindFiles alles gemakkelijk.
Het programma zoekt in meerdere coderingen tegelijk naar het gewenste fragment. Gevonden tekst wordt in een apart veld weergegeven en in kleur gemarkeerd, etc. De programmaoproep is ingebouwd in het Explorer-contextmenu "Bestanden zoeken, inhoud...".
De programma-interface is vrij eenvoudig. Je kunt er zonder problemen achter komen. In de linkerbovenhoek stelt u uw zoekparameters in. In het veld “In map” geeft u het pad of de paden op waarnaar u wilt zoeken, d.w.z. In welke mappen moet ik zoeken? Om een zoekmasker op te geven, gebruikt u het “*”-symbool. Bijvoorbeeld *.doc: alle doc-bestanden worden met dit masker gevonden. U kunt meerdere zoekmaskers opgeven, gescheiden door komma's of puntkomma's.
Als u bestanden zoekt, waarin het opgegeven tekstfragment voorkomt, dan moet je dit fragment specificeren in het veld “Tekst”. Bestanden die door andere applicaties zijn geopend, kunnen worden geblokkeerd. Vink in dit geval het selectievakje ‘Geblokkeerd weergeven’ aan. Deze bestanden worden gemarkeerd met een rood vierkantje in de algemene lijst met gevonden bestanden. Het is mogelijk om verder te zoeken onder de reeds gevonden personen. Om dit te doen, moet u het juiste vakje aanvinken. Als u zoekt in wat er is gevonden, worden eerder gevonden bestanden getint.
U kunt een zoekvoorwaarde instellen op bestandsdatum, enz. Na het zoeken kunt u de gevonden bestanden in een van de kolommen sorteren. Om dit te doen, hoeft u alleen maar op de kolomnaam te klikken. U kunt uw zoekopdracht ook voortzetten door uw zoekcriteria te wijzigen.
Tekst zoeken in bestanden - oefenen
Download en installeer het programma.

Nu moeten we de map opgeven met de bestanden waarin we gaan zoeken. En het bestandsformaat dienovereenkomstig.

Voor de duidelijkheid heb ik een map met 134 bestanden aangegeven. En slechts één bevat het gewenste woord. Klik op “Zoeken”

En binnen een paar seconden vond het programma een bestand waarin dit woord voorkomt. En ook nog een stukje tekst, wel zo handig!
Dat is alles! Nu kunt u in veel bestanden tegelijkertijd naar Russische tekst zoeken!
Als u al met het programma heeft gewerkt en weet hoe u het beste naar Russische tekst kunt zoeken, deel dan uw ervaringen door een recensie te schrijven. Hij kan iemand helpen!
Praat over wat in onze tijd informatie technologieën en de eindeloze groei van de hoeveelheid gegevens die beschikbaar zijn voor zowel een individu als de samenleving, er zijn veel problemen met het verwerken van informatie en het zoeken ernaar - dit is op zichzelf al godslastering. Wie brengt dit onderwerp niet ter sprake? En om u niet te belasten met subjectieve en gedeeltelijk objectieve oordelen van verschillende kanten informatie bronnen Wat het probleem betreft, ga ik direct naar de oplossing ervan. Vandaag zullen we het hebben over zoeken. Dat wil zeggen over programma’s en serieuze informatiesystemen die zoeken naar de documenten en gegevens die we nodig hebben.
Upgrade "direct zoeken"
Nog niet zo lang geleden, toen bomen groot waren en er zelfs informatie in zat lokaal netwerk er waren niet zoveel bedrijven, elke zoekopdracht werd uitgevoerd door een banale doorzoeking van een handvol beschikbare bestanden en een opeenvolgende controle van hun namen en inhoud. Een dergelijke zoekopdracht wordt direct genoemd, en programma's (hulpprogramma's) die gebruik maken van directe zoektechnologie zijn traditioneel overal aanwezig besturingssystemen en gereedschapspakketten. Maar zelfs de macht moderne computers niet genoeg voor snel en adequaat zoeken in gigantische hoeveelheden gegevens tijdens direct zoeken. Het doorzoeken van een paar honderd documenten op een schijf en het doorzoeken van een enorme bibliotheek en enkele tientallen mailboxen zijn twee verschillende dingen. Daarom verdwijnen de directe zoekprogramma's tegenwoordig duidelijk naar de achtergrond - als het gaat om universele tools.
Uiteraard is dit soort zoekopdrachten al lange tijd niet meer in trek in het bedrijfsleven. De volumes zijn niet hetzelfde. En daarom, al vele jaren, en in De laatste tijd absoluut, technologieën die snel en efficiënt kunnen worden uitgevoerd exacte zoekopdracht documenten verschillende formaten en van verschillende bronnen, zijn meer dan relevant. Nog niet zo lang geleden "papa" Microsoft-factuur Gates, blijkbaar jaloers op het fenomenale succes van de internetzoekmachine Google, kondigde op een van de persconferenties de wens aan van de software-industrie (en niet alleen) om op alle mogelijke manieren bij te dragen aan de ontwikkeling en verdieping van de creatie van zoekmachines en technologieën . Maar het is nog te vroeg om een fenomenaal werkend programma van Microsoft of een concurrerende server op internet te maken (MSN bereikt Google nog steeds niet). Laten we daarom eens kijken naar bestaande ontwikkelingen. Index, zoekopdracht, relevantie
In de kern moderne technologieën Er zijn twee fundamentele processen. Ten eerste indexeert het de beschikbare informatie en verwerkt het de aanvraag met daaropvolgende uitvoer van de resultaten. Wat het eerste betreft: elk programma (of het nu een desktopzoekmachine, een bedrijfsinformatiesysteem of een internetzoekmachine is) creëert zijn eigen zoekgebied. Dat wil zeggen, het verwerkt documenten en genereert een index van deze documenten ( georganiseerde structuur, die informatie bevat over de verwerkte gegevens). In de toekomst is het de gecreëerde index die voor het werk wordt gebruikt - het snel verkrijgen van een lijst met benodigde documenten volgens het verzoek. Wat volgt is, hoewel technologisch gezien zeker niet eenvoudig, volkomen begrijpelijk voor de gemiddelde gebruiker. Het programma verwerkt het verzoek (door trefwoordzin) en geeft een lijst met documenten weer die deze sleutelzin bevatten. Omdat de informatie is opgenomen in een gestructureerde index, verloopt de verwerking van zoekopdrachten aanzienlijk (tientallen en honderden keren!) sneller dan bij direct zoeken (de selectie van documenten wordt niet uitgevoerd door het doorzoeken van bestanden, maar door het analyseren van tekst informatie in de index).
Het programma geeft de gevonden documenten in de resulterende lijst weer op basis van relevantie: de overeenstemming van het document met de zoektekst. In verschillende technologieën zijn er natuurlijk wel verschillende methoden zoek en bepaal de relevantie van het document (het aantal “voorkomens” van een woord en de frequentie van vermelding ervan in het document, de verhouding van deze parameters tot het totale aantal woorden in het document, de afstand tussen de woorden van de zoekopdracht zin in de gezochte bestanden, enzovoort). Op basis van deze parameters wordt het “gewicht” van het document bepaald en afhankelijk daarvan verschijnt een bepaald bestand op een bepaalde positie in de resultatenlijst. In het geval van zoeken op internet is de situatie zelfs nog ingewikkelder. Immers, binnen in dit geval Er moet rekening worden gehouden met veel andere factoren (Page Rank Google dat voorbeeld). Maar dit is een onderwerp voor een apart artikel, dus we zullen het internet niet aanraken. Beoordeling van zoekmachines
IN dit materiaal de mogelijkheden van meerdere populaire programma's zoekmachines, die zowel beschikken over behoorlijke snelheden als goede functionaliteit. Maar pronken in brochures is één ding, maar onder de blik van een deskundige staan is iets heel anders. En er waren niet meer en niet minder experts volledig kantoor degenen die graag aan software sleutelen vanwege de bruikbaarheid ervan. Op een experimentele computer (Athlon 2,2 MHz, met 1 GB RAM, 160 GB IDE harde schijf Seagate-aandrijving op 7200 rpm en Windows XP) werd een reeks programma's geïnstalleerd: dtSearch Desktop, Bloodhound Prof Deluxe, Google Desktop Zoeken, SearchInform, Copernic Desktop Search, ISYS Desktop. Voor tests werd een tekstdatabase met documenten samengesteld in doc, txt en html algemeen de grootte is niet meer of minder, maar 20 gigabyte. Een groep kameraden onder leiding van uw nederige dienaar heeft hun subjectieve indrukken van elke software getest, vergeleken en gedeeld. Lees hieronder een samenvatting van de bevindingen. dtSearch-bureaublad
Een programma dat volgens de ontwikkelaars het snelste, handigste en beste is zoekmachine. Zoals, in het algemeen, iedereen uit deze recensie. De dtSearch-interface is vrij eenvoudig, maar sommige vensters of tabbladen zijn enigszins overladen met elementen, waardoor het moeilijk lijkt om te gebruiken. Maar in werkelijkheid zijn er geen bijzondere moeilijkheden. Het enige echt onaangename punt is het gebrek aan ondersteuning van de software voor de Russische taal (ondanks het feit dat het programma naar documenten in verschillende talen kan zoeken, is de interface uitsluitend Engels).
