The Hitchhiker's Guide voor machinaal leren in Python. Inleiding tot Machine Learning met Python en Scikit-Learn
Cheatsheets zullen je geest bevrijden voor meer belangrijke taken. We hebben 27 van de beste spiekbriefjes verzameld die u kunt en moet gebruiken.
Ja, machine learning ontwikkelt zich met sprongen en ik denk dat mijn verzameling verouderd zal raken, maar voor juni 2017 is het meer dan relevant.
Als je niet alle spiekbriefjes afzonderlijk wilt downloaden, download dan het kant-en-klare zip-archief.
Machinaal leren
Er zijn nogal wat nuttige stroomdiagrammen en tabellen die betrekking hebben op machine learning. Hieronder staan de meest complete en noodzakelijke.
Neurale netwerkarchitecturen
Met de komst van nieuwe neurale netwerkarchitecturen zijn ze moeilijk te volgen geworden. Het grote aantal acroniemen (BiLSTM, DCGAN, DCIGN, kent iemand ze allemaal?) kan ontmoedigend zijn.
Dus besloot ik een spiekbriefje samen te stellen met veel van deze architecturen. Meest verwijst naar neurale netwerken. Er is alleen één probleem met deze visualisatie: het gebruiksprincipe wordt niet getoond. Variationele auto-encoders (VAE) kunnen er bijvoorbeeld uitzien als auto-encoders (AE), maar het leerproces is anders.
Stroomdiagram van Microsoft Azure-algoritme
Microsoft Azure machine learning spiekbriefjes om u te helpen kiezen juiste algoritme voor een voorspellend analysemodel. Machinestudio Microsoft-opleiding Azure bevat een grote bibliotheek met algoritmen voor regressie, classificatie, clustering en afwijkingsdetectie.

SAS-algoritmestroomdiagram
Met spiekbriefjes met SAS-algoritmen kunt u snel het juiste algoritme vinden om op te lossen specifieke taak. De hier gepresenteerde algoritmen zijn het resultaat van een compilatie van feedback en advies van verschillende datawetenschappers, ontwikkelaars en experts op het gebied van machine learning.

Verzameling van algoritmen
Regressie, regularisatie, clustering, beslissingsboom, Bayesiaanse en andere algoritmen worden hier gepresenteerd. Ze zijn allemaal gegroepeerd volgens operationele principes.

Ook de lijst in infographic formaat:

Voorspellingsalgoritme: “voor/tegen”
Deze spiekbriefjes hebben de beste algoritmen verzameld die worden gebruikt bij voorspellende analyses. Prognoses zijn een proces waarbij de waarde van een uitvoervariabele wordt bepaald op basis van een reeks invoervariabelen.

Python
Het is niet verrassend dat de Python-taal een grote gemeenschap en veel online bronnen heeft verzameld. Voor deze sectie heb ik de beste spiekbriefjes geselecteerd waarmee ik heb gewerkt.
Dit is een verzameling van de 10 meest gebruikte machine learning-algoritmen met codes in Python en R. Het spiekbriefje is geschikt als naslagwerk om u te helpen nuttige machine learning-algoritmen te gebruiken.

Het valt niet te ontkennen dat Python vandaag de dag in opkomst is. De spiekbriefjes bevatten alles wat je nodig hebt, inclusief functies en de definitie van objectgeoriënteerd programmeren met de Python-taal als voorbeeld.

En dit spiekbriefje zal een geweldige aanvulling zijn op het inleidende deel van elke Python-tutorial:

NumPy
NumPy is een bibliotheek waarmee Python gegevens snel kan verwerken. Wanneer je voor het eerst studeert, heb je misschien problemen met het onthouden van alle functies en methoden, dus hier hebben we de handigste spiekbriefjes verzameld die het bestuderen van de bibliotheek enorm kunnen vergemakkelijken. Importeren/exporteren, arrays maken, kopiëren, sorteren, elementen verplaatsen en nog veel meer komen aan bod.

En hier wordt bovendien het theoretische deel gepresenteerd:

Een schematische weergave van enkele gegevens is te vinden in dit spiekbriefje:

Alle noodzakelijke informatie met diagrammen:

Pandas is een bibliotheek op hoog niveau, ontworpen voor data-analyse. De bijbehorende frames, panelen, objecten, pakketfunctionaliteit en andere noodzakelijke informatie worden verzameld in een handig georganiseerd spiekbriefje:

Een schematische weergave van informatie over de Panda's-bibliotheek:

En dit spiekbriefje bevatte een gedetailleerde presentatie met voorbeelden en tabellen:

Als u de vorige Pandas-bibliotheek aanvult met het matplotlib-pakket, kunt u grafieken tekenen voor de ontvangen gegevens. Matplotlib is verantwoordelijk voor het plotten van grafieken in Python. Dit is vaak het eerste pakket met betrekking tot visualisatie dat beginnende Python-programmeurs gebruiken, en de gepresenteerde spiekbriefjes helpen je snel door de functionaliteit van deze bibliotheek te navigeren.

In het tweede spiekbriefje vind je meer voorbeelden visuele representatie grafieken:

De Scikit-Learn Python-bibliotheek met machine learning-algoritmen is niet de gemakkelijkste om te leren, maar met spiekbriefjes wordt het principe van de werking ervan zo duidelijk mogelijk.

Schematische weergave:

Met theorie, voorbeelden en aanvullende materialen:

TensorFlow
Nog een bibliotheek voor machinaal leren, maar met zijn eigen functionaliteit en moeilijkheden bij het begrijpen ervan. Hieronder vindt u een handig spiekbriefje voor het leren van TensorFlow.
Hallo, habr!
Importeer numpy als np import urllib # url met dataset url = "http://archive.ics.uci.edu/ml/machine-learning-databases/pima-indians-diabetes/pima-indians-diabetes.data" # download de file raw_data = urllib.urlopen(url) # laad het CSV-bestand als een numpy matrix dataset = np.loadtxt(raw_data, delimiter=",") # scheid de data van de doelattributen X = dataset[:,0:7] y = gegevensset[:,8]
Verder zullen we in alle voorbeelden met deze dataset werken, namelijk met de object-attribuutmatrix X en waarden van de doelvariabele j.
Gegevensnormalisatie
Iedereen is zich er terdege van bewust dat de meeste gradiëntmethoden (waarop vrijwel alle machine learning-algoritmen in essentie zijn gebaseerd) zeer gevoelig zijn voor dataschaling. Daarom wordt dit meestal ook gedaan voordat algoritmen worden uitgevoerd normalisatie, of de zogenaamde standaardisatie. Normalisatie omvat het vervangen van nominale kenmerken, zodat elk ervan in het bereik van 0 tot 1 ligt. Standaardisatie impliceert een dergelijke voorverwerking van gegevens, waarna elk kenmerk een gemiddelde van 0 en een variantie van 1 heeft. Scikit-Learn heeft hiervoor al functies klaar:Van sklearn import preprocessing # normaliseer de gegevensattributen normalized_X = preprocessing.normalize(X) # standaardiseer de gegevensattributen standardized_X = preprocessing.scale(X)
Functieselectie
Het is geen geheim dat het vermogen om functies correct te selecteren en zelfs te creëren vaak het belangrijkste is bij het oplossen van een probleem. In de Engelse literatuur heet dit Functieselectie En Functietechniek. Hoewel Future Engineering een behoorlijk creatief proces is en meer afhankelijk is van intuïtie en vakkennis, is dat bij Feature Selection al het geval groot aantal kant-en-klare algoritmen. “Boom”-algoritmen maken het mogelijk de informatie-inhoud van kenmerken te berekenen:Van sklearn importstatistieken van sklearn.ensemble import ExtraTreesClassifier model = ExtraTreesClassifier() model.fit(X, y) # toon het relatieve belang van elk attribuut print(model.feature_importances_)
Alle andere methoden zijn op een of andere manier gebaseerd op een efficiënte opsomming van subsets van kenmerken om de beste subset te vinden waarop het geconstrueerde model de beste kwaliteit geeft. Een voorbeeld van zo'n brute force-algoritme is het Recursive Feature Elimination-algoritme, dat ook beschikbaar is in de Scikit-Learn-bibliotheek:
Van sklearn.feature_selection importeer RFE van sklearn.linear_model import LogisticRegression model = LogisticRegression() # maak het RFE-model en selecteer 3 attributen rfe = RFE(model, 3) rfe = rfe.fit(X, y) # vat de selectie van de attributen samen print(rfe.support_) print(rfe.ranking_)
Constructie van het algoritme
Zoals reeds opgemerkt, implementeert Scikit-Learn alle belangrijke machine learning-algoritmen. Laten we er een paar bekijken.Logistieke regressie
Het wordt meestal gebruikt om classificatieproblemen op te lossen (binair), maar classificatie in meerdere klassen is ook toegestaan (de zogenaamde one-vs-all-methode). Het voordeel van dit algoritme is dat we bij de uitvoer van elk object de kans hebben om tot de klasse te behorenImporteer statistieken van sklearn uit sklearn.linear_model import LogisticRegression model = LogisticRegression() model.fit(X, y) print(model) # maak voorspellingen verwacht = y voorspeld = model.predict(X) # vat de pasvorm van het model samen print( metrics.classification_report(verwacht, voorspeld)) print(metrics.confusion_matrix(verwacht, voorspeld))
Naïeve Bayes
Het is ook een van de bekendste machine learning-algoritmen, waarvan de belangrijkste taak het herstellen van de distributiedichtheid van de trainingsvoorbeeldgegevens is. Vaak geeft deze methode goede kwaliteit bij classificatieproblemen met meerdere klassen.Importeer metrische gegevens van sklearn van sklearn.naive_bayes import GaussianNB model = GaussianNB() model.fit(X, y) print(model) # maak voorspellingen verwacht = y voorspeld = model.predict(X) # vat de pasvorm van het model samen print( metrics.classification_report(verwacht, voorspeld)) print(metrics.confusion_matrix(verwacht, voorspeld))
K-dichtstbijzijnde buren
Methode kNN (k-dichtstbijzijnde buren) vaak gebruikt als bestanddeel complexer classificatie-algoritme. De beoordeling ervan kan bijvoorbeeld worden gebruikt als teken voor een object. En soms geeft een simpele kNN over goedgekozen functies uitstekende kwaliteit. Bij juiste configuratie parameters (voornamelijk metrieken), geeft het algoritme vaak goede kwaliteit bij regressieproblemenVan sklearn importstatistieken van sklearn.neighbors import KNeighborsClassifier # pas een k-dichtstbijzijnde buurmodel aan het gegevensmodel aan = KNeighborsClassifier() model.fit(X, y) print(model) # maak voorspellingen verwacht = y voorspeld = model.predict( X) # vat de pasvorm van het model samen print(metrics.classification_report(expected, voorspeld)) print(metrics.confusion_matrix(expected, voorspeld))
Beslisbomen
Classificatie- en regressiebomen (CART) vaak gebruikt bij problemen waarbij objecten categorische kenmerken hebben en wordt gebruikt voor regressie- en classificatieproblemen. Bomen zijn zeer geschikt voor classificatie in meerdere klassenImporteer metrische gegevens van sklearn van sklearn.tree import DecisionTreeClassifier # pas een CART-model aan het gegevensmodel aan = DecisionTreeClassifier() model.fit(X, y) print(model) # maak voorspellingen verwacht = y voorspeld = model.predict(X) # vat de pasvorm van het model samen print(metrics.classification_report(verwacht, voorspeld)) print(metrics.confusion_matrix(verwacht, voorspeld))
Ondersteuning van vectormachine
SVM (ondersteuningsvectormachines) is een van de bekendste machine learning-algoritmen, voornamelijk gebruikt voor classificatietaken. Net als logistische regressie maakt SVM classificatie in meerdere klassen mogelijk met behulp van de één-vs-alles-methode.Van sklearn importstatistieken uit sklearn.svm import SVC # pas een SVM-model aan het gegevensmodel aan = SVC() model.fit(X, y) print(model) # maak voorspellingen verwacht = y voorspeld = model.predict(X) # vat de pasvorm van het model samen print(metrics.classification_report(verwacht, voorspeld)) print(metrics.confusion_matrix(verwacht, voorspeld))
Naast classificatie- en regressie-algoritmen heeft Scikit-Learn enorme hoeveelheid complexere algoritmen, inclusief clustering, evenals geïmplementeerde technieken voor het construeren van composities van algoritmen, inclusief Opzakken En Stimuleren.
Optimalisatie van algoritmeparameters
Een van de moeilijkste stappen bij het bouwen van echt effectieve algoritmen is kiezen juiste parameters. Meestal wordt dit gemakkelijker met ervaring, maar op de een of andere manier moet je overboord gaan. Gelukkig heeft Scikit-Learn al een flink aantal functies voor dit doel geïmplementeerd.Laten we bijvoorbeeld eens kijken naar de selectie van een regularisatieparameter, waarbij we om beurten verschillende waarden uitproberen:
Importeer numpy als np uit sklearn.linear_model import Ridge uit sklearn.grid_search importeer GridSearchCV # bereid een reeks alfawaarden voor om alphas te testen = np.array() # maak en pas een ridge-regressiemodel aan, waarbij elk alfamodel wordt getest = Ridge( ) grid = GridSearchCV(estimator=model, param_grid=dict(alpha=alphas)) grid.fit(X, y) print(grid) # vat de resultaten van de rasterzoekopdracht samen print(grid.best_score_) print(grid.best_estimator_. alfa)
Soms blijkt het effectiever om meerdere keren willekeurig een parameter uit een bepaald segment te selecteren en de kwaliteit van het algoritme te meten. deze parameter en kies dus de beste:
Importeer numpy als np uit scipy.stats importeer uniform als sp_rand uit sklearn.linear_model importeer Ridge uit sklearn.grid_search importeer RandomizedSearchCV # bereid een uniforme verdeling voor om te bemonsteren voor de alpha-parameter param_grid = ("alpha": sp_rand()) # create and fit een ridge regressiemodel, waarbij willekeurige alfawaarden worden getest model = Ridge() rsearch = RandomizedSearchCV(estimator=model, param_distributions=param_grid, n_iter=100) rsearch.fit(X, y) print(rsearch) # vat de resultaten samen van de zoeken naar willekeurige parameters print(rsearch.best_score_) print(rsearch.best_estimator_.alpha)
We hebben het hele proces van het werken met de Scikit-Learn-bibliotheek bekeken, met uitzondering van het terugsturen van de resultaten naar een bestand, dat als oefening aan de lezer wordt aangeboden, omdat een van de voordelen van Python (en de Scikit- Leerbibliotheek zelf) vergeleken met R is de uitstekende documentatie. In de volgende delen zullen we elk van de secties in detail bekijken, in het bijzonder zullen we iets belangrijks bespreken als Schoonheidstechniek.
Dat hoop ik echt dit materiaal zal beginnende datawetenschappers helpen om zo snel mogelijk machine learning-problemen in de praktijk op te lossen. Tot slot wil ik succes en geduld wensen aan degenen die net beginnen deel te nemen aan machine learning-wedstrijden!
Elke data-analyse-expert vraagt zich af welke programmeertaal hij moet kiezen. — R of Python, schrijven ze? Om het beste antwoord op deze vraag te vinden, wordt in de meeste gevallen het populairste antwoord gebruikt Google-zoekmachine. Zonder de juiste antwoorden worden potentiële kandidaten nooit experts op het gebied van machine learning of data-analyse. Dit artikel probeert de specifieke kenmerken van de R- en Python-talen uit te leggen voor hun gebruik bij de ontwikkeling van machine learning-technologieën.
Machine learning en datawetenschap zijn bloeiende en steeds groeiende segmenten van de hedendaagse geavanceerde technologieën die helpen bij het oplossen van verschillende complexe problemen en uitdagingen bij de ontwikkeling van oplossingen en toepassingen. In dit opzicht worden analisten en experts op het gebied van data-analyse op wereldschaal geconfronteerd met de breedste mogelijkheden om hun sterke punten en capaciteiten te benutten in technologieën zoals kunstmatige intelligentie, IoT en big data. Nieuw op te lossen complexe taken experts en specialisten nodig hebben krachtig hulpmiddel het verwerken van enorme hoeveelheden gegevens, en er is een verscheidenheid aan machine learning-tools en bibliotheken ontwikkeld om taken op het gebied van gegevensanalyse, herkenning en aggregatie te automatiseren.
Bij de ontwikkeling van machine learning-bibliotheken nemen programmeertalen als R en Python leidende posities in. Veel experts en analisten besteden tijd aan het kiezen vereiste taal. Welke programmeertaal heeft meer de voorkeur voor machine learning-doeleinden?
Wat zijn de overeenkomsten tussen R en Python
- Beide talen — R en Python — zijn open source programmeertalen broncode. Een groot aantal leden van de programmeergemeenschap heeft bijgedragen aan de ontwikkeling van documentatie en de ontwikkeling van deze talen.