Maar dtSearch is een van de weinige programma's die webpagina's kan indexeren tot een door de gebruiker opgegeven “diepte” (zij het rekening houdend met de “extra aankoop” van de dtSearch Spider add-on kit). Dit is een aanvulling op de ondersteuning van bestanden op schijf van verschillende tekstformaten en e-mails van postbus Vooruitzichten. Tegelijkertijd kan het programma niet werken met databases, die zo'n smakelijk hapje zijn voor zoekmachines vanwege de grote hoeveelheden informatie die ze bevatten en hun brede verspreiding in bedrijven, en dus in bedrijfsnetwerken. De snelheid van het indexeren van dtSearch-documenten bleek op het juiste niveau te zijn. Vooruitkijkend zal ik zeggen dat dit programma de indexering van een bepaalde hoeveelheid informatie op een niveau met een andere concurrent - iSYS - aankon en daarmee de tweede plaats deelde in de lijst met de meest snelle systemen. dtSearch indexeerde een test van 20 gigabyte aan informatie in 6 uur en 13 minuten, waardoor een index van 7,9 GB ontstond voor daaropvolgende zoekbehoeften.
Wat de zoekmogelijkheden betreft, deze zijn hier op het juiste niveau. Ten eerste beschikt dtSearch over een morfologische zoekfunctie (zoeken naar een woord in al zijn morfologische vormen). Door deze gelegenheid te gebruiken, bevrijd je jezelf van bijvoorbeeld gedachten als “in welk geval werd een bepaald woord gebruikt in het document dat ik nodig had?” Het gebruik van morfologisch zoeken is bijna altijd gerechtvaardigd, dus het zou in elke professionele zoekmachine aanwezig moeten zijn.
Zoeken op geluid is zelfs voor professionele zoekmachines een niet-standaardfunctie. De essentie ervan is dat het programma zoekt naar woorden die hetzelfde klinken als het woord dat u hebt ingevoerd. En het beste is: deze functie werkt ook voor de Russische taal! Wanneer u bijvoorbeeld het woord ‘oor’ in een zoekopdracht typt, ziet u niet alleen de woorden ‘oor’ maar ook ‘oor’ als resultaat.
Zoeken met foutcorrectie - zeer belangrijke functie. Het wordt gebruikt om te zoeken naar woorden die syntactische fouten bevatten. Dit kunnen bijvoorbeeld typfouten zijn of fouten in documenten die zijn verkregen met behulp van tekenherkenningssystemen. Een eenvoudig voorbeeld: u zoekt naar het woord toetsenbord. Sommige documenten bevatten het woord “toetsenbord”, het is duidelijk dat dit in feite het woord “toetsenbord” is, de persoon heeft zojuist een typefout gemaakt tijdens het typen. Bij een foutcorrectiezoekopdracht wordt dus een document met het woord 'toetsenbord' in het resultaat gedetecteerd en opgenomen. Er is ook een instelling in dtSearch waarmee u de mate van mogelijk foutieve tekens kunt bepalen.
Zoek met synoniemen. Deze functie gebruikt een lijst met synoniemen voor verschillende woorden. Door bijvoorbeeld het woord “snel” in te voeren, zal het programma ook de woorden “hoge snelheid” en andere woorden vinden die synoniemen zijn voor het woord “snel”, als ze natuurlijk aanwezig zijn in de lijst met synoniemen . Er wordt geen kant-en-klare lijst met synoniemen meegeleverd met het programma dtSearch, maar het is wel mogelijk om lijsten op internet te gebruiken (daarvoor is een verbinding vereist, wat niet altijd handig is), of u kunt uw eigen lijst met synoniemen maken .
Naast de genoemde mogelijkheden kan dtSearch zoeken met behulp van woordgroepen die bestaan uit woorden die met elkaar verbonden zijn door logische bewerkingen. Aan elk woord in een zoekopdracht kan een eigen ‘gewicht’ worden toegekend, dat wil zeggen betekenis. Een handige optie is om een woordenboek met onbelangrijke woorden te gebruiken om daar bij het zoeken geen rekening mee te houden, maar ook dit woordenboek is leeg en zul je zelf moeten invullen.
Laten we vervolgens eens kijken naar de mogelijkheden van het programma bij het werken op het netwerk. In feite biedt dtSearch geen specifieke mogelijkheden voor het werken met het netwerk. Het is echter heel goed mogelijk om het online te gebruiken. Als alternatief kunt u een soort index maken en deze in een openbare (gedeelde) map plaatsen. Het programma zelf kan op de computer van elke gebruiker worden geïnstalleerd, of het kan ook in een geopende map worden geplaatst publieke toegang en maak op een speciale manier snelkoppelingen voor elke gebruiker afzonderlijk, met behulp van opdrachtregelparameters, waarvan het doel wordt beschreven in het helpbestand dat bij het programma wordt geleverd. Het is ook mogelijk om het programma automatisch op het netwerk te installeren met behulp van een MSI-bestand. Hierbij wordt rekening gehouden met de instellingen voor elke verbonden gebruiker.
Over het algemeen is het een goed programma uit de categorie van professionele zoekmachines. Het komt misschien in aanmerking voor een goede beoordeling, maar het winnen van vertrouwen en respect van gebruikers is misschien niet eenvoudig voor dtSearch vanwege bepaalde factoren (niet alles verloopt soepel met de interface, Russische gebruikers zijn beroofd, er zijn geen slimme functies om met het netwerk te werken) . Wat het direct zoeken naar documenten betreft, had het programma geen problemen met Russische tekst. Omdat er geen waren met de aangegeven morfologie, of met een vage zoektocht. Het systeem vond behoorlijk adequaat de benodigde documenten, zowel voor een eenvoudige zoekopdracht van één woord als voor gebruik als belangrijkste zin een paar paragrafen, een document.
Officiële site:
Distributiegrootte: 23 Mb Bloodhound Prof Deluxe
Op basis van de naam kun je raden dat er ondersteuning is voor de Russische taal in dit programma. Dit is al leuk. Wat de interface betreft, deze is over het algemeen enigszins ongebruikelijk, maar qua uiterlijk is deze zeer aantrekkelijk. Een ander ding is gemak. Een zeer controversieel criterium, maar toch is een oplossing met meerdere vensters waarschijnlijk niet de meest succesvolle optie (het verzoek wordt in het ene venster ingevoerd, het resultaat wordt in een ander venster weergegeven en dergelijke).
Snoop gebruikt dezelfde indexen om snel te zoeken, maar het indexeren gaat veel langzamer dan bij andere programma's. Dit is heel vreemd, vooral gezien het feit dat de mogelijkheden voor het verwerken van zoekopdrachten erg zwak zijn, en daarom is de indexstructuur niet complex. Hoogstwaarschijnlijk komt dit door niet-geoptimaliseerde algoritmen. Dit programma bleek een duidelijke buitenbeentje wat betreft indexerings- en zoeksnelheden: de tijd die besteed werd aan het maken van de index was zes keer langer dan bij dezelfde dtSearch en iSYS. Het indexeren van 20 gigabyte aan teksten voor de bloedhond leverde 38 uur en 46 minuten werk op. En het gecreëerde "zoekgebied" nam op de harde schijf dezelfde grootte in beslag als de originele gegevens met een kleine min - 19 gigabyte.
Bloedhond kan als alternatief worden gepresenteerd standaard zoeken in Windows is het nauwelijks tot meer in staat. Over het feit dat de Bloedhond de eerste prioriteit heeft eenvoudig zoeken bestanden wordt niet alleen aangegeven door een klein aantal functies voor het analyseren van de tekst van zoekopdrachten en een geavanceerd zoeken op bestandskenmerken, maar zelfs door een resultatenvenster dat directe links biedt naar de gevonden bestanden, evenals naar de mappen die deze bestanden bevatten. Het resultatenvenster is niet erg informatief in die zin dat u het volledige gevonden bestand alleen kunt lezen door het uit te voeren, dat wil zeggen dat het geen ingebouwde bestandsviewer heeft. Maar een uittreksel uit het bestand waarin het gezochte woord werd gevonden, wordt weergegeven; over het algemeen doet dit weergaveschema sterk denken aan internetzoekmachines.
Als we het hebben over de specifieke mogelijkheden voor het verwerken van zoekopdrachten, dan is het de moeite waard om op te merken dat er niet zoiets bestaat als “zoektekst”; het maximum dat kan worden doorzocht is een zin, al was het maar omdat er geen tekstinvoerveld met meerdere regels is. U kunt de ingevoerde zin echter ook analyseren, en Snoop biedt ons hier een standaardzin aan: zoek ingesteld: logische bewerkingen, zoeken naar maskers en zoeken naar aanhalingstekens... niet veel. Het programma bevat enkele beginselen van morfologisch onderzoek, maar waarschijnlijk zo grof dat het nogal interfereert correcte werking(tijdens het testen werden veel overlays met onjuist gebruik van de morfologie opgemerkt).
Maar met het programma kunt u bij het zoeken bestandskenmerken opgeven (documentdatum, bestandsnaam, mapnaam), en bij deze zoekopdrachten kunt u ook dezelfde zoekset gebruiken. U kunt ook naar letters zoeken door de parameters op te geven (Van, Onderwerp..., enz.).
Dus we hebben de zoektocht zelf ontdekt, wat is er nog meer interessant aan het programma, waarvoor het zoveel prijzen heeft ontvangen, volgens informatie van de officiële website? Het is moeilijk te zeggen wat er zo speciaal aan is; hoogstwaarschijnlijk is de Bloodhound-interface aantrekkelijk (precies qua uiterlijk, om nog maar te zwijgen van de bruikbaarheid).
Bewerkingen met indexen zijn zeer standaard; een leuke functie is de mogelijkheid om indexen volgens een schema bij te werken. Daarnaast kunnen indexen ook online worden gebruikt. Vanaf nu hebben we meer details nodig.
Ondanks de primitiviteit van zoekopdrachten kan het programma worden gebruikt om naar bestanden te zoeken, zodat het gebruik ervan in netwerken kan worden gerechtvaardigd. Hoewel met grote reserve, aangezien in groot netwerk prioriteit is Snelzoeken gegevens met behulp van complexe zoekopdrachten vanwege de enorme hoeveelheid informatie - en er zijn duidelijk problemen met de snelheid van het zoeken en het programma. Ik moet zeggen dat het werk met het netwerk bij Izhishika is doordacht zoals het hoort. Speciaal hiervoor is een aparte applicatie ontworpen: Bloodhound Server. Het werkt op dezelfde manier als Snooper (ze hebben dezelfde zoekmachine), alleen voor documenten die worden gehost op een centrale server of op gedeelde bronnen in bedrijfsnetwerk. Snooper Server maakt nieuwe indexen op gedeelde bronnen of gebruikt eerder gemaakte indexen. Elke gebruiker van het bedrijfsnetwerk kan verbinding maken met de zoekserver en deze gebruiken om toegang te krijgen tot elk document (dat zich in de huidige index bevindt) met behulp van een internetbrowser. Mee eens, dit schema is buitengewoon handig: het blijkt dat bestanden op je eigen netwerk op dezelfde manier kunnen worden doorzocht als informatie op internet via bijvoorbeeld Google.
Als we alle voor- en nadelen van dit programma beoordelen, suggereert de conclusie dat de mogelijkheden ervan hoogstwaarschijnlijk niet voldoende zijn voor bedrijfsnetwerken (ondanks de goede organisatie van het werken met het netwerk), maar voor een thuiscomputer of zelfs voor een thuisnetwerk is dit wel het geval. In principe zou het wel eens kunnen gebeuren. Hoewel noch de snelheid van het werk, noch de zoekmogelijkheden optimisme inboezemen...
Officiële website in het Russisch:
Distributiegrootte: 6 MbGoogle Desktop Search + GDS Enterprise 
Natuurlijk konden we zo’n beroemde ontwikkelaar niet negeren. Google-naam zegt al veel. Mensen die al jaren de krachtigste internetzoekmachine gebruiken, zullen zeker, zonder enige twijfel, besluiten deze specifieke zoekmachine op hun computer te installeren. Denk maar eens na: Google op je thuiscomputer! Laten we echter, zonder toe te geven aan provocaties met een veel gepromoot merk, nuchter en vooral objectief proberen de mogelijkheden van de ‘desktop’-zoekmachine van Google te overwegen.
Het eerste dat opvalt is het ontbreken van een eigen shell voor het programma. Google Desktop Search bevindt zich nog steeds in het browservenster, respectievelijk de volledige interface van de desktopversie is overgenomen van de software van zijn oudere internetbroer. Of dit goed of slecht is, is een punt van discussie: sommige mensen houden van het minimalisme in het ontwerp van deze zoekmachine, terwijl anderen een volwaardige applicatie willen zien gevuld met allerlei knoppen enzovoort.
Wat valt direct na het ontwerp op? En het feit dat dezelfde Google Desktop Search alles op de computer begint te indexeren, zonder enige vraag! En wat het meest interessant is, is om wanneer indexeringspaden te kiezen Google-hulp Desktop Search is niet mogelijk. Je zult een apart programma (TweakGDS) moeten downloaden, waarmee je iets kunt uitbreiden Google-instellingen Desktop, inclusief het opgeven van de plaatsen die nodig zijn voor indexering. Hoewel, tegen de tijd dat je het allemaal doorhebt, standaard harde schijf het zal al indexeren, dus een dergelijke instelling is waarschijnlijker nodig bij het werken met grote hoeveelheden gegevens, wat erg belangrijk is bij gebruik in bedrijfsnetwerken (Enterprise-versies). Het is echter geen feit dat na het downloaden van TweakGDS uw problemen opgelost zullen zijn. Om te kunnen werken zijn immers Microsoft .NET Framework en Microsoft Scripting Runtime nodig. Ja... de installatie, evenals de toegang tot de instellingen, had eenvoudiger gekund, hoewel de ontwikkelaars het waarschijnlijk wel begrijpen: waarom iets nieuws schrijven als er een kant-en-klare zoekmachine is, deze naar de lokale computer porteren en laten de gebruiker ‘geniet’, en een bekende naam zal van ‘dit’ weer een meesterwerk maken. Oké, laten we het hier beëindigen lyrische uitweiding en laten we verder gaan met zoeken.
Wat betreft het analyseren van zoekopdrachten en het leveren van resultaten, alles is hier absoluut identiek aan Google op internet: hetzelfde systeem voor het weergeven van resultaten, dezelfde standaardreeks logische bewerkingen voor zoekopdrachten. IN algemeen Google Desktop Search, zoals vorig programma, is uitsluitend bedoeld voor het zoeken naar bestanden - het heeft uiteraard geen interne viewer voor deze bestanden. Het aantal bestandsformaten dat door Google Desktop Search wordt ondersteund is ruim voldoende, en het is ook prettig dat het bezochte internetpagina's doorzoekt en gegevens uit de cache haalt. Zoek- en indexeringssnelheden zijn zeer acceptabel. Klopt, voor thuis gebruik. Google Desktop Search verwerkte maar liefst 20 gigabyte aan teksten in 8 uur en 17 minuten. Een aantal dagen besteden aan het verwerken van informatie uit het bedrijfsnetwerk van een grote onderneming is niet iets wat iedere systeembeheerder graag zou doen. Aan de positieve kant: de grootte van de gemaakte index was op hetzelfde niveau (4,5 GB) als een andere zoekmachine die in deze review werd getest: SearchInform.
Het grote voordeel (of nadeel – jij bepaalt) van Google Desktop Search is dat het plug-ins ondersteunt, die veel ten goede kunnen veranderen. Een ander ding is dat het aansluiten van plug-ins en het instellen ervan de taak van het installeren van een zoekmachine zo ingewikkeld maakt dat je je begint af te vragen of dit allemaal nodig is als je een normaal, volwaardig programma kunt installeren waarin alles al aanwezig zal zijn. Om elke functie te kunnen gebruiken, moet u deze immers installeren nieuwe plug-in. Zelfs om het programma volledig met archieven te laten werken, is een aparte gadget nodig. Het is fascinerend en verleidelijk dat al deze aanvullende modules gratis zijn. Als u echter geen rekening houdt met de desktopversie van de zoekmachine, ligt de competente configuratie van GDS Enterprise mogelijk niet binnen uw macht - het is immers niet voor niets dat specialisten van Google hun diensten aanbieden voor het opzetten van hun eigen software voor uw netwerk voor slechts $ 10.000.
Als u de installatie- en installatieprocedure doorloopt (of $ 10.000 betaalt aan een snelle responsteam van Google), zult u begrijpen dat de complexiteit van de installatie ruimschoots wordt gecompenseerd door de zeer flexibele instellingen bij gebruik in bedrijfsnetwerken. Een belangrijk punt Google-werk Desktop op een bedrijfsnetwerk is het gebruik groepsbeleid, waardoor het mogelijk is om instellingen voor elke gebruiker in te stellen.
Samenvattend: het meest redelijke gebruik van dit programma is een thuis- of werkcomputer. Immers, voor gewone computer U hoeft alleen maar het programma te installeren - het doet de rest zelf (het vraagt u niet eens iets).
Google Desktop Search Enterprise zal echter acceptabel zijn in gevallen waarin er dringend behoefte is aan een flexibele configuratie van het netwerkbeleid om de zoekmachine te gebruiken, terwijl de mogelijkheid om zoekopdrachten te verwerken op de tweede plaats komt qua belang, en de tijd (of het geld) die nodig is om de zoekmachine te gebruiken. ) die aan het opzetten van het programma worden besteed, komt op de eerste plaats.