- De talen kunnen worden gebruikt voor data-analyse, analytics en machine learning-projecten.
- Beiden beschikken over geavanceerde tools voor het voltooien van data science-projecten.
- Experts op het gebied van data-analyse die liever in R en Python werken, krijgen vrijwel hetzelfde betaald.
- Huidige versies van Python en R — x.x
R en Python – concurrentie tussen concurrenten
Historische excursie:
- In 1991 stelde Guido Van Rossum, geïnspireerd door de ontwikkelingen van de talen C, Modula-3 en ABC, voor nieuwe taal programmeren - Python.
- In 1995 creëerden Ross Ihaka en Robert Gentleman de R-taal, die werd ontwikkeld naar analogie met de S-programmeertaal.
Doelen:
- Het doel van Python-ontwikkeling is creëren softwareproducten, waardoor het ontwikkelingsproces wordt vereenvoudigd en de leesbaarheid van de code wordt gewaarborgd.
- Terwijl de R-taal vooral is ontwikkeld voor gebruiksvriendelijke data-analyse en voor het oplossen van complexe statistische problemen. Het is een voornamelijk statistisch georiënteerde taal.
Gemakkelijk te leren:
- Dankzij de leesbaarheid van de code is Python gemakkelijk te leren. Het is een beginnersvriendelijke taal die kan worden geleerd zonder voorafgaande programmeerervaring.
- De R-taal is moeilijk, maar hoe langer je deze taal gebruikt bij het programmeren, hoe gemakkelijker het is om te leren en hoe hoger je effectiviteit bij het oplossen van complexe statistische formules. Voor ervaren programmeurs is R een optie ga naar.
Gemeenschappen:
- Python heeft de steun van verschillende gemeenschappen waarvan de leden zich inzetten voor de ontwikkeling van de taal voor veelbelovende toepassingen. Programmeurs en ontwikkelaars zijn, net als StackOverflow-leden, actieve leden van de Python-gemeenschap.
- De R-taal wordt ook ondersteund door leden van een diverse gemeenschap via mailinglijsten, documentatie van gebruikersbijdragen en anderen. De meeste statistici, onderzoekers en experts op het gebied van data-analyse zijn actief betrokken bij de ontwikkeling van de taal.
Flexibiliteit:
- Python is een taal die de nadruk legt op productiviteit, dus het is vrij flexibel in ontwikkeling. diverse toepassingen. Voor het ontwikkelen van grootschalige toepassingen bevat Python verschillende modules en bibliotheken.
- De R-taal is ook flexibel bij het ontwikkelen van complexe formules, het uitvoeren van statistische tests, datavisualisatie en meer.
Sollicitatie:
- Python is toonaangevend op het gebied van applicatieontwikkeling. Het wordt gebruikt ter ondersteuning van website-ontwikkeling, game-ontwikkeling en datawetenschap.
- De R-taal wordt voornamelijk gebruikt om data-analyseprojecten te ontwikkelen die zich richten op statistiek en visualisatie.
Zowel R- als Python-talen hebben voor- en nadelen. In de meeste gevallen zijn dit specifiek gerichte talen, omdat R gericht is op statistiek en visualisatie, en Python gericht is op eenvoud bij het ontwikkelen van welke applicatie dan ook.
Op basis hiervan kan R vooral gebruikt worden voor onderzoek in wetenschappelijke instituten, bij het uitvoeren statistische analyses en datavisualisatie. Aan de andere kant wordt Python gebruikt om het proces van het verbeteren van programma's, het verwerken van gegevens, enz. te vereenvoudigen. De R-taal kan zeer productief zijn voor statistici die op het gebied van data-analyse werken, terwijl Python beter geschikt is voor programmeurs en ontwikkelaars die producten maken voor datawetenschappers.
Alexander Krot, een student aan FIVT MIPT, mijn goede vriend en, meer recentelijk, collega, lanceerde een reeks artikelen over praktische hulpmiddelen voor intelligente analyse van big data en machine learning (Datamining en machine learning).
Er zijn al 3 artikelen gepubliceerd, ik hoop dat er in de toekomst nog meer zullen volgen:
1) Inleiding tot machinaal leren met Python en Scikit-Learn
2) De kunst van feature-engineering in machinaal leren
3) Als er echt veel gegevens zijn: Vowpal Wabbit
De gepubliceerde artikelen richten zich op de praktische aspecten van het werken met tools voor automatische data-analyse en met algoritmen waarmee je data kunt voorbereiden voor effectieve machine-analyse. In het bijzonder worden voorbeelden van code in Python gegeven (we zijn trouwens onlangs begonnen Python te gebruiken) met de gespecialiseerde Scikit-Learn-bibliotheek, die snel kan worden gelanceerd op thuiscomputer of persoonlijke cloud om zelf te proeven van big data.
Onlangs dacht ik erover na hoe. Bekendheid met de bovenstaande tools zal ons nu in staat stellen praktische experimenten in deze richting uit te voeren (het Python-programma kan trouwens ook worden uitgevoerd op de Linux die in de controller is ingebouwd, maar hier zijn voorbeelden van het vermalen van gigabytes aan gegevens mobiele processor Het is onwaarschijnlijk dat dit werkt). En trouwens, Scala wordt ook gerespecteerd onder ingenieurs die met big data werken; het integreren van dergelijke code zal nog eenvoudiger zijn.
Traditioneel neemt het beheersen van welk hulpmiddel dan ook niet de noodzaak weg om een goed probleem te vinden dat met hun hulp effectief kan worden opgelost (tenzij iemand anders deze taak natuurlijk voor u oplegt). Maar het opent ruimte voor extra mogelijkheden. Naar mijn mening zou het er ongeveer zo uit kunnen zien: een robot (of een groep robots) verzamelt informatie van sensoren, stuurt deze naar een server, waar deze wordt verzameld en verwerkt om naar patronen te zoeken; Vervolgens vergelijkt het algoritme de gevonden patronen met de operationele waarden van de sensoren van de robot en stuurt het voorspellingen over het meest waarschijnlijke gedrag. omgeving. Of er wordt vooraf een kennisbank over het gebied of informatie op de server voorbereid. bepaald soort terrein (bijvoorbeeld in de vorm van karakteristieke foto's van het landschap en typische objecten), en de robot zal deze kennis kunnen gebruiken om gedrag in een operationele omgeving te plannen.
Ik steel het eerste artikel als inleiding, de rest van de links op Habré:
Importeer numpy als np import urllib # url met dataset-URL = "http://archive.ics.uci.edu/ml/machine-learning-databases/pima-indians-diabetes/pima-indians-diabetes.data"# download het bestand raw_data = urllib.urlopen(url) # laad het CSV-bestand als een numpy-matrix gegevensset = np.loadtxt(raw_data, delimiter="," ) # scheid de gegevens van de doelattributen X = gegevensset[:,0 :7 ] y = gegevensset[:,8 ]
Gegevensnormalisatie
Iedereen is zich er terdege van bewust dat de meeste gradiëntmethoden (waarop vrijwel alle machine learning-algoritmen in essentie zijn gebaseerd) zeer gevoelig zijn voor dataschaling. Daarom wordt dit meestal ook gedaan voordat algoritmen worden uitgevoerd normalisatie, of de zogenaamde standaardisatie. Normalisatie omvat het vervangen van nominale kenmerken, zodat elk ervan in het bereik van 0 tot 1 ligt. Standaardisatie impliceert een dergelijke voorverwerking van gegevens, waarna elk kenmerk een gemiddelde van 0 en een variantie van 1 heeft. Scikit-Learn heeft hiervoor al functies klaar:Van sklearn importvoorverwerking # normaliseer de data-attributen genormaliseerde_X = voorverwerking.normalize(X) # standaardiseer de data-attributen gestandaardiseerde_X = preprocessing.scale(X)
Functieselectie
Het is geen geheim dat het vermogen om functies correct te selecteren en zelfs te creëren vaak het belangrijkste is bij het oplossen van een probleem. In de Engelse literatuur heet dit Functieselectie En Functietechniek. Terwijl Future Engineering een behoorlijk creatief proces is en meer afhankelijk is van intuïtie en vakkennis, beschikt Feature Selection al over een groot aantal kant-en-klare algoritmen. “Boom”-algoritmen maken het mogelijk de informatie-inhoud van kenmerken te berekenen:Van sklearn importstatistieken van sklearn.ensemble import ExtraTreesClassifier model = ExtraTreesClassifier() model.fit(X, y) # geeft het relatieve belang van elk attribuut weer print(model.feature_importances_)
Alle andere methoden zijn op de een of andere manier gebaseerd op een efficiënte opsomming van subsets van kenmerken om de beste subset te vinden waarop het geconstrueerde model de beste kwaliteit geeft. Een voorbeeld van zo'n brute force-algoritme is het Recursive Feature Elimination-algoritme, dat ook beschikbaar is in de Scikit-Learn-bibliotheek:
Van sklearn.feature_selection import RFE van sklearn.linear_model import LogisticRegression model = LogisticRegression() # maak het RFE-model en selecteer 3 attributen rfe = RFE(model, 3 ) rfe = rfe.fit(X, y) # vat de selectie van de attributen samen print(rfe.support_) print(rfe.ranking_)
Constructie van het algoritme
Zoals reeds opgemerkt, implementeert Scikit-Learn alle belangrijke machine learning-algoritmen. Laten we er een paar bekijken.Logistieke regressie
Het wordt meestal gebruikt om classificatieproblemen op te lossen (binair), maar classificatie in meerdere klassen is ook toegestaan (de zogenaamde one-vs-all-methode). Het voordeel van dit algoritme is dat we bij de uitvoer van elk object de kans hebben om tot de klasse te behorenImporteer statistieken van sklearn uit sklearn.linear_model import LogisticRegression model = LogisticRegression() model.fit(X, y) print(model) # maak voorspellingen verwacht = y voorspeld = model.predict(X)
Naïeve Bayes
Het is ook een van de bekendste machine learning-algoritmen, waarvan de belangrijkste taak het herstellen van de distributiedichtheid van de trainingsvoorbeeldgegevens is. Vaak geeft deze methode goede kwaliteit bij classificatieproblemen met meerdere klassen.Van sklearn importstatistieken van sklearn.naive_bayes import GaussianNB model = GaussianNB() model.fit(X, y) print(model) # maak voorspellingen verwacht = y voorspeld = model.predict(X) # vat de pasvorm van het model samen print(metrics.classification_report(verwacht, voorspeld)) print(metrics.confusion_matrix(verwacht, voorspeld))
K-dichtstbijzijnde buren
Methode kNN (k-dichtstbijzijnde buren) vaak gebruikt als onderdeel van een complexer classificatie-algoritme. De beoordeling ervan kan bijvoorbeeld worden gebruikt als teken voor een object. En soms levert een simpele knNN op goedgekozen functies uitstekende kwaliteit op. Met de juiste instellingen van parameters (vooral metrieken) geeft het algoritme vaak goede kwaliteit bij regressieproblemenVan sklearn importstatistieken van sklearn.neighbors importeert KNeighborsClassifier # past een k-dichtstbijzijnde buurmodel aan de gegevens toe model = KNeighborsClassifier() model.fit(X, y) print(model) # voorspellingen doen verwacht = y voorspeld = model.predict(X) # vat de pasvorm van het model samen print(metrics.classification_report(verwacht, voorspeld)) print(metrics.confusion_matrix(verwacht, voorspeld))
Beslisbomen