Officiële site:
Distributiegrootte inclusief TweakGDS: 1,2 MbCopernic Desktop Search 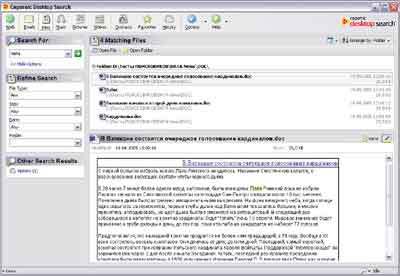
Klik op de afbeelding om te vergroten
De programma-interface roept uitsluitend op positieve emoties- alles gebeurt volgens algemeen aanvaarde normen, niets overbodigs, kortom een prettig ontwerp. Voor een beginner zal het begrijpen van de Copernic Desktop Search-interface heel eenvoudig zijn. Hoewel het enigszins verwarrend is dat de ontwerpers de programma-interface duidelijk hebben gemaakt, rekening houdend met het feit dat het programma zal werken in het standaard Windows XP-thema. Bij gebruik van het klassieke thema ziet het programma er niet zo mooi uit. Maar dit is meer een kwestie van smaak.
Bij de eerste keer opstarten vraagt het programma u om indexen voor zoeken te maken. Het leek enigszins ongebruikelijk dat het programma na het selecteren van mappen voor indexering niet aanbood om op een knop te drukken, zoals "Start indexering", en het indexeren startte niet automatisch. Pas toen werd opgemerkt dat Copernic probeerde te beginnen met indexeren terwijl de computer was inactief. Je zult wat dieper in de programma-opties moeten graven om alles goed te configureren. Opgemerkt moet worden dat het er nogal wat zijn volop mogelijkheden bij het instellen automatische creatie index: ingebouwde planner, de mogelijkheid om te indexeren terwijl de computer inactief is, op de achtergrond, met lage prioriteit. Het indexeren ging niet al te snel - 10 uur en 51 minuten - dit is langzamer dan bij andere zoekmachines (behalve Issher, maar nog steeds Copernic snellere ontwikkeling iSleuthHound Technologies is een orde van grootte.
Nu over de structuur van de index. Over het algemeen is er niets bijzonders aan. Het is mogelijk om bestandstypen te selecteren, zowel in algemene als gedetailleerde vorm. Dat wil zeggen dat u in eerste instantie kunt kiezen wat u wilt indexeren: documenten, afbeeldingen, video's, muziek. Op het andere tabblad van het optievenster kunt u specifieke bestandstypen op extensie selecteren. Bovendien kunt u de index zo configureren dat bijvoorbeeld afbeeldingen die kleiner zijn dan 16x16 niet worden geïndexeerd of geluidsbestanden die korter zijn dan 10 seconden niet worden geïndexeerd. Naast het indexeren van bestanden uit mappen, kan Copernic werken met e-mails en contacten uit adresboek Microsoft Outlook en Microsoft Outlook Express, indexering van Favorieten en Geschiedenis vanuit Internet Explorer is mogelijk.
Wat de zoekmogelijkheden betreft, deze zijn hier erg zwak. Tijdens tests bleek zelfs dat het programma niet naar documenten zoekt txt-formaten en html in het Russisch, zodat u ze alleen op kop kunt vinden, en niet op inhoud. Het enige dat het programma biedt om de zoekefficiëntie te verbeteren is het gebruik van een standaardset logische bewerkingen, en zelfs toen werd deze functie experimenteel ontdekt, omdat deze niet gedocumenteerd was. Trouwens, de hulp van het programma is ook niet in orde - het is alleen beschikbaar via internet, wat, zoals je ziet, erg lastig is, en er is niet al te veel hulpinformatie op internet. Blijkbaar hebben de ontwikkelaars besloten dat de eenvoudige interface van het programma niet de aanwezigheid van normale hulp impliceert. Als we het gesprek over de zoekmogelijkheden voortzetten, moet worden opgemerkt dat het programma, ondanks de zwakke analyse van zoekopdrachten, een interessant zoeksysteem biedt: de gebruiker kan het type bestanden selecteren (afbeeldingen, video's, muziek, enz.), een zoekopdracht invoeren query en selecteer kenmerken die specifiek zijn voor het geselecteerde bestandstype. Voor geluidsbestanden kunnen dit bijvoorbeeld waarden zijn van mp3-tags (artiest, album, datum, enz.), voor afbeeldingen kunt u bijvoorbeeld hun grootte selecteren (op resolutie), over het algemeen heeft elk type zijn eigen eigen instellingen. Nadat u naar een specifiek bestandstype heeft gezocht, geeft het programma een zeer informatieve lijst weer in het resultatenvenster. Als uw verzoek ook bestanden van andere typen bevat, kunt u deze openen door op een specifieke link te klikken.
Afzonderlijk is het de moeite waard om het weergavevenster voor resultaten te vermelden. Onder de lijst met gevonden bestanden wordt de inhoud van deze bestanden weergegeven (een soortgelijk schema wordt vaak gebruikt in e-mailclients). Het is waar dat het bekijken van tekst alleen in het oorspronkelijke formaat kan worden gedaan, en er is geen weergavemodus voor platte tekst, wat niet altijd handig is, omdat het openen van een document in dit geval meer tijd kost. Maar aangezien Copernic kan zoeken naar afbeeldingen en muziek, is het wel mogelijk om deze multimediabestanden te bekijken.
De basisprincipes van de werking van dit programma worden beschreven, laten we nu eens kijken wat Copernic Desktop Search ons te bieden heeft voor het werken met het netwerk... In principe kun je heel lang kijken, maar je zult nauwelijks iets zien . Met andere woorden: dit programma was niet bedoeld als netwerkgebaseerd programma. Copernic Desktop Search is exclusief een thuiszoekmachine.
Het is duidelijk dat de enige (meest logische) toepassing van dit programma is thuis computer. Hier kan het volledig omgaan met alle eenvoudige zoekopdrachten van gebruikers bestaande uit één of twee woorden, zal het de nodige informatie vinden, en de verdeling van het zoeken op bestandstype en ondersteuning voor multimediabestanden samen met achtergrondindexering in lage prioriteitsmodus, gekoppeld aan een prettige interface, geef het programma alleen de kracht om vertrouwen te winnen bij onervaren gebruikers.
Officiële site
Distributiegrootte: 2,6 MbISYS Desktop 
Klik op de afbeelding om te vergroten
Erg krachtig programma. Qua uitrustingsniveau met allerlei functies zit hij ergens in de buurt van het volgende SearchInform-zoeksysteem op de lijst. Bovendien is de grootte van het installatiebestand ruim 40Mb! Het is moeilijk te zeggen wat er in dergelijke dimensies kan worden geperst, omdat dezelfde SearchInform, met vergelijkbare functionaliteit, 15 MB in beslag neemt.
Het installatieproces is hier ook niet erg prettig, of liever gezegd niet eens het installatieproces. Zelfs voordat u het programma downloadt, wordt u gevraagd zich te registreren, anders is er geen mogelijkheid. Vervolgens de interface. Het is heel mooi gemaakt, er valt niets onnodigs op, maar het zijn indrukken van iemand die er al enigszins aan gewend is. Het zal voor een beginner niet gemakkelijk zijn om erachter te komen waar en wat zich bevindt, waar hij moet klikken en waar hij uiteindelijk moet zoeken. Het wordt ten zeerste aanbevolen om de Help te lezen voordat u met het werk begint - u bespaart veel zenuwen en tijd. Aan al het andere wordt het ook toegevoegd volledige afwezigheid Ondersteuning voor de Russische taal in het programma. Niet goed. Bovendien zijn de vensters hier niet overladen met bedieningselementen, maar moesten we hiervoor betalen met multimodules en het gebruik van extra vensters. Zoekopdrachten worden bijvoorbeeld ingevoerd door het ene programma te starten, en het indexbeheer wordt uitgevoerd met een ander programma. Zoekopdrachten worden hier ook in aparte pop-upvensters ingevoerd. Het is moeilijk te zeggen wat beter is: een overbelaste interface of alomtegenwoordige meerdere vensters, het is eerder een kwestie van smaak.
Als het gaat om het maken van indexen, biedt het programma functies om het proces van het instellen van opties voor een nieuwe index te vereenvoudigen. Deze functies omvatten verschillende kant-en-klare sjablonen voor het maken van indexen voor de map “Mijn documenten”, “Mail”, “Mail en documenten”, “Specifieke map”, “Map met een selectie van bestandstypen”, enz. Dergelijke sjablonen vereenvoudigen het creatie van indexen in de eerste fase. Het hulpprogramma voor het werken met indexen heeft geen erg goede interface, wat enigszins intimiderend is (dit is behoorlijk subjectieve beoordeling, om eerlijk te zijn), maar als je er eenmaal naar kijkt, biedt het veel nuttige opties en over het algemeen is het gebruik ervan niet bijzonder moeilijk. ISYS Desktop kan gegevens uit verschillende gegevensbronnen indexeren en biedt ook veel flexibele instellingen voor dergelijke indexering. Extra indexeringsfuncties zijn onder meer: ondersteuning voor SQL, FTP, TRIM Context, WORLDOX 2002, scripts. Wanneer u bij het maken van een index het item "Map met selectie van bestandstypen" hebt geselecteerd, heeft u de mogelijkheid om bestandstypen te selecteren voor handmatige indexering (per extensie). Het moet gezegd dat er simpelweg een enorm aantal ondersteunde bestandstypen zijn, maar voeg daar je eigen type (extensie) aan toe bestaande lijst het zal niet werken. U kunt ook de aanwezigheid van een indexeringsplanner opmerken. Het maken van een index en het verwerken van 20 gigabyte aan informatie kostte ISYS Desktop 6 uur en 13 minuten, wat uiteindelijk een goede tijd en de grootte van het gemaakte bestand liet zien: 7,9 GB.
De zoekmogelijkheden van dit programma zijn redelijk goed. Wat in ISYS wordt gebruikt, is veel krachtiger gebruikelijke ondersteuning logische operaties. Onder de geavanceerde zoekmogelijkheden biedt het programma het gebruik van synoniemen en een sorteerfilter (op pad, naam en datum van bestandsaanmaak). Kit logische operatoren iets breder dan de standaardset. Naast logische bewerkingen kunt u met het programma met veel andere operators werken, die in principe sommige soorten zoekopdrachten kunnen vervangen. Zoeken met parseren kan bijvoorbeeld volledig worden vervangen door het gebruik van speciale operatoren. Ik was zeer verrast dat het programma geen zoekfunctie heeft met behulp van morfologie. Dit is een ernstige omissie, aangezien de zoekefficiëntie aanzienlijk wordt verbeterd bij gebruik van morfologische analyse. Bovendien is er geen lijst met significante woorden, maar wel een uitgebreide lijst met onbelangrijke woorden. Ook aangekondigd zijn zoekfuncties als " ruwe zoektocht" en "heuristische analyse".
ISYS biedt keuze uit verschillende soorten zoekopdrachten, namelijk visuele. Dit wordt gedaan met behulp van verschillende soorten vensters voor het invoeren van zoekopdrachten, maar in feite staat geen enkel venster het gebruik van andere technologieën toe dan de hierboven genoemde.
De zoekresultaten zijn zeer informatief en worden weergegeven als een lijst met documenten, gesorteerd op relevantie. Hieronder wordt een voorbeeld van het geselecteerde document weergegeven. In tegenstelling tot Copernic Desktop Search is de preview hier alleen beschikbaar in de vorm van platte tekst; het was niet mogelijk om documenten in hun oorspronkelijke formaat weer te geven, of het nu Word, Html of PDF is, hoewel dit in principe niet al te kritisch is. Met het programma kunt u gevonden documenten in groepen verdelen volgens bepaalde criteria (standaard zijn ze onderverdeeld op relevantie). U kunt reeds gevonden documenten ook bekijken door individuele mappen te selecteren (dit is handig als het resultaat een zeer groot aantal documenten oplevert).
Het gebruik van het programma op een bedrijfsnetwerk is ook zeer gerechtvaardigd, omdat het goede mogelijkheden biedt voor het organiseren van netwerkzoekopdrachten. Het zoeksysteem is gebaseerd op het creëren van een openbare index die geïndexeerde gegevens bevat uit openbaar beschikbare online bronnen.
In feite is het programma van ISYS de aandacht waard, tenminste om er kennis mee te maken. Dit programma is een volwassen project met een groot aantal functies (niet altijd en niet iedereen heeft ze natuurlijk nodig, maar toch). De kans dat het programma enige verbeteringen zal zien op het gebied van het verwerken van zoekopdrachten is onbekend, maar op dit moment kan het worden aanbevolen voor vrijwel universeel gebruik. En aangezien het nog steeds te zwaar is voor thuissystemen, zijn bedrijfsnetwerken de belangrijkste plaatsen voor installatie.
Officiële site:
Distributiegrootte: 40 MbSearchInform 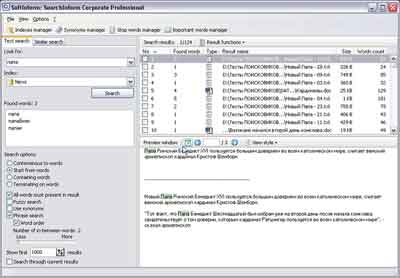
Klik op de afbeelding om te vergroten
Het is waarschijnlijk niet de moeite waard om meteen te beginnen met een beschrijving van de SearchInform-interface. We moeten eerst het installatieproces beschrijven, of beter gezegd een van de details ervan: u kunt het programma niet installeren zonder een internetverbinding. Feit is dat het programma vóór de eerste lancering gebruikersregistratie (gratis) vereist en alle ingevoerde gegevens naar de server verzendt. Blijkbaar moesten de ontwikkelaars dergelijke maatregelen nemen in de strijd tegen piraterij, maar dit had geen positief effect op het installatiegemak.
De programma-interface is ontworpen in overeenstemming met alle algemeen aanvaarde regels, maar is op het eerste gezicht enigszins omslachtig. Als je het programma voor de eerste keer gebruikt, lijkt het te ingewikkeld, soms is het niet gemakkelijk om te onthouden in welk menu of op welk tabblad de gewenste optie zich bevindt, maar met meer langdurig gebruik, lijkt de interface niet langer zo vreselijk complex. Het belangrijkste is om eerst het certificaat te lezen.
Nadat u de interface een beetje heeft begrepen, kunt u beginnen met het maken van een index. Het proces zelf is heel eenvoudig en de indexeringssnelheid is, zelfs op het oog, aanzienlijk hoger dan bij alle andere zoekmachines in de recensie. Duidelijke testcijfers laten zien dat SearchInform qua indexeringssnelheid twee keer zo snel is als dtSearch en iSYS! Het programma indexeerde de aangeleverde gegevens in een hoeveelheid van 20 gigabyte in een recordtijd van 3 uur en 17 minuten. En de grootte van de gemaakte index bleek de kleinste 4,4 GB te zijn - 100 megabytes minder dan Google Desktop Search.
Het programma ondersteunt naast reguliere bestanden en mappen ook het indexeren van e-mails, het verbinden en indexeren van databases (!) en meer externe bronnen(DMS, CRM), kunt u direct tijdens het indexeren een woordenboek opgeven voor het uitvoeren van een morfologische zoekopdracht en kunnen alle bestandskenmerken worden geïndexeerd. Nadat u de index hebt gemaakt, kunt u bij het uitvoeren van de eerste testzoekopdracht voor documenten enigszins in de war raken: "Er zijn hier twee soorten zoekopdrachten, maar welke heb ik nodig?" Zoals eerder vermeld, is het belangrijkste om het certificaat te lezen, dan wordt alles duidelijk. Het programma kan feitelijk twee soorten zoekopdrachten uitvoeren: zoeken op zinsdelen en zoeken naar documenten die qua inhoud vergelijkbaar zijn met de zoektekst.
Beschrijving van alle hoofdfuncties voor analyse zoekopdracht werd hierboven gegeven, dus nu zullen we alleen de zoekmogelijkheden van dit programma vermelden. Laten we beginnen met zoeken op zinsdelen: natuurlijk zoeken op morfologie, zoeken op citatie, logische bewerkingen, zoeken met woordparsering (zoeken aan het begin van het woord, aan het einde, in het middengedeelte of een volledige overeenkomst), zoeken op gemengde citaten ( wanneer alle woorden uit de zoekopdracht in het document aanwezig moeten zijn, maar niet noodzakelijkerwijs in de ingevoerde volgorde), zoeken met foutcorrectie, gebruik van synoniemen, “bijna citatie zoeken” (zoeken naar de ingevoerde zin als citaat, maar andere woorden mogen ook aanwezig zijn tussen de ingevoerde woorden), etc. Sommige van de genoemde opties hebben hun eigen specifieke instellingen. Bovendien is het mogelijk om een woordenboek met onbelangrijke woorden te gebruiken, en dat heeft het programma al gedaan klaar lijst deze woorden kunt u ook zoeken in het woordenboek met prioriteitswoorden (deze moet u uiteraard zelf invullen).
Hier hebben we in principe kort alle belangrijke kenmerken van het zoeken op zinsdelen besproken.
Laten we verder gaan met het bekijken van de kenmerken van dit programma: zoeken naar vergelijkbare documenten. De ontwikkelaars beweren dat dit geenszins een eenvoudige tekstzoekopdracht is, het is juist een “zoektocht naar soortgelijke” - dit is precies hoe het overal wordt beschreven, maar ach, je kunt het noemen hoe je wilt - het belangrijkste punt is . Een snelle zoektocht op internet kan snel uitwijzen dat het zogenaamde "similar search" een nieuwe ontwikkeling is op het gebied van tekstanalyse. Met dit systeem kunt u teksten vinden die qua semantische inhoud vergelijkbaar zijn. Het leukste was dat na het uitvoeren van proefzoekopdrachten bleek dat de theorie behoorlijk goed aansluit bij de praktijk! Het programma zoekt feitelijk naar documenten met vergelijkbare inhoud en geeft deze weer in een lijst, waarbij ze worden gesorteerd op percentage van gelijkenis.