Classificatie- en regressiebomen (CART) vaak gebruikt bij problemen waarbij objecten categorische kenmerken hebben en wordt gebruikt voor regressie- en classificatieproblemen. Bomen zijn zeer geschikt voor classificatie in meerdere klassenImporteer metrische gegevens van sklearn van sklearn.tree en importeer DecisionTreeClassifier # pas een CART-model aan de gegevens aan model = DecisionTreeClassifier() model.fit(X, y) print(model) # voorspellingen doen verwacht = y voorspeld = model.predict(X) # vat de pasvorm van het model samen print(metrics.classification_report(verwacht, voorspeld)) print(metrics.confusion_matrix(verwacht, voorspeld))
Ondersteuning van vectormachine
SVM (ondersteuningsvectormachines) is een van de bekendste machine learning-algoritmen, voornamelijk gebruikt voor classificatietaken. Net als logistische regressie maakt SVM classificatie in meerdere klassen mogelijk met behulp van de één-vs-alles-methode.Van sklearn importstatistieken van sklearn.svm import SVC # pas een SVM-model aan het gegevensmodel aan = SVC() model.fit(X, y) print(model) # maak voorspellingen verwacht = y voorspeld = model.predict(X) # vat de pasvorm van het model samen print(metrics.classification_report(verwacht, voorspeld)) print(metrics.confusion_matrix(verwacht, voorspeld))
Naast classificatie- en regressie-algoritmen beschikt Scikit-Learn over een groot aantal complexere algoritmen, waaronder clustering, evenals geïmplementeerde technieken voor het construeren van composities van algoritmen, waaronder Opzakken En Stimuleren.
Optimalisatie van algoritmeparameters
Een van de moeilijkste stappen bij het bouwen van echt effectieve algoritmen is het kiezen van de juiste parameters. Meestal wordt dit gemakkelijker met ervaring, maar op de een of andere manier moet je overboord gaan. Gelukkig heeft Scikit-Learn al een flink aantal functies voor dit doel geïmplementeerd.Laten we bijvoorbeeld eens kijken naar de selectie van een regularisatieparameter, waarbij we om beurten verschillende waarden uitproberen:
Importeer numpy als np uit sklearn.linear_model importeer Ridge uit sklearn.grid_search importeer GridSearchCV # bereid een reeks alfawaarden voor om te testen alphas = np.array() # maak en pas een nokregressiemodel aan, waarbij elke alfa wordt getest model = Ridge() grid = GridSearchCV(estimator=model, param_grid=dict(alpha=alphas)) grid.fit(X, y) print(grid) # vat de resultaten van de rasterzoekopdracht samen print(raster.beste_score_) print(raster.beste_schatting_.alpha)
Soms is het effectiever om meerdere keren willekeurig een parameter uit een bepaald segment te selecteren, de kwaliteit van het algoritme voor een bepaalde parameter te meten en daardoor de beste te selecteren:
Importeer numpy als np uit scipy.stats importeer uniform als sp_rand uit sklearn.linear_model importeer Ridge uit sklearn.grid_search importeer RandomizedSearchCV # bereid een uniforme verdeling voor om te bemonsteren voor de alfaparameter param_grid = ("alfa": sp_rand()) # maak en pas een nokregressiemodel aan, waarbij willekeurige alfawaarden worden getest model = Ridge() rsearch = RandomizedSearchCV(estimator=model, param_distributions=param_grid, n_iter=100 ) rsearch.fit(X, y) print(rsearch) # vat de resultaten van het zoeken naar willekeurige parameters samen print(rsearch.beste_score_) print(rsearch.best_estimator_.alpha)
We hebben het hele proces van het werken met de Scikit-Learn-bibliotheek bekeken, met uitzondering van het terugsturen van de resultaten naar een bestand, dat als oefening aan de lezer wordt aangeboden, omdat een van de voordelen van Python (en de Scikit- Leerbibliotheek zelf) vergeleken met R is de uitstekende documentatie. In de volgende delen zullen we elk van de secties in detail bekijken, in het bijzonder zullen we iets belangrijks bespreken als Schoonheidstechniek.
Ik hoop echt dat dit materiaal beginnende datawetenschappers zal helpen om zo snel mogelijk machine learning-problemen in de praktijk op te lossen. Tot slot zou ik graag succes en geduld willen wensen aan degenen die net beginnen deel te nemen aan machine learning-wedstrijden!
Python is om verschillende redenen een geweldige programmeertaal om te implementeren. Ten eerste, Python heeft een duidelijke syntaxis. Ten tweede, binnen Python Het is heel gemakkelijk om tekst te manipuleren. Python gebruik groot aantal mensen en organisaties over de hele wereld, dus het evolueert en is goed gedocumenteerd. De taal is platformonafhankelijk en kan volledig gratis worden gebruikt.
Uitvoerbare pseudo-code
Intuïtieve syntaxis Python vaak uitvoerbare pseudo-code genoemd. Installatie Python bevat standaard al gegevenstypen op hoog niveau, zoals lijsten, tupels, woordenboeken, sets, reeksen, enzovoort, die de gebruiker niet langer hoeft te implementeren. Deze gegevenstypen op hoog niveau maken het eenvoudig om abstracte concepten te implementeren. Python Hiermee kunt u programmeren in elke stijl die u kent: objectgeoriënteerd, procedureel, functioneel, enzovoort.
IN Python Tekst is gemakkelijk te verwerken en te manipuleren, waardoor het ideaal is voor het verwerken van niet-numerieke gegevens. Er zijn een aantal bibliotheken waar u gebruik van kunt maken Python om toegang te krijgen tot webpagina's, en intuïtieve tekstmanipulatie maakt het gemakkelijk om gegevens op te halen HTML-code.
Python populair
Programmeertaal Python populair en de vele beschikbare codevoorbeelden maken het gemakkelijk en redelijk snel te leren. Ten tweede betekent populariteit dat er veel modules beschikbaar zijn voor verschillende toepassingen.
Python is een populaire programmeertaal in zowel wetenschappelijke als financiële kringen. Een aantal bibliotheken voor wetenschappelijk computergebruik, zoals SciPy En NumPy Hiermee kunt u bewerkingen uitvoeren op vectoren en matrices. Het maakt de code ook nog leesbaarder en stelt u in staat code te schrijven die op expressies lijkt lineaire algebra. Daarnaast, wetenschappelijke bibliotheken SciPy En NumPy samengesteld met behulp van talen laag niveau (MET En Fortran), wat berekeningen bij het gebruik van deze tools veel sneller maakt.
Wetenschappelijke instrumenten Python werken prima samen met grafisch hulpmiddel genaamd Matplotlib. Matplotlib kan tweedimensionaal bouwen en 3D-afbeeldingen en kan overweg met de meeste soorten constructies die gewoonlijk in de wetenschappelijke gemeenschap worden gebruikt.
Python Het heeft ook een interactieve shell waarmee u elementen van het programma dat wordt ontwikkeld, kunt bekijken en controleren.
Nieuwe module Python, onder de naam Pylab, streeft ernaar om kansen te combineren NumPy, SciPy, En Matplotlib in één omgeving en installatie. Het pakket van vandaag Pylab Het is nog in ontwikkeling, maar heeft een grote toekomst.
Voordelen en nadelen Python
Mensen gebruiken verschillende programmeertalen. Maar voor velen is een programmeertaal gewoon een hulpmiddel om een probleem op te lossen. Python is een taal hoogste niveau, waardoor u meer tijd kunt besteden aan het begrijpen van de gegevens en minder tijd aan het nadenken over hoe ze aan de computer moeten worden gepresenteerd.
Het enige echte nadeel Python is dat het programmacode niet zo snel uitvoert als bijvoorbeeld Java of C. De reden hiervoor is dat Python- geïnterpreteerde taal. Het is echter mogelijk om gecompileerd aan te roepen C-programma's van Python. Hierdoor kun je het beste van verschillende programmeertalen gebruiken en stap voor stap een programma ontwikkelen. Als je met een idee hebt geëxperimenteerd met behulp van Python en besloot dat dit precies is wat je wilt implementeren kant-en-klaar systeem, dan is het eenvoudig om deze overgang van prototype naar werkprogramma. Als het programma is gebouwd volgens modulair principe, dan kun je er eerst voor zorgen dat wat je nodig hebt, werkt in de geschreven code Python, en herschrijf vervolgens, om de snelheid van de code-uitvoering te verbeteren, kritische secties in de taal C. Bibliotheek C++-boost maakt dit eenvoudig te doen. Andere hulpmiddelen zoals Cython En PyPy kunt u de programmaprestaties verbeteren in vergelijking met normaal Python.
Als het idee zelf dat door het programma wordt geïmplementeerd ‘slecht’ is, is het beter om dit te begrijpen door een minimum aan kostbare tijd te besteden aan het schrijven van code. Als het idee werkt, kunt u de prestaties altijd verbeteren door gedeeltelijk kritieke delen van de programmacode te herschrijven.
IN de afgelopen jaren een groot aantal ontwikkelaars, waaronder ontwikkelaars met een academische opleiding, hebben gewerkt aan het verbeteren van de prestaties van de taal en de afzonderlijke pakketten. Daarom is het geen feit dat je code gaat schrijven C, dat sneller zal werken dan wat al beschikbaar is in Python.
Welke versie van Python moet ik gebruiken?
Momenteel worden ze veel gebruikt verschillende versies dit, namelijk 2.x en 3.x. De derde versie is nog in actieve ontwikkeling, de meeste verschillende bibliotheken werken gegarandeerd aan de tweede versie, dus ik gebruik de tweede versie, namelijk 2.7.8, wat ik u adviseer te doen. Er zijn geen fundamentele wijzigingen in de derde versie van deze programmeertaal, dus uw code kan, indien nodig, met minimale wijzigingen in de toekomst, worden overgedragen voor gebruik met de derde versie.
Om te installeren, ga naar de officiële website: www.python.org/downloads/
selecteer uw besturingssysteem en download het installatieprogramma. Ik zal niet in detail op het installatieprobleem ingaan; zoekmachines kunnen je hier gemakkelijk mee helpen.
Ik ben bezig MacO's heb de versie voor mezelf geïnstalleerd Python verschilt van degene die op het systeem is geïnstalleerd en pakketten via de pakketbeheerder Anaconda(er zijn trouwens ook installatiemogelijkheden voor Ramen En Linux).
Onder Ramen, Ze zeggen, Python wordt gespeeld met een tamboerijn, maar ik heb het zelf niet geprobeerd, ik zal niet liegen.
NumPy
![]()
NumPy is het hoofdpakket voor wetenschappelijk computergebruik Python. NumPy is een programmeertaalextensie Python, dat ondersteuning toevoegt voor grote multidimensionale arrays en matrices, samen met een grote bibliotheek met hoogwaardige wiskundige functies om met deze arrays te werken. Voorganger NumPy, plastic zak Numeriek, is oorspronkelijk gemaakt door Jim Haganin met bijdragen van een aantal andere ontwikkelaars. In 2005 creëerde Travis Oliphant NumPy door kenmerken van een concurrerend pakket op te nemen Numarray V Numeriek, waarbij ingrijpende wijzigingen worden aangebracht.
Voor installatie in de Terminal Linux Doen:
sudo apt-get update sudo apt-get installeer python-numpy
sudo apt - update downloaden sudo apt - installeer python - numpy |
Een eenvoudige code die NumPy gebruikt en die een eendimensionale vector van 12 getallen van 1 tot 12 vormt en deze omzet in een driedimensionale matrix:
van numpy import * a = arange(12) a = a.reshape(3,2,2) print a
van numpy import * a = bereik (12 ) een = een. opnieuw vormgeven (3, 2, 2) afdrukken een |
Het resultaat op mijn computer ziet er als volgt uit:
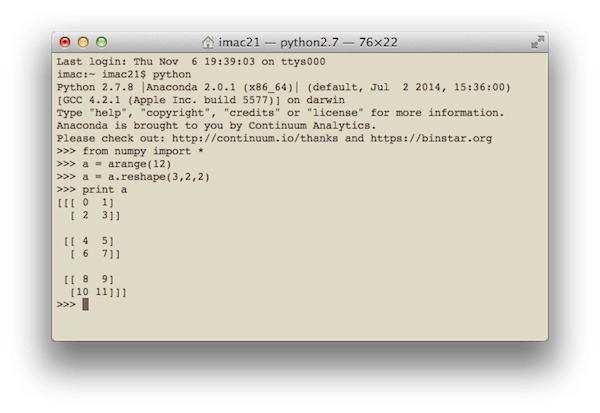
Over het algemeen is de code in de Terminal Python Ik doe het niet zo vaak, behalve om snel iets te berekenen, zoals op een rekenmachine. Ik werk graag binnen IDE PyCharm. Dit is hoe de interface eruit ziet als de bovenstaande code wordt uitgevoerd