Laten we vervolgens eens kijken naar wat SearchInform (in het bijzonder de bedrijfsversie SearchInform Corporate) te bieden heeft voor het werken op een bedrijfsnetwerk. Er zijn twee soorten applicaties: serverzijde en gebruikerszijde. Servergedeelte Het verwerkt automatisch de opgegeven indexen en gebruikers kunnen deze gebruiken om te zoeken, afhankelijk van de toegangsrechten die eraan zijn toegewezen. Gebruikers kunnen automatisch worden geconfigureerd met Rekeningen Windows (professioneel gezien gebruikt SearchInform NTFS Windows-authenticatie) en handmatig (gebruikers zullen apart moeten worden toegevoegd). Elke gebruiker kan toegang tot bepaalde indexen worden toegestaan of geweigerd, en gebruikers kunnen ook in groepen worden gecombineerd. Over het algemeen lopen de instellingen van SearchInform voor het werken op het netwerk voor op Google in termen van flexibiliteit, en op Ishhound Server in termen van gemak en eenvoud.
Officiële site:
Distributiegrootte: 14,7 Mb Vergelijking van indexeringssnelheden
| Zoeksysteem | Indexeringstijd | Indexgrootte |
| Bloedhond Prof Deluxe 4.5 | 38 uur 46 minuten | 19 GB |
| Isys Desktop 7.0 | 6 uur 13 minuten | 7,9 GB |
| DtSearch 7.0 | 6 uur 3 minuten | 8,6 GB |
| Google Desktop Search Enterprise | 8 uur 17 minuten | 4,5 GB |
| Copernic Desktop Zoeken * | 10 uur 51 minuten | 7 GB |
| ZoekInform 1.5.02 | 3 uur 17 minuten | 4,4 GB |
* De meeste documenten.html en .txt die Russische tekst bevatten, waren, hoewel ze geïndexeerd waren, onmogelijk te vinden, behalve op basis van hun naam
Alle programma's verdienen de aandacht.
Op basis van tests en een zorgvuldig onderzoek van elk programma dat in de review wordt gepresenteerd, kunnen bepaalde conclusies worden getrokken. Google Desktop Search Copernic Desktop Search is dus prima geschikt voor de onervaren gebruiker als zoeksysteem voor woninginformatie. Ze kunnen goed omgaan met eenvoudige vragen, overbelasten de gebruiker niet met instellingen en zijn bovendien volledig gratis. De poging van Google om de markt voor zakelijke zoekmachines te betreden is nog niet erg gerechtvaardigd: volwaardig werk het programma moet worden bijgewerkt extra modules, en het is verre van eenvoudig in te stellen. Daarom reserveren de voor zichzelf sprekende namen Desktop Search, Copernic en Google de niche van “desktop” zoekmachines.
Het is waar dat krachtigere oplossingen - dtSearch, iSYS en SearchInform ook niet waterdicht zijn en gebruikers hun "desktop" -versies bieden. Maar tegen een redelijke prijs, in tegenstelling tot gratis software van Google en Copernic. Natuurlijk moet je betalen voor kracht, snelheid en functionaliteit. Maar de belangrijkste focus van de ontwikkelaars van dtSearch, iSYS en SearchInform ligt uiteraard op het bedrijfsleven. Netwerken, functionaliteit, indexering en zoeksnelheid zijn wat deze producten onderscheiden van hun ‘concurrenten’. Op basis van de testresultaten werd de favoriet geïdentificeerd: SearchInform. Het programma biedt de mogelijkheid om naar vergelijkbare documenten te zoeken hoogste snelheid indexeren en zoeken, heeft een goede set functies.
Hoe snel te vinden benodigde tekst tussen veel bestanden? Soms doet zich een situatie voor waarin u snel een bepaalde tekst moet vinden die zich in een bestand bevindt waarvan de naam onbekend is, en het bestand zelf zich bevindt tussen een groot aantal van dezelfde (of zelfs andere typen) bestanden.
Een student moet bijvoorbeeld het antwoord op een vraag vinden tussen tientallen collegeaantekeningen in elektronisch formaat, een huisvrouw moet een recept vinden in een receptenmap, een systeembeheerder moet mogelijk informatie vinden over een applicatiefout tussen honderden logbestanden, een programmeur moet een bepaalde code vinden tussen duizenden broncodes.
Wat te doen in dit geval? Natuurlijk kun je elk bestand achtereenvolgens openen en erin zoeken, maar als er veel van dergelijke bestanden zijn, zal dergelijk werk zeer binnenkort routinematige marteling worden.
In dit geval is het beter om hulp te zoeken speciale middelen, speciaal ontworpen voor deze doeleinden en waarmee u snel tekst kunt vinden. Een voorbeeld van zo'n tool is het FileSearchy-bestandszoekprogramma.Het programma is gratis voor persoonlijk gebruik, u kunt het downloaden van de website van de ontwikkelaar. Er is een betaalde versie, de verschillen daartussen zijn ook te zien op de website.
Met het bestandszoekprogramma FileSearchy kan naar tekst worden gezocht grote hoeveelheden bestandsformaten, de meest voorkomende: .doc, .docx, .xls, xlsx, .ppt, pptx, .pdf, .txt. Betaalde versie Het programma kan ook naar tekst zoeken in elektronische boekbestanden (EPUB, FB2 en MOBI).
Programmeer bedieningsmodi voor het zoeken naar bestanden
Het programma kan in twee modi werken:- in modus direct zoeken
- in de geavanceerde zoekmodus.
Direct zoeken
In de Instant Search-modus werkt het bestandzoekprogramma wanneer de zoekbalk verborgen is. In deze modus kunt u alleen naar bestanden zoeken op naam, die in één veld moet worden ingevoerd. Om naar een bestand te zoeken, voert u gewoon de bestandsnaam in, of zelfs een deel van de naam, of de extensie. De gevonden resultaten verschijnen terwijl u typt.Kenmerken van deze modus:
- Om op te nemen of uit te sluiten bepaalde namen bestanden, moet u op de knop met de afbeelding van drie stippen rechts van het tekstinvoerveld klikken en in het venster dat verschijnt invoeren wat u nodig heeft, of omgekeerd, u hoeft niet te zoeken.
- U kunt hoofdlettergevoelig naar bestanden zoeken. Om dit te doen, moet u het vakje aanvinken Zoeken | Hoofdlettergevoelig.
- Om het type uitdrukking dat u zoekt te selecteren, moet u naar het menu gaan Zoeken | Expressietype en selecteer de juiste modus (subtekenreeks, volledig woord of reguliere expressie). Dit zal hieronder in meer detail worden besproken. Standaard is Substring geselecteerd, en in de meeste gevallen is dit voldoende.
geavanceerd zoeken
In de geavanceerde modus moet u minimaal een bestandsnaam invoeren en op de zoekknop klikken. Net als in de directe zoekmodus kunt u zowel de volledige bestandsnaam als een deel ervan opgeven. Maar het mooiste van deze modus is dat je deze kunt instellen Extra opties zoekopdracht:- In de map- geeft aan waar naar bestanden moet worden gezocht. Als u dit veld leeg laat, doorzoekt het programma alle geïndexeerde schijven. Standaard worden alle logische vaste schijven geïndexeerd.
In het menu kunt u bekijken of wijzigen welke schijven geïndexeerd moeten worden Gereedschap | Opties... | Indexeren.
- Inhoudelijk- hiermee kunt u opgeven welke tekst in bestanden moet worden gezocht. Dit is de meest interessante functie van het programma, waarmee je kunt zoeken specifieke tekst in bestanden. De onderstaande schermafbeelding laat dus zien hoe u snel alle tekstbestanden op station C kunt vinden die een fout vermelden (het woord fout is aanwezig).
- Datum van wijziging- in deze sectie kunt u bestanden filteren op datum laatste wijziging. Als u dit vakje aanvinkt, moet u het datumbereik invoeren waarin u wilt zoeken.
- Maat- hiermee kunt u bestanden op grootte filteren. U moet ook het groottebereik opgeven waarin u wilt zoeken en de maateenheden selecteren (KB, MB, GB)

Expressietypen
In de directe zoekmodus worden expressietypen geconfigureerd in het menu Zoeken | Expressietype. In de geavanceerde modus in de sectie Bestandsnaam er verschijnt een extra veld wanneer u het vakje aanvinkt Extra opties.
Afhankelijk van de instellingen wordt de tekst in het veld ingevoerd Bestandsnaam kan worden geïnterpreteerd als een woord, een deel van een naam (subtekenreeks) of reguliere expressie.
Subtekenreeks
Dit is de eenvoudigste modus en wordt standaard geïnstalleerd. In deze modus is het voldoende om een deel van de bestandsnaam in te voeren. Deze modus is vooral handig in gevallen waarin de volledige naam van het bestand onbekend is, of als iemand het is vergeten, maar zich herinnert dat het een tekstbestand is. Voer in dit geval gewoon .txt in de regel in.Volledig woord
In deze modus kan het woord dat in de zoekbalk is ingevoerd, verschijnen in de bestands- of inhoudsnaam in het formulier een woord, maar kan geen deel uitmaken van een ander woord.Het woord 'notitie' komt bijvoorbeeld overeen met het bestand 'note.txt', 'mijn notitie.txt', maar komt niet overeen met het bestand '1note.txt' of 'notebook.txt'
Reguliere expressie
In deze modus wordt de zoekreeks geïnterpreteerd als een reguliere expressie die compatibel is met de programmeertaal Perl. Reguliere expressies zijn op zichzelf een heel belangrijk onderwerp. Als u er niet bekend mee bent, gebruik deze modus dan gewoon niet.Met de hulp van dit kleine gratis programma Binnen enkele seconden kunt u niet alleen elke tekst op uw computer vinden, maar ook elk bestand, zelfs het kleinste, dat verloren is gegaan tussen terabytes aan andere gegevens.
Een programma voor het zoeken naar tekst in bestanden op een computer.Met dit programma kun je snel teksten vinden in documenten, tekstbestanden, opgeslagen webpagina's, mp3-tags, zelfs afbeeldingen, alle soorten archieven en bestanden. Er is ondersteuning voor alle Russische coderingen. Het programma heeft een handig duidelijke interface en niet minder luxueuze functionaliteit. Maar belangrijkste kenmerk Het programma zoekt op hoge snelheid naar teksten in bestanden. Binnen enkele seconden scant het programma gigabytes aan informatie. Voor nog meer productiviteit zijn er speciale filters voorzien, bijvoorbeeld: zoek naar afbeeldingen met een grootte van minimaal 120 x 120 pixels, zoek in mp3-tags met een muziekduur van minimaal 20 seconden. Het programma begrijpt alle soorten documenten en bestanden en kan met archieven werken. Het doorzoekt zowel de bestanden zelf als het programma zoekt ook naar tekst in bestanden.
Een universeel programma voor het zoeken naar tekst in bestanden voor beginners en professionals.
Copernic Desktop Search
Vanaf de eerste kennismaking met het programma Copernic Desktop Search kon ik niet anders dan dat
je merkt een prettige interface die alleen maar positief oproept
emoties, wat zeldzaam is voor dit soort programma's. Alle
tools die het programma heeft voor het zoeken naar tekst in bestanden en
De functiebedieningen zijn ergonomisch op de panelen geplaatst.
Het belangrijkste kenmerk van deze ontwikkeling is dat
een programma voor het zoeken naar tekst in bestanden heeft een leuke
ontwerp en niets extra's, alles voor handig werk Met
programma. Vanaf de eerste keer opstarten zal de wizard u vragen speciale indexen te maken
razendsnel tekst zoeken in bestanden. Na stilstand
computer, begint het programma automatisch met het indexeren van de geselecteerde mappen.
Maar dit kan op verzoek van de gebruiker in de instellingen worden gewijzigd.
De instellingen in het programma zijn behoorlijk breed. Alleen indexeren is mogelijk
configureren binnen automatische modus, in ingebouwde plannermodus,
in handmatige modus, terwijl de computer inactief is, op de achtergrond met laag
prioriteit van het verbruik van hulpbronnen. De indexstructuur bevat instellingen:
selectie op bestandstype, in algemene en gedetailleerde vorm. Jij
filter wat u gaat indexeren, documenten, gewoon
tekstbestanden, html-pagina's, afbeeldingen, video's, muziek en andere typen
bestanden. Er zijn instellingen voor het selecteren van bestanden op extensie. Breed
Met indexeringsinstellingen kunt u indexen op specifiek filteren
gebruikers vereisten. Het indexeren van afbeeldingen van formaat is dat bijvoorbeeld niet
minder dan 100 x 100 pixels of muziek met een duur van minimaal 15
seconden U vindt er ook indexeringsinstellingen voor e-mailclients,
tekst zoeken in e-mail en andere programma's zoals Microsoft Outlook.
Ook bij het zoeken naar tekst in bestanden onderscheidt het programma zich van zijn concurrenten.
U kunt bijvoorbeeld uitsluitend tekst in mp3-bestanden zoeken
alleen op tags in bepaalde categorieën, artiest, album,
titel van de compositie, datum. U kunt alleen naar een afbeelding zoeken in
specifieke formaten, extensies en resoluties. Praktisch
Elk bestandstype heeft zijn eigen instellingen. Hierdoor kunt u zoeken
tekst in bestanden razendsnel. Na het zoeken wordt het programma weergegeven
informatieve resultaten van een zoekopdracht met een venster
voorbeeld van de bestandstekst en een voorbeeldvenster van de locatie waar
De verzoektekst verschijnt in de bestanden. Uitstekend en vooral snel
programma voor het zoeken naar tekst in bestanden. Het is geschikt voor thuisgebruik
gebruiken en in professioneel werk met veel
documenten en bestanden. Het programma laat uitstekende resultaten zien
in de snelheid van het zoeken naar tekst in tientallen gigabytes aan documentbestanden en
andere soorten informatie.
Professioneel programma voor het zoeken naar tekst in bestanden.

Een interessant programma voor het zoeken naar teksten in bestanden met eigen bestanden
voordelen. Kenmerken van het programma omvatten ondersteuning voor verschillende
coderingen zoals Unicode en UTF voor het zoeken naar tekst in bestanden. Programma
voert zoekopdrachten uit zowel op de lokale computer als op FTP-servers.
Kan niet alleen tekst vinden, maar deze ook vervangen in batchmodus
vond tegelijkertijd tekst naar een andere in honderden bestanden. Programma
heeft een ingebouwde editor die enorm helpt
voorbeeld bij het automatisch vervangen van gevonden tekst.
De ingebouwde editor heeft syntaxisaccentuering van de broncode.
Het belangrijkste kenmerk dat het heeft programma voor
zoek tekst in bestanden met syntaxisondersteuning normale uitdrukkingen
syntaxis voor het zoeken en vervangen van tekst in bestanden.
Het programma heeft ook veel filterinstellingen
zoekopdracht. Met het programma kunt u zoekresultaten in een apart bestand opslaan
bestand. Het programma kan dubbele mapnamen herkennen. Over het algemeen
Het programma is ontworpen voor gevorderde gebruikers en meestal ook
gekozen door webmasters. Specifieke functies die het programma benadrukken
concurrenten in de sector maken het aantrekkelijk voor ontwikkelaars. Maar ook
de gemiddelde gebruiker kan basisfuncties gebruiken
kan goed overweg met de basistaken van het snel zoeken naar tekst
bestanden.
SearchInform-bureaublad 
Vanaf de eerste kennismaking met het programma lijkt de interface misschien ingewikkeld,
maar dan merk je dat alles op zijn plaats zit. Er moet eerst gewerkt worden
maak een zoekindex. Dit is een vrij eenvoudig proces. Speciaal
Ik wil opmerken hoge snelheid indexeringsproblemen
programma voor het zoeken naar tekst in bestanden. Bij het indexeren
het programma voegt toe aan de index als
gewone mappen en bestanden, en e-mails en andere externe
bronnen (DMS, CRM). Een bijzonder kenmerk van het zoeken naar programma's is het zoeken op
exacte zoekopdracht of met ondersteuning voor synoniemen. Dit type zoekopdracht wordt benadrukt
programma onder concurrenten. Zoekparameters kunnen worden aangepast
verschillende vormen van verzoeken. Bijvoorbeeld: zoeken op zinsdelen, morfologisch
zoeken, zoeken op citaten, logische bewerkingen, zoeken op begin van woord, op
eindigend, in het middelste deel van woorden. Offerteaanvraagformulier beschikbaar
zoekopdracht. Wanneer alle woorden van een citaat aanwezig moeten zijn in bestanden in
verschillende volgorde, en tussen woorden kunnen al dan niet aanwezig zijn
(op verzoek van de gebruiker) andere woorden. Het programma bevat
ingebouwde woordenboeken van belangrijke en niet-significante woorden. belangrijkste kenmerk
dit programma is nieuwe technologie bij tekstanalyse. Systeem
zoekt nauwkeurig op semantische inhoud. Het programma kan erin werken
bedrijfsnetwerk. Bij het zoeken op een lokaal netwerk heeft het programma
twee modules zijn server en client. De verschillen zijn dat
de clientmodule heeft beperkingen op de toegangsrechten om te zoeken
informatie. Hierdoor zien we dat dit een professioneel programma is,
die is ontworpen voor een breed scala aan gebruikers. Wat betreft
zakelijk en thuisgebruik.
Een programma voor het zoeken naar tekst in bestanden voor gewone gebruikers.