SciPy
![]() SciPy is een open-sourcebibliotheek voor wetenschappelijk computergebruik. Voor werk SciPy moet vooraf worden geïnstalleerd NumPy, waarmee u handige en snelle transacties kunt uitvoeren multidimensionale arrays. Bibliotheek SciPy werkt met arrays NumPy, en biedt veel handige en efficiënte computerprocedures, bijvoorbeeld voor numerieke integratie en optimalisatie. NumPy En SciPy eenvoudig te gebruiken en toch krachtig genoeg om een verscheidenheid aan wetenschappelijke en technische berekeningen uit te voeren.
SciPy is een open-sourcebibliotheek voor wetenschappelijk computergebruik. Voor werk SciPy moet vooraf worden geïnstalleerd NumPy, waarmee u handige en snelle transacties kunt uitvoeren multidimensionale arrays. Bibliotheek SciPy werkt met arrays NumPy, en biedt veel handige en efficiënte computerprocedures, bijvoorbeeld voor numerieke integratie en optimalisatie. NumPy En SciPy eenvoudig te gebruiken en toch krachtig genoeg om een verscheidenheid aan wetenschappelijke en technische berekeningen uit te voeren.
Om de bibliotheek te installeren SciPy V Linux, voer in de terminal uit:
sudo apt-get update sudo apt-get installeer python-scipy
sudo apt - update downloaden sudo apt - installeer python - scipy |
Ik zal een voorbeeld geven van code voor het vinden van het extremum van een functie. Het resultaat wordt al weergegeven met behulp van het pakket matplotlib, hieronder besproken.
importeer numpy als np van scipy import special, optimaliseer import matplotlib.pyplot als plt f = lambda x: -special.jv(3, x) sol = optimize.minimize(f, 1.0) x = np.linspace(0, 10, 5000) plt.plot(x, special.jv(3, x), "-", sol.x, -sol.fun, "o") plt.show()
importeer numpy als np van scipy import speciaal, optimaliseren f = lambda X : - speciaal . jv(3,x) sol = optimaliseren. minimaliseren(f, 1,0) x = np. lijnruimte(0, 10, 5000) plt. plot (x , speciaal . jv (3 , x ) , "-" , sol . x , - sol . fun , "o" ) plt. show() |
Het resultaat is een grafiek met het uiterste punt gemarkeerd:

Probeer voor de lol hetzelfde in de taal te implementeren C en vergelijk het aantal regels code dat nodig is om het resultaat te krijgen. Hoeveel lijnen heb je gekregen? Honderd? Vijfhonderd? Tweeduizend?
Panda's
![]() panda's betreft een pakket Python, ontworpen om snelle, flexibele en expressieve datastructuren te bieden die het gemakkelijk maken om op een eenvoudige en intuïtieve manier met "relatieve" of "gelabelde" data te werken. panda's streeft ernaar om de belangrijkste bouwsteen op hoog niveau te worden voor dirigeren Python praktische analyse gegevens verkregen van echte wereld. Bovendien claimt dit pakket het krachtigste en meest flexibele te zijn open source een tool voor data-analyse/verwerking, beschikbaar in elke programmeertaal.
panda's betreft een pakket Python, ontworpen om snelle, flexibele en expressieve datastructuren te bieden die het gemakkelijk maken om op een eenvoudige en intuïtieve manier met "relatieve" of "gelabelde" data te werken. panda's streeft ernaar om de belangrijkste bouwsteen op hoog niveau te worden voor dirigeren Python praktische analyse gegevens verkregen van echte wereld. Bovendien claimt dit pakket het krachtigste en meest flexibele te zijn open source een tool voor data-analyse/verwerking, beschikbaar in elke programmeertaal.
Panda's zeer geschikt voor het werken met verschillende soorten gegevens:
- Gegevens in tabelvorm met kolommen van verschillende typen, zoals in tabellen SQL of Excel.
- Geordende en ongeordende (niet noodzakelijk constante frequentie) tijdreeksgegevens.
- Willekeurige matrixgegevens (homogeen of heterogeen) met gelabelde rijen en kolommen.
- Elke andere vorm van observationele of statistische gegevenssets. Gegevens hebben feitelijk geen label nodig om in een gegevensstructuur te worden geplaatst panda's.
Om het pakket te installeren panda's uitvoeren in de terminal Linux:
sudo apt-get update sudo apt-get installeer python-pandas
sudo apt - update downloaden sudo apt - download python - pandas |
Eenvoudige code die een eendimensionale array omzet in een datastructuur panda's:
importeer panda's als pd importeer numpy als np-waarden = np.array() ser = pd.Series(waarden) print ser
importeer panda's als pd importeer numpy als np waarden = np. array ([ 2.0 , 1.0 , 5.0 , 0.97 , 3.0 , 10.0 , 0.0599 , 8.0 ] ) ser = pd. Serie (waarden) print ser |
Het resultaat zal zijn:

matplotlib
![]()
matplotlib is een bibliotheek grafische constructies voor programmeertaal Python en de uitbreidingen ervan op computationele wiskunde NumPy. De bibliotheek biedt een objectgeoriënteerde API voor het inbedden van grafieken in applicaties met behulp van tools GUI algemeen doel, zoals WxPython, Qt, of GTK+. Er is ook een procedure pylab-interface doet denken MATLAB. SciPy gebruikt matplotlib.
Om de bibliotheek te installeren matpoltlib V Linux voer de volgende opdrachten uit:
sudo apt-get update sudo apt-get install python-matplotlib
sudo apt - update downloaden sudo apt - installeer python - matplotlib |
Voorbeeldcode met behulp van de bibliotheek matplotlib histogrammen maken:
importeer numpy als np importeer matplotlib.mlab als mlab importeer matplotlib.pyplot als plt # voorbeeldgegevens mu = 100 # gemiddelde van distributie sigma = 15 # standaarddeviatie van distributie x = mu + sigma * np.random.randn(10000) num_bins = 50 # het histogram van de gegevens n, bins, patches = plt.hist(x, num_bins, normed=1, facecolor="green", alpha=0.5) # voeg een "best passende" regel toe y = mlab.normpdf(bins , mu, sigma) plt.plot(bins, y, "r--") plt.xlabel("Smarts") plt.ylabel("Waarschijnlijkheid") plt.title(r"Histogram van IQ: $\mu=100 $, $\sigma=15$") # Pas de spatiëring aan om het knippen van het ylabel plt.subplots_adjust(left=0.15) plt.show() te voorkomen
importeer numpy als np importeer matplotlib. mlab als mlab importeer matplotlib. pyplot als plt # voorbeeldgegevens mu = 100 # gemiddelde van verdeling sigma = 15 # standaardafwijking van distributie x = mu + sigma * np. willekeurig. rand (10000) aantal_bins = 50 # het histogram van de gegevens n, bakken, patches = plt. hist (x, aantal_bins, genormeerd = 1, gezichtskleur = "groen", alpha = 0,5) # voeg een "best passende" regel toe y = mlab. normpdf (bins, mu, sigma) plt. plot(bakken, y, "r--") plt. xlabel("Smart's") plt. ylabel("Waarschijnlijkheid") plt. titel (r "Histogram van IQ: $\mu=100$, $\sigma=15$") # Pas de spatiëring aan om het knippen van het ylabel te voorkomen plt. subplots_adjust (links = 0,15) plt. show() |
Het resultaat hiervan is:

Ik vind het heel schattig!
is commandoshell voor interactief computergebruik in meerdere programmeertalen, oorspronkelijk ontwikkeld voor een programmeertaal Python. stelt u in staat de presentatiemogelijkheden uit te breiden, voegt shell-syntaxis, automatisch aanvullen en een uitgebreide opdrachtgeschiedenis toe. biedt momenteel de volgende functies:
- Krachtige interactieve shells (terminaltype en gebaseerd op Qt).
- Browsergebaseerde editor met ondersteuning voor code, tekst, wiskundige uitdrukkingen, ingesloten grafieken en andere presentatiemogelijkheden.
- Ondersteunt interactieve datavisualisatie en gebruik van GUI-tools.
- Flexibele, ingebouwde tolken voor het werken in uw eigen projecten.
- Gebruiksvriendelijke, krachtige parallelle computerhulpmiddelen.
IPython-website:
Om IPython op Linux te installeren, voert u de volgende opdrachten uit in de terminal:
sudo apt-get update sudo pip install ipython
Ik zal een voorbeeld geven van code die bouwt lineaire regressie voor een bepaalde set gegevens die beschikbaar zijn in het pakket scikit-leren:
importeer matplotlib.pyplot als plt importeer numpy als np uit sklearn importeer datasets, linear_model # Laad de diabetesdataset diabetes = datasets.load_diabetes() # Gebruik slechts één functie diabetes_X = diabetes.data[:, np.newaxis] diabetes_X_temp = diabetes_X[: , :, 2] # Splits de gegevens op in trainings-/testsets diabetes_X_train = diabetes_X_temp[:-20] diabetes_X_test = diabetes_X_temp[-20:] # Splits de doelen op in trainings-/testsets diabetes_y_train = diabetes.target[:-20] diabetes_y_test = diabetes.target[-20:] # Maak een lineair regressieobject regr = linear_model.LinearRegression() # Train het model met behulp van de trainingssets regr.fit(diabetes_X_train, diabetes_y_train) # De coëfficiënten print("Coëfficiënten: \n", regr .coef_) # The mean square error print("Residuele som van kwadraten: %.2f" % np.mean((regr.predict(diabetes_X_test) - diabetes_y_test) ** 2)) # Uitgelegde variantiescore: 1 is een perfecte voorspellingsprint ("Variantiescore: %.2f" % regr.score(diabetes_X_test, diabetes_y_test)) # Plotuitvoer plt.scatter(diabetes_X_test, diabetes_y_test, color="black") plt.plot(diabetes_X_test, regr.predict(diabetes_X_test), kleur ="blauw", lijnbreedte=3) plt.xticks()) plt.yticks()) plt.show()
importeer matplotlib. pyplot als plt importeer numpy als np van sklearn importgegevenssets , linear_model # Laad de diabetesgegevensset diabetes=datasets. belasting_diabetes() # Gebruik slechts één functie suikerziekte_X = suikerziekte . gegevens [:, np. nieuwe as] |