Een compact programma voor het nauwkeurig zoeken naar teksten in
bestanden en documenten. Werkt op alle populaire pc-platforms
(Windows, Mac OS X en Linux). Het programma ondersteunt de functie ook
indexeren van mappen en bestanden. De eerste indexering is, zoals altijd, een beetje
langer dan de volgende die alleen worden bijgewerkt afhankelijk van
het bijwerken van de mapinhoud. Maar de aanwezigheid van indexering maakt dit mogelijk
snel zoekprogramma. Het programma is, ondanks zijn bescheidenheid,
heeft beide basisquerypatronen "AND", "OR" en "NOT", en
geavanceerd: vervangingspatroon, onnauwkeurig zoeken, zoeken op zinsdelen. IN
het programma biedt ondersteuning voor Unicode in documenten, webpagina's en
gewone tekstbestanden. Het programma kan in archieven zoeken
(zip, rar, 7z en andere). Programma voor het zoeken naar tekst in
bestanden ondersteunt alles kantoordocumenten , En
helpbestanden, web
pagina's, tekstbestanden en daarnaast bestanden in AbiWord-formaat,
Schaalbare vectorafbeeldingen, Microsoft Visio en andere populaire formaten.
Het programma heeft een smalle zoekspecialisatie en is daardoor gemakkelijk te gebruiken.
Deze versie is draagbaar en kan draaien op Windows, Mac OS X en
Linux. Heeft een Russische interface.
AVZoeken 
Ook een compact programma voor het zoeken naar teksten in bestanden.
Een speciaal kenmerk van het programma is ondersteuning voor alle 5 Russische coderingen,
plus Unicode. Zoeken in archieven is zeer goed geïmplementeerd. thuis
het bijzondere is dat programma om tekst in te zoeken
archiefbestanden ondersteunen meer dan 20 formaten.
Er zijn basisquerysjablonen,
constructies (AND, OR, NOT) en zoeken op “masker” van woorden
in zoektermen. Het programma beschikt over uitgebreide instellingen
bestandsfiltering. U kunt de zoekresultaten bekijken in
tekstvorm of als HEX-tabel. Het programma vereist niet
installaties. Heeft een Russische interface. Zeer effectief bij het zoeken
archieven.
Testresultaat is het beste programma voor het zoeken naar tekst in bestanden.
Elk programma heeft zijn eigen kenmerken voor het zoeken naar teksten. Kiezen
geschikt programma voor specifieke taken en arbeidsomstandigheden. Gebruik makend van
Met elk van deze programma's kunt u aanzienlijk effectiever en efficiënter werken
Het is productiever en sneller om bestanden te zoeken, sorteren en ordenen. Maar ook
Wat heel belangrijk is, is dat je razendsnel teksten en bestanden kunt vinden. Gegevens
de tools zullen veel nuttiger voor je zijn vergeleken met de ingebouwde tools
hulpmiddelen voor het zoeken naar bestanden en teksten in besturingssystemen.
Programma's bestandsbeheerders ze kunnen ook niet vergelijken qua snelheid en
zoekresultaten met deze programma's. Het is moeilijk om er maar één uit te pikken
het beste programma van iedereen die aan de test heeft deelgenomen. Alle programma's
hebben hun eigen kenmerken die hen onderscheiden van hun concurrenten.
Maar ik raad aan om uw kennismaking met dit soort programma's te beginnen met Copernic
Desktop Search, ten eerste is dit hulpprogramma mooi, handig en
duidelijke interface. Een beginner kan meteen aan de slag. Behalve
Bovendien zal de overvloed en kwaliteit van de functies hoogstwaarschijnlijk al uw wensen bevredigen
nodig heeft bij het zoeken naar teksten en bestanden en u mag niet zoeken
iets anders. Het hulpprogramma is een soort compromis tussen eenvoudig
aangepaste en complexe professionele programma's. Maar als jij
je hebt echt een compromisloze, zeer snelle zoekactie nodig en je bent er klaar voor
besteed wat tijd aan het begrijpen van de functies van het programma
dan is het beter om meer te gebruiken professioneel programma ZoekInform
Desktop zonder zoeksnelheid en aantal functies
gelijk aan. Het zoeken wordt in seconden voltooid in mappen groter dan
gigabyte. Bovendien helpt de intelligentie van het programma zo nauwkeurig mogelijk te zijn
vind wat u zoekt. Dit is echt indrukwekkend. Alle programma's die u
Je kunt het hieronder downloaden in één archief. Al deze programma's hebben al sleutels, en
je kunt meteen aan de slag. Zoek informatie over uw
computer snel en comfortabel.
De taak van het doorzoeken van de inhoud van bestanden is in principe niet nieuw: van tijd tot tijd moet ik in meerdere bestanden naar teksten of stukjes code zoeken. Het is gemakkelijker voor degenen die Linux gebruiken en begrijpen, omdat... er is een speciale grep-functie voor deze oplossing. Onder 7 kwam ik enkele artikelen tegen over het uitbreiden van de mogelijkheden van basiszoeken door de inhoud van bestanden te indexeren, maar ik besloot toch een geschikt programma te vinden. Hoewel ik in principe alles handmatig deed, ervan uitgaande dat het leren van de juiste software meer tijd zou kosten.

U kunt WinGrep geheel gratis downloaden, het neemt slechts 730Kb in beslag. Bijna alles wordt ondersteund Windows-versies: 98, 2000, XP, Vista en Windows 7. Van dat laatste weet ik helaas niets, want Ik heb een "zeven".
Het proces van het zoeken naar tekst in bestanden
Laten we het proces van het zoeken naar tekst in bestanden eens nader bekijken. Onmiddellijk na het starten van WinGrep verschijnt er een assistentvenster dat ons probleem in een paar stappen zal helpen oplossen.

Bij de eerste stap moet u bepalen naar welke tekst u gaat zoeken en het zoektype specificeren: reguliere expressies gebruiken, snel, vergelijkbaar met uw woordgroep. U kunt ook de opties aanvinken om rekening te houden met hoofdlettergebruik of alleen op het hele woord te zoeken.

U kunt er meerdere tegelijk markeren + een zoekopdracht naar de inhoud van bestanden in submappen activeren. De interface is natuurlijk niet de modernste :)
Geef bij de volgende stap de bestandsextensies op die moeten worden verwerkt.

Om uw werk te versnellen, kunt u alleen bepaalde typen bestanden markeren die u nodig heeft. Als u alles in de lijst wilt opnemen, selecteert u de universele waarde “*.*”. U kunt uw eigen extensies toevoegen.

Hier ziet u enkele statistieken over het uitgevoerde werk. De pictogramwerkbalk omvat het opnieuw uitvoeren van de procedure, het vervangen van tekst in bestanden, opslaan en andere opties.
Als u zichzelf als een gevorderde gebruiker beschouwt en bekend bent met de Grep-opdracht, kunt u de Expertmodus inschakelen in het menu Opties. Hierna zal het dialoogvenster met zoekinstellingen er enigszins anders uitzien.

Bovendien zal het er meerdere bevatten toegevoegde opties. Beginners moeten dit niet doen, en als ze dat wel doen, kun je terugschakelen via hetzelfde menu-item Opties.
Kenmerken van het WinGrep-bestandszoekprogramma
Naast het implementeren van de grep-functie in Windows-programma voor het zoeken naar tekst in bestanden heeft de volgende kenmerken:
- Beschikbaar voor zowel beginners als gevorderde gebruikers. De eerste werken met een stapsgewijze assistent, terwijl de laatste een uitgebreide Expert-modus hebben.
- Ondersteuning voor eenvoudig tekstbestanden(inclusief UNIX-stijl): programmabronnen, HTML, RTF, batchbestanden, enz.
- Werkt met binaire bestanden zoals Word-documenten, spreadsheets, databases, DLL's en zelfs EXE-bestanden.
- Tekst vervangen. Direct nadat je overeenkomsten hebt gevonden, kun je deze vervangen door een andere tekst reeks(in één of alle bestanden tegelijk). Snel en veilig.
- Zoekresultaten opslaan en afdrukken op basis van de bestandsinhoud.
- De opdrachtregelinterface kan worden gebruikt.
- U kunt uw zoekcriteria opslaan voor later gebruik.
- Multitasking wordt ondersteund, u kunt de applicatie naar de lade minimaliseren.
- Verwerken van ZIP-archieven.
- Dankzij de integratie van WinGrep in Windows Verkenner kunt u het hulpprogramma starten via het contextmenu vanuit elke map.
- Makkelijke installatie.
Over het algemeen is WinGrep een geweldige oplossing! Zoals ik hierboven al zei, kun je in Windows 7 zoeken naar de inhoud van bestanden vanuit de reguliere zoekfunctie, maar werken met het programma is veel eenvoudiger. Het installeren en begrijpen van de interface duurt slechts een paar minuten. Gratis verspreid, zoekopdrachten zijn snel genoeg. Nu zal ik het alleen gebruiken om naar tekst in bestanden te zoeken. Het enige dat niet duidelijk is, is hoe de software functioneert laatste versie Ramen. Misschien heeft iemand het al geprobeerd? - schrijf in de reacties.